条款1:仔细区别 pointers 和 references
- 引用应该被初始化,指针可以不被初始化。
- 不存在指向空值的引用这个事实意味着使用引用的代码效率比使用指针的要高。因为在使用引用之前不需要测试它的合法性。
- 指针与引用的另一个重要的不同是指针可以被重新赋值以指向另一个不同的对象。但是
引用则总是指向在初始化时被指定的对象,以后不能改变。
std::string s1("Nancy");
std::string s2("Clancy");
std::string& rs = s1; // rs引用s1
std::string* ps = &s1; // ps指向s1
rs = s2; // rs仍旧引用s1,但是s1的值现在是"Clancy"
条款2:最好使用C++转型操作符
这四个操作符是:static_cast、const_cast、dynamic_cast、reinterpret_cast。
- const_cast 最普通的用途就是转换掉对象的 const 属性
- dynamic_cast,它被用于安全地沿着类的继承关系向下进行类型转换。这就是说,你能用 dynamic_cast 把指向基类的指针或引用转换成指向其派生类或其兄弟类的指针或引用,而且你能知道转换是否成功。失败的转换将返回空指针(当对指针进行类型转换时)或者抛出异常(当对引用进行类型转换时)。它不能被用于缺乏虚函数的类型上。
- 如你想在没有继承关系的类型中进行转换,你可能想到 static_cast。
- reinterpret_cast,使用这个操作符的类型转换,其 的 转 换 结 果 几 乎 都 是 执 行 期 定 义 ( implementation-defined )。 因此,使用reinterpret_casts 的代码很难移植。reinterpret_casts 的最普通的用途就是在函数指针类型之间进行转换。
double result = static_cast<double>(firstNumber)/secondNumber;
条款3:绝对不要以多态(polymorphically)方式处理数组
在对数组进行传参使用多态时,程序会crash; 因为数组在移位至下一数据时,步长是形参(基类)的size,而不是指针实际指向数据类型(派生类)的size,所以会数组会移位至一个非法的地址 。
#include <iostream>
using namespace std;
class Base
{
public:
virtual void test()
{
cout<<"Base::test()"<<endl;
}
int a;
};
class Derived: public Base
{
public:
void test()
{
cout<<"Derived::test()"<<endl;
}
int b, c;
};
void testArray(Base bArray[], int n)
{
for(int i =0; i<n; i++)
bArray[i].test(); //i = 1时,程序crash; 编译器原先已经假设数组中元素
//与Base对象的大小一致,但是现在数组中每一个对象大小却与Derived一致,
//派生类的长度比基类要长,数组将移动到一个非法位置。
}
int main()
{
Base *p = new Derived[2];
testArray(p, 2);
}条款4:非必要不提供 default construcor
提供无意义的缺省构造函数也会影响类的工作效率。如果成员函数必须测试所有的部分是否都被正确地初始化,那么这些函数的调用者就得为此付出更多的时间。而且还得付出更多的代码,因为这使得可执行文件或库变得更大。它们也得在测试失败的地方放置代码来处理错误。如果一个类的构造函数能够确保所有的部分被正确初始化,所有这些弊病都能够避免。缺省构造函数一般不会提供这种保证,所以在它们可能使类变得没有意义时,尽量去避免使用它们。
class EquipmentPiece {
public:
EquipmentPiece(int IDNumber) {}
virtual ~EquipmentPiece() {}
int a = 1;
float b = 2.0;
};
//避免无用的缺省构造函数
int ID1 = 1, ID2 = 2;
EquipmentPiece bestPieces3[] = { EquipmentPiece(ID1), EquipmentPiece(ID2) };
// 正确,提供了构造函数的参数
// 利用指针数组来代替一个对象数组
typedef EquipmentPiece* PEP; // PEP指针指向一个EquipmentPiece对象
PEP* bestPieces5 = new PEP[10]; // 也正确
// 在指针数组里的每一个指针被重新赋值,以指向一个不同的EquipmentPiece对象
for (int i = 0; i < 10; ++i)
bestPieces5[i] = new EquipmentPiece(ID1);
for (int i = 0; i < 10; ++i)
delete bestPieces5[i];
delete bestPieces5;利用指针数组代替一个对象数组这种方法有两个缺点:第一你必须删除数组里每个指针所指向的对象。如果忘了,就会发生内存泄漏。第二增加了内存分配量,因为正如你需要空间来容纳EquipmentPiece对象一样,你也需要空间来容纳指针.
解决办法:
//分配足够的 raw memory,给一个预备容纳 10 个EquipmentPiece objects 的
//数组使用
void* rawMemory = operator new[](10 * sizeof(EquipmentPiece));
//让 basePiece 指向此块内存,使这块内存被视为一个 EquipmentPiece 数组
EquipmentPiece* bestPieces6 = static_cast<EquipmentPiece*>(rawMemory);
//利用 “placement new”构造这块内存中的 EquipmentPiece objects
for (int i = 0; i < 10; ++i)
new(&bestPieces6[i]) EquipmentPiece(i);
//将 basePieces 中的各个对象,以其构造顺序的相反顺序析构掉
for (int i = 9; i >= 0; --i)
bestPieces6[i].~EquipmentPiece();
// 如果使用普通的数组删除方法,程序的运行将是不可预测的
//因为 basePieces 并非来自 new operator
//释放 raw memory
operator delete[](rawMemory);条款5:对定制的“类型转换函数”保持警觉
单自变量 constructors 是指能够以单一自变量成功调用的 constructors。如此的 constructor 可能声明拥有单一参数,也可能声明拥有多个参数,并且除了第一参数之外都有默认值。
class Name{
public:
Name(const string& s); //可以把string转换成Name
...
};
class Rational{
public:
Rational(int numerator = 0,int denominator = 1);
//可以把 int 转换成 Rational
...
};有两种函数允许编译器进行这些的转换:单参数构造函数(single-argument constructors)和隐式类型转换运算符。
隐式类型转换运算符只是一个样子奇怪的成员函数:operator关键字,其后跟一个类型符号。你不用定义函数的返回类型,因为返回类型就是这个函数的名字。
class Rational {
public:
Rational(int numerator = 0, int denominator = 1) // 转换int到有理数类
{
n = numerator;
d = denominator;
}
operator double() const // 转换Rational类成double类型
{
return static_cast<double>(n) / d;
}
double asDouble() const
{
return static_cast<double>(n) / d;
}
private:
int n, d;
};
//谨慎定义类型转换函数
Rational r(1, 2); // r的值是1/2
double d = 0.5 * r; // 转换r到double,然后做乘法
fprintf(stdout, "value: %f\n", d);
std::cout << r << std::endl; // 应该打印出"1/2",但事与愿违,是一个浮点数,
而不是一个有理数,隐式类型转换的缺点一般来说,越有经验的 C++程序员就越喜欢避开类型转换运算符。例子,在打印Rational类实例时,你忘了为 Rational 对象定义 operator<<。你可能想打印操作将失败,因为没有合适的的 operator<<被调用。但是你错了。当编译器调用 operator<<时,会发现没有这样的函数存在,但是它会试图找到一个合适的隐式类型转换顺序以使得函数调用正常运行。类型转换顺序的规则定义是复杂的,但是在现在这种情况下,编译器会发现它们能调用Rational::operator double 函数来把 r 转换为 double 类型。所以上述代码打印的结果是一个浮点数,而不是一个有理数。这样的函数有时候会引起预料之外的调用。可以用显示的转换函数替代
构造函数用 explicit 声明,如果这样做,编译器会拒绝为了隐式类型转换而调用构造函数。显式类型转换依然合法。

条款6:区别 increament/decrement 操作符的前置(prefix)和后置(postfix)形式
C++规定后缀形式有一个int类型参数,当函数被调用时,编译器传递一个0作为int参数的值给该函数。
前缀形式有时叫做”增加然后取回”, 返回的是引用,效率高
后缀形式叫做”取回然后增加”。返回的是新的值,值和原来的一样。效率低。
class UPInt { // unlimited precision int
public:
// 注意:前缀与后缀形式返回值类型是不同的,前缀形式返回一个引用,
//后缀形式返回一个const类型
UPInt& operator++() // ++前缀
{
//*this += 1; // 增加
i += 1;
return *this; // 取回值
}
const UPInt operator++(int) // ++后缀
{
// 注意:建立了一个显示的临时对象,这个临时对象必须被构造并在最后被析构,
//前缀没有这样的临时对象
UPInt oldValue = *this; // 取回值
// 后缀应该根据它们的前缀形式来实现
++(*this); // 增加
return oldValue; // 返回被取回的值
}
UPInt& operator--() // --前缀
{
i -= 1;
return *this;
}
const UPInt operator--(int) // --后缀
{
UPInt oldValue = *this;
--(*this);
return oldValue;
}
};条款7:千万不要重载&&,|| 和 , 操作符
与 C 一样,C++使用布尔表达式短路求值法(short-circuit evaluation)。这表示一旦确定了布尔表达式的真假值,即使还有部分表达式没有被测试,布尔表达式也停止运算。
条款8:了解各种不同意义的 new 和 delete
new操作符(new operator)和new操作(operator new)的区别:
new操作符就像sizeof一样是语言内置的,你不能改变它的含义,它的功能总是一样的。它要完成的功能分成两部分。第一部分是分配足够的内存以便容纳所需类型的对象。第二部分是它调用构造函数初始化内存中的对象。new操作符总是做这两件事情,你不能以任何方式改变它的行为。你所能改变的是如何为对象分配内存。new操作符调用一个函数来完成必须的内存分配,你能够重写或重载这个函数来改变它的行为。new操作符为分配内存所调用函数的名字是operator new。
函数operator new通常声明:返回值类型是void*,因为这个函数返回一个未经处理(raw)的指针,未初始化的内存。参数size_t确定分配多少内存。你能增加额外的参数重载函数operator new,但是第一个参数类型必须是size_t。就像malloc一样,operator new的职责只是分配内存。它对构造函数一无所知。把operator new返回的未经处理的指针传递给一个对象是new操作符的工作。
void* operator new(size_t size); //声明
void* rawMemory = operator new(sizeof(string)); //这里返回一个指针,指向一块足够容纳一个string对象的内存。取得operator new 返回的内存并将之转换成一个对象,是new operator 的责任

void* rawMemorysingle = operator new(sizeof(EquipmentPiece));
EquipmentPiece* bestPiecesrawMemorysingle =
static_cast<EquipmentPiece*>(rawMemorysingle);
new(bestPiecesrawMemorysingle) EquipmentPiece(1);
bestPiecesrawMemorysingle->~EquipmentPiece();
operator delete(rawMemorysingle);
内存释放动作通常是由函数 operator delete 执行,通常声明如下:
void operator delete(void* memoryToBeDeallocated);
因此 下面这个动作:
delete ps;
会造成编译器产生近似这样的代码;
ps->~string(); //调用对象的 dtoroperator
operator delete(ps); //释放对象所占用的内存
如果只打算处理原始的,未设初值的内存,应该完全回避 new operator
和 delete operator ,改调用 operator new 取得内存并以 operator delete
归还系统
void* buffer = operator new(50*sizeof(char));
...
operator delete(buffer);
这组行为在C++ 中相当于调用 malloc 和 free条款9:利用 destructors 避免泄露资源
用一个对象存储需要被自动释放的资源,然后依靠对象的析构函数来释放资源,这种思想不只是可以运用在指针上,还能用在其它资源的分配和释放上。
资源应该被封装在一个对象里,遵循这个规则,你通常就能够避免在存在异常环境里发生资源泄漏,通过智能指针的方式。
C++确保删除空指针是安全的,所以析构函数在删除指针前不需要检测这些指针是否指向了某些对象。
智能指针:c++ 智能指针auto_ptr (c++98)、shared_ptr(c++ 11)、unique_ptr(c++ 11)、weak_ptr(c++ 11)_c++智能指针作为函数参数-CSDN博客
C++智能指针:std::auto_ptr为什么被废弃 - 知乎 (zhihu.com)
背景:为了防止资源泄漏,请使用RAII对象(资源获得时机便是初始化时机 Resource Acquisition Is Initialization),在构造函数里面获得资源,并在析构函数里面释放资源。
智能指针的作用是:能够处理内存泄漏问题和空悬指针问题。
条款10:在 constructors 内阻止资源泄露
C++仅仅能删除被完全构造的对象(fully constructed objects),只有一个对象的构造函数完全运行完毕,这个对象才被完全地构造。C++拒绝为没有完成构造操作的对象调用析构函数。
具体表现为:在执行构造函数函数体是抛出异常,该类的成员变量已经被完全构造,可以自动删除掉。而本身没有完全构造,其本身的析构函数不会被调用。
如果使用new 的方式创建对象即A *pa = new A();
如果A的构造函数有异常,A没有被完全构造,new 操作失败,返回的指针pa为空,后面使用delete pa;也不会调用 A的析构函数。
解决方法:
将所有可能的 exceptions 捕捉起来,执行某种清理工作,然后重新抛出 exception ,使它继续传播出去即可。

更好的解决方法是同时使用智能指针和初始化列表的方式。

条款11:禁止异常(exceptions)流出 destructors 之外
在有两种情况下会调用析构函数。第一种是在正常情况下删除一个对象,例如对象超出了作用域或被显式地 delete。第二种是异常传递的堆栈辗转开解(stack-unwinding)过程中,由异常处理系统删除一个对象。
异常没有被析构函数捕获住,所以它被传递到析构函数的调用者那里。但是如果析构函数本身的调用就是源自于某些其它异常的抛出,那么 terminate 函数将被自动调用,彻底终止你的程序。
栈展开:
C++ 异常中的栈展开(Stack Unwinding)与对象析构(GeeksForGeeks 译文) - 知乎 (zhihu.com)
"栈展开"指的是在运行时从函数调用栈中移除一条函数的过程。进行栈展开时,被移除的函数的局部变量将以和创建它们时相反的顺序被逐个销毁。
栈展开通常与异常处理相关。 C++ 程序当出现异常时,C++ 会顺着当前的调用栈逐个函数寻找异常处理程序——在这个过程中,不包含相应异常处理程序的函数项都会被从调用栈中移除。因此,只要异常没有被在当前函数中处理(也就是抛出异常的地方和异常处理程序不在一个函数中),就会发生栈展开。栈展开的过程,基本上就是析构所有在运行时创建的自动对象的过程
译注:“自动对象”( automatic objects )指的是在一个代码块中创建的栈变量,其会在代码执行离开该作用域的时候被自动释放。
---------------------------------------------------------------------------------------------------------------------------------
我们知道禁止异常传递到析构函数外有两个原因,第一能够在异常转递的堆栈辗转开解(stack-unwinding)的过程中,防止 terminate 被调用。第二它能帮助确保析构函数总能完成我们希望它做的所有事情。
条款12:了解“抛出一个 exception” 与“传递一个参数” 或 “调用一个虚函数” 之间的差异
你调用函数时,程序的控制权最终还会返回到函数的调用处,但是当你抛出一个异常时,控制权永远不会回到抛出异常的地方。
C++规范要求被作为异常抛出的对象必须被复制。即使被抛出的对象不会被释放,也会进行拷贝操作。抛出异常运行速度比参数传递要慢。
当异常对象被拷贝时,拷贝操作是由对象的拷贝构造函数完成的。该拷贝构造函数是对象的静态类型(static type)所对应类的拷贝构造函数,而不是对象的动态类型(dynamic type)对应类的拷贝构造函数。
class Widget { ... };
class SpecialWidget: public Widget { ... };
void passAndThrowWidget()
{
SpecialWidget localSpecialWidget;
...
Widget& rw = localSpecialWidget; // rw 引用 SpecialWidgetthrow rw;
//它抛出一个类型为 Widget
// 的异常
}
这里抛出的异常对象是 Widget,即使 rw 引用的是一个 SpecialWidget。因为 rw 的静态
类型(static
type)是 Widget,而不是 SpecialWidget。
catch子句中进行异常匹配时可以进行两种类型转换:第一种是派生类与基类间的转换。一个用来捕获基类的catch子句也可以处理派生类类型的异常。这种派生类与基类(inheritance_based)间的异常类型转换可以作用于数值、引用以及指针上。第二种是允许从一个类型化指针(typed pointer)转变成无类型指针(untyped pointer),所以带有const void*指针的catch子句能捕获任何类型的指针类型异常。
catch子句匹配顺序总是取决于它们在程序中出现的顺序。异常传递到 catch 子句中有三种方式:通过指针(by pointer),通过传值(by value)或通过引用(by reference),其中引用最好
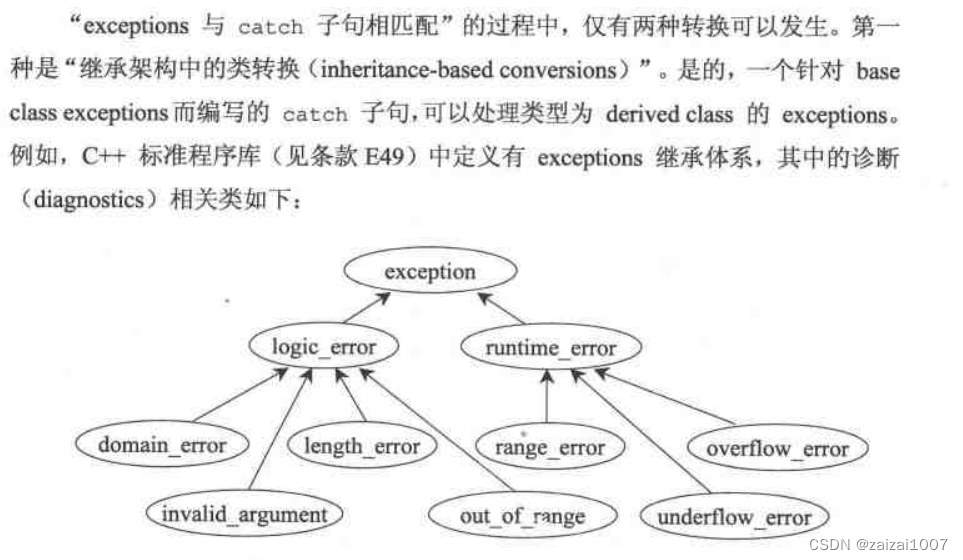



条款13:以 by reference 方式捕捉 exceptions
异常传递到 catch 子句中有三种方式:通过指针(by pointer),通过传值(by value)或通过引用(by reference),其中引用最好.
1..通过指针的方式,对静态异常变量catch中不需要delete,但堆上异常变量需要delete,因此较复杂。而且通过指针捕获异常也不符合C++语言本身的规范。四个标准的异常----bad_alloc(当operator new不能分配足够的内存时被抛出);bad_cast(当dynamic_cast针对一个引用(reference)操作失败时被抛出);bad_typeid(当dynamic_cast对空指针进行操作时被抛出);bad_exception(用于unexpected异常)----都不是指向对象的指针,所以你必须通过值或引用来捕获它们。
2.通过传值时,需要进行拷贝两次(离开作用域一次,catch接收一次),而且它会产生 slicing problem(切割问题),即派生类的异常对象被做为基类异常对象捕获时,那它的派生类行为就被切掉了(sliced off)。这样的sliced对象实际上是一个基类对象:它们没有派生类的数据成员,而且当本准备调用它们的虚拟函数时,系统解析后调用的却是基类对象的函数。
3.异常变量复制一次,避免了上述所有问题
条款14:明智运用 exception specifications
如果一个函数抛出一个不在异常规格范围里的异常,系统在运行时能够检测出这个错误,然后一个特殊函数std::unexpected将被自动地调用(This function is automatically called when a function throws an exception that is not listed in its dynamic-exception-specifier.)。std::unexpected缺省的行为是调用函数std::terminate,而std::terminate缺省的行为是调用函数abort。应避免调用std::unexpected。
1.模板和异常规格不要混合使用.
2.能够避免调用 unexpected 函数的第二个方法是如果在一个函数内调用其它没有异常规
格的函数时应该去除这个函数的异常规格.
C++允许你用其它不同的异常类型替换std::unexpected异常,通过std::set_unexpected
条款15:了解异常处理(exception handling)的成本
1 . 粗略地估计,如果你使用 try 块,代码的尺寸将增加 5%-10%(据说)并且运行速度也同比例减慢。
2 . 不论异常处理的开销有多大我们都得坚持只有必须付出时才付出的原则。为了使你的异常开销最小化,只要可能就尽量采用不支持异常的方法编译程序,把使用 try 块和异常规格限制在你确实需要它们的地方,并且只有在确为异常的情况下(exceptional)才抛出异常.
条款20:谨记 80-20 法则
80-20准则说的是大约20%的代码使用了80%的程序资源;大约20%的代码耗用了大约80%的运行时间;大约20%的代码使用了80%的内存;大约20%的代码执行80%的磁盘访问;80%的维护投入于大约20%的代码上。基本的观点:软件整体的性能取决于代码组成中的一小部分。
条款21:考虑使用 lazy evaluation (缓式评估)
应用领域例子
a. 引用计数。除非你确实需要,不去为任何东西制作拷贝。我们应该是懒惰的,只要可能就共享使用其它值。在一些应用领域,你经常可以这么做。
b. 区别对待读取和写入。
c. Lazy Fetching(懒惰提取)
d. Lazy Expression Evaluation(懒惰表达式计算)
条款18:分期摊还预期的计算成本
在本条款中我提出的建议,即通过 over-eager 方法分摊预期计算的开销,例如 caching和 prefething(预先取出),这并不与我在条款 M17 中提出的有关 lazy evaluation 的建议相矛盾。当你必须支持某些操作而不总需要其结果时,lazy evaluation 是在这种时候使用的用以提高程序效率的技术。当你必须支持某些操作而其结果几乎总是被需要或被不止一次地需要时,over-eager 是在这种时候使用的用以提高程序效率的一种技术。它们所产生的巨大的性能提高证明在这方面花些精力是值得的。
条款19:了解临时对象的来源
C++的所谓临时对象是不可见的--不会在你的源码中出现。只要你产生一个 non-heap object 而没有为它命名,便诞生了一个临时对象。此等匿名对象通常发生于两种情况:
一是当隐式类型转换(implicit type conversions) 被施行起来以求函数调用能够成功
二是当函数返回对象时。
当传送给函数的对象类型与参数类型不匹配时会产生这种情况,仅当通过传值(by value)方式传递对象或传递常量引用(reference-to-const)参数时,才会发生这些类型转换。当传递一个非常量引用(reference-to-non-const)参数对象,就不会发生。C++语言禁止为非常量引用(reference-to-non-const)产生临时对象。
函数返回对象时
最常见和最有效的是返回值优化。
临时对象是有开销的,所以你应该尽可能地去除它们。在任何时候只要见到常量引用(reference-to-const)参数,就存在建立临时对象而绑定在参数上的可能性。在任何时候只要见到函数返回对象,就会有一个临时对象被建立(以后被释放)。
条款20:协助完成“返回值优化(RVO)”
一些函数(operator*也在其中)必须要返回对象。这就是它们的运行方法。
C++规则允许编译器优化不出现的临时对象(temporary objects out of existence)。
从效率的观点来看,你不应该关心函数返回的对象,你仅仅应该关心对象的开销。你所应该关心的是把你的努力引导到寻找减少返回对象的开销上来,而不是去消除对象本身(我们现在认识到这种寻求是无用的)
class Rational20 {
public:
Rational20(int numerator = 0, int denominator = 1) {}
int numerator() const { return 1; }
int denominator() const { return 2; }
};
const Rational20 operator*(const Rational20& lhs, const Rational20& rhs)
{
// 以某种方法返回对象,能让编译器消除临时对象的开销:
//这种技巧是返回constructor argument而不是直接返回对象
return Rational20(lhs.numerator() * rhs.numerator(),
lhs.denominator() * rhs.denominator());
}
int test_item_20()
{
Rational20 a = 10;
Rational20 b(1, 2);
Rational20 c = a * b;
return 0;
}
条款21:利用重载技术(overload)避免隐式类型转换(implicit type conversions)

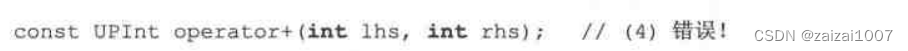
重载操作符必须获得至少一个用户定制类型的自变量
条款22:考虑以操作符复合形式(op=)取代其独身形式(op)

就C++来说,operator+、operator=和operator+=之间没有任何关系,因此如果你想让三个operator同时存在并具有你所期望的关系,就必须自己实现它们。同理,operator-, *, /, 等等也一样。
operator的赋值形式(operator+=)比单独形式(operator+)效率更高。做为一个库程序设计者,应该两者都提供,做为一个应用程序的开发者,在优先考虑性能时你应该考虑考虑用 operator赋值形式代替单独形式。
条款23:考虑使用其他程序库
不同的程序库在效率、可扩展性、移植性、类型安全和其它一些领域上蕴含着不同的设计理念,通过变换使用给予性能更多考虑的程序库,你有时可以大幅度地提供软件的效率。
条款24:了解 virtual functions。multiple inheritance,virtual base classes,runtime type identification 的成本
当调用一个虚拟函数时,被执行的代码必须与调用函数的对象的动态类型相一致;指向对象的指针或引用的类型是不重要的。大多数编译器是使用virtual table和virtual table pointers,通常被分别地称为vtbl和vptr。
一个vtbl通常是一个函数指针数组。(一些编译器使用链表来代替数组,但是基本方法是一样的)在程序中的每个类只要声明了虚函数或继承了虚函数,它就有自己的vtbl,并且类中vtbl的项目是指向虚函数实现体的指针。
你必须为每个包含虚函数的类的virtual table留出空间。类的vtbl的大小与类中声明的虚函数的数量成正比(包括从基类继承的虚函数)。每个类应该只有一个virtual table,所以virtual table所需的空间不会太大,但是如果你有大量的类或者在每个类中有大量的虚函数,你会发现vtbl会占用大量的地址空间。
一些原因导致现在的编译器一般总是忽略虚函数的inline指令。
Virtual table只实现了虚拟函数的一半机制,如果只有这些是没有用的。只有用某种方法指出每个对象对应的vtbl时,它们才能使用。这是virtual table pointer的工作,它来建立这种联系。每个声明了虚函数的对象都带着它,它是一个看不见的数据成员,指向对应类的virtual table。这个看不见的数据成员也称为vptr,被编译器加在对象里,位置只有编译器知道。
虚函数是不能内联的。这是因为”内联”是指”在编译期间用被调用的函数体本身来代替函数调用的指令”,但是虚函数的”虚”是指”直到运行时才能知道要调用的是哪一个函数”。
RTTI(运行时类型识别)能让我们在运行时找到对象和类的有关信息,所以肯定有某个地方存储了这些信息让我们查询。这些信息被存储在类型为type_info的对象里,你能通过使用typeid操作符访问一个类的type_info对象。
RTTI被设计为在类的vtbl基础上实现。
条款25:将 constructor 和 non-member functions 虚化
虚拟构造函数是指能够根据输入给它的数据的不同而建立不同类型的对象。
虚拟拷贝构造函数能返回一个指针,指向调用该函数的对象的新拷贝。类的虚拟拷贝构造函数只是调用它们真正的拷贝构造函数。这个有点像设计模式中的原型模式。
被派生类重定义的虚拟函数不用必须与基类的虚拟函数具有一样的返回类型。如果函数的返回类型是一个指向基类的指针(或一个引用),那么派生类的函数可以返回一个指向基类的派生类的指针(或引用)。
条款26:限制某个class所能产生的对象数量
阻止建立某个类的对象,最容易的方法就是把该类的构造函数声明在类的private域。
第一种办法:定义一个全局函数,同时使其成为类的友元函数(目的就是可以访问该类的私有构造函数)。在全局函数中,创建类对象。
第二种办法:定义一个类的静态函数,在类的静态函数中,创建类对象。
不管是全局函数还是类的静态函数,如果控制只限制生成一个对象,可以创建静态对象,参考设计模式中的单例模式。
条款27:要求(或禁止)对象产生于 heap 之中
1.要求在堆中建立对象(即阻止建立非堆对象)
反向思维:通过限制访问一个类的析构函数或它的构造函数来阻止建立非堆对象。
有2种办法:
1.让析构函数成为 private,让构造函数成为 public。同时定义一个伪析构函数,让其delete this;释放自己类的资源。最好用该办法,因为析构函数就一个,而构造函数有多个。
2.把全部的构造函数都声明为 private。个人理解:这种办法的后续手段应该是定义一个类的静态成员函数,在其函数new 对象。
但两种办法都是问题,就是该类不能派生继承和包容。所以更好的办法是把析构函数private 改成protected,这样就解决继承的问题。把需要包含类的对象修改为包含指向该类的指针(即组合关系改成依赖关系)。


2. 禁止堆对象
禁止用于调用new,利用new操作符总是调用operator new函数这点来达到目的,可以自己声明这个函数,而且你可以把它声明为private。即
private:
void *operator new(size_t size);
void operator delete(void *ptr);
对象做为派生类的基类被实例化(继承)
当operator new 和 operator delete 在基类是 private 的版本。因为 operator new 和 operator delete 是自动继承的,如果 operator new 和 operator delete 没有在派生类中被声明为 public(进行改写,overwrite),它们就会继承基类中 private 的版本。所以要在派生类把 operator new 和 operator delete 声明为public。
条款28:Smart Pointers(智能指针)

条款29:Refference counting(引用计数)
引用计数是这样一个技巧,它允许多个有相同值的对象共享这个值的实现。这个技巧有两个常用动机。第一个是简化跟踪堆中的对象的过程。一旦一个对象通过调用new被分配出来,最要紧的就是记录谁拥有这个对象,因为其所有者----并且只有其所有者----负责对这个对象调用delete。但是,所有权可以被从一个对象传递到另外一个对象(例如通过传递指针型参数)。引用计数可以免除跟踪对象所有权的担子,因为当使用引用计数后,对象自己拥有自己。当没人再使用它时,它自己自动销毁自己。因此,引用计数是个简单的垃圾回收体系。第二个动机是由于一个简单的常识。如果很多对象有相同的值,将这个值存储多次是很无聊的。更好的办法是让所有的对象共享这个值的实现。这么做不但节省内存,而且可以使得程序运行更快,因为不需要构造和析构这个值的拷贝。
实现引用计数不是没有代价的。每个被引用的值带一个引用计数,其大部分操作都需要以某种形式检查或操作引用计数。对象的值需要更多的内存,而我们在处理它们时需要执行更多的代码。引用计数是基于对象通常共享相同的值的假设的优化技巧。如果假设不成立的话,引用计数将比通常的方法使用更多的内存和执行更多的代码。另一方面,如果你的对象确实有具有相同值的趋势,那么引用计数将同时节省时间和空间。
条款30:Proxy classes(替身类,代理类)
可以通过代理类实现二维数组。
可以通过代理类帮助区分通过operator[]进行的是读操作还是写操作。
Proxy类可以完成一些其它方法很难甚至可不能实现的行为。多维数组是一个例子,左值/右值的区分是第二个,限制隐式类型转换是第三个。
同时,proxy类也有缺点。作为函数返回值,proxy对象是临时对象,它们必须被构造和析构。Proxy对象的存在增加了软件的复杂度。从一个处理实际对象的类改换到处理proxy对象的类经常改变了类的语义,因为proxy对象通常表现出的行为与实际对象有些微妙的区别。
之后的看不下去了,大致扫了一下
参考文章:《More Effective C++》笔记_more effective c++ pdf github-CSDN博客
More Effective C++-CSDN博客