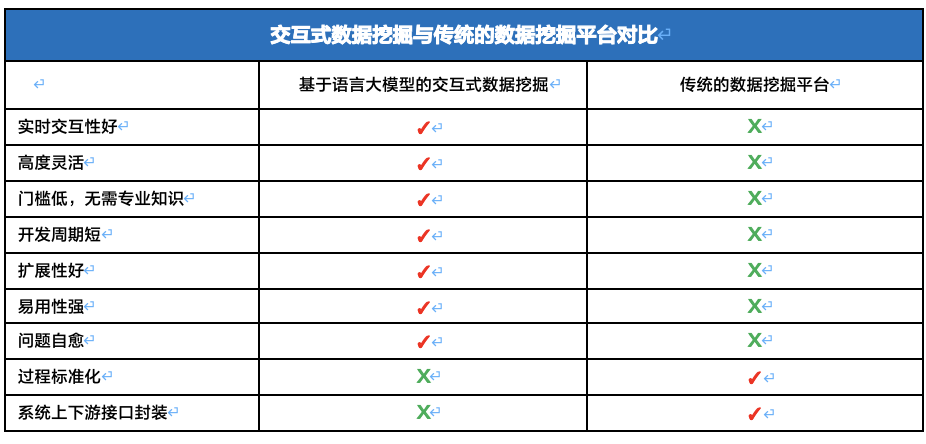
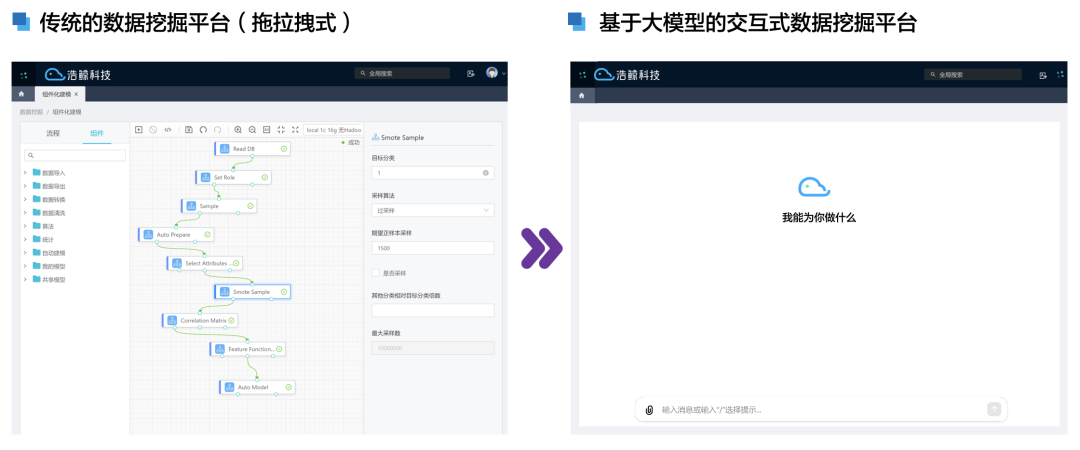
在这个数据驱动的时代,数据挖掘已成为解锁信息宝库的关键。过去,我们依赖传统的拖拉拽方式来建模,这种方式在早期的数据探索中起到了作用,但随着数据量的激增和需求的多样化,它的局限性逐渐显露。
>>>> 首先,操作复杂性
传统方法通常要求用户具备深厚的技术背景,包括对各种工具和编程语言的了解、数据挖掘各个环节的掌握、各个节点参数的设置等。这不仅限制了非技术人员的参与,也使得数据挖掘成为一个时间消耗巨大的任务。
>>>> 其次,灵活性不足
在处理多变的数据类型和复杂的分析需求时,传统方法往往受限于挖掘平台的功能,如果功能不具备或功能不足以满足需求,则需要通过纯代码的方式进行编译。另外,用户需要不断调整和优化数据,以达到理想的模型效果,这一过程既繁琐又耗时。
>>>> 最后,效率低下
从数据准备到模型构建,再到结果解释,整个过程充满了重复和等待。这不仅影响了数据挖掘的效率,也限制了其在快速变化的商业环境中的应用。
而今,随着人工智能技术的飞速发展,一种新的解决方案——用大模型进行数据挖掘,正悄然崛起。类似ChartGPT的大模型,已经日渐成熟,不仅仅是工具的升级换代,它代表着一种全新的思维方式。在大模型的世界里,复杂的数据处理变得触手可及。通过简单的语言指令,我们可以轻松建立和调整数据模型,这不仅使操作变得简便,更重要的是,它打开了一扇通往更高效、更灵活数据处理世界的大门。
本文中,我们将一起探索ChartGPT4.0如何优雅地解决传统方法的痛点,带领我们进入数据挖掘的新纪元。从直观的操作界面到智能化的数据分析,我们将深入了解ChartGPT4.0如何在实际应用中展现其独特的魅力,开启交互式数据挖掘的新篇章。

![]()
Step 1 数据探索
数据概览 数值型变量描述性统计
场景:
-
数据读取:直接上传数据,不对数据内容、格式和结构做任何的描述,要求读取数据
-
数据探索:用一句话需求,要求平台对数据进行探索
-
数据分布:要求平台画图展示某个指标的数据分布
目标:
-
探索平台的自动化能力
-
探索平台对“一句话需求”的理解和执行能力
-
探索平台的数据可视化能力

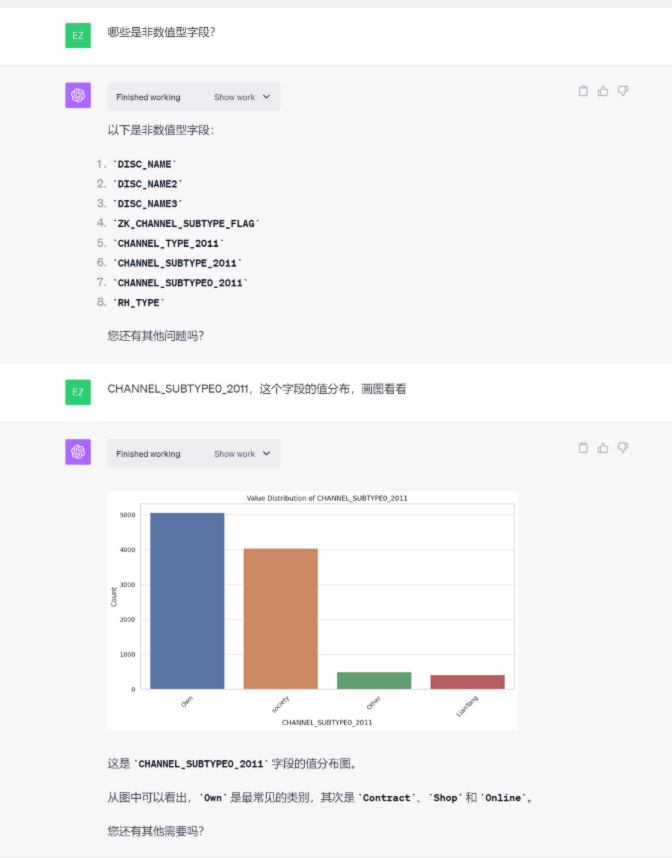
探索与发现:
-
自动化:上传数据后,平台根据数据格式自动读取和解析数据,无需任何指令、参数和说明
-
一句话需求:“请对这份数据进行数据探索”。平台可以精准理解用户的需求,并且根据自身的知识储备,拆解成6类数据探索操作,这六类数据探索操作十分专业
-
专业术语:非数值型数据。平台可以精准理解专业术语,并根据要求执行非数值型数据发现
-
图表能力:字段分布。平台可以精准理解图表需求,并精准的将图表输出。
Step 2 数据预处理
数据清洗(处理缺失值和重复值) 删除字段 WOE编码
场景:
-
处理缺失值:要求平台识别有缺失的字段,并根据平台的自身知识自动处理
-
处理重复值:要求平台识别数据集中的重复行,并根据平台的自身知识自动处理
-
布离散型变量WOE编码:要求平台自行识别离散型变量,并进行WOE编码
目标:
-
探索平台的专业数据处理能力

探索与发现:
-
问题自愈能力:建模过程中出现了运行错误,平台会根据错误提示进行问题自愈处理,无需人工干预,十分智能。
Step 3 特征工程
特征筛选
场景:
-
特征筛选:要求平台根据指定的、较为复杂的(需训练模型)的方式进行特征筛选
-
特征重要性可视化:要求平台识根据特征重要性,可视化TOP n 重要特征
目标:
-
探索平台的复杂指令识别与处理能力

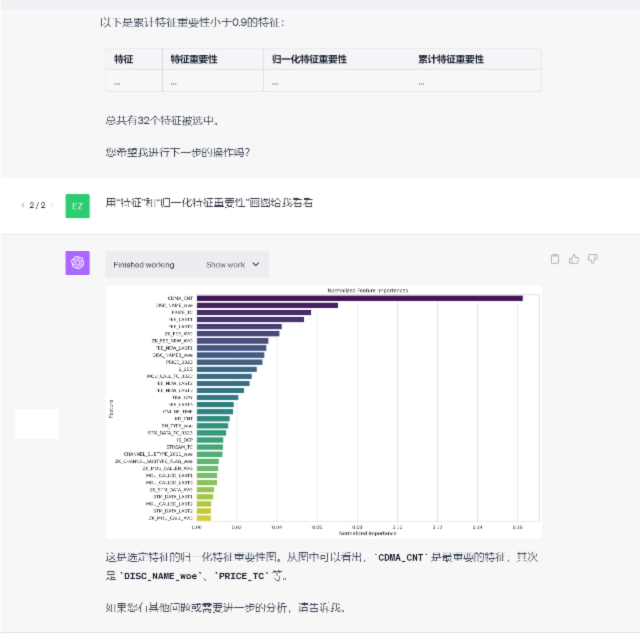
探索与发现:
-
复杂的指令:特征工程环节,我们对平台发布了复杂的作业指令,平台可以准确拆解指令并精准执行,期间遇到运行错误,自愈能力表现优秀。
Step 4 模型训练
数据抽样 模型训练 模型测试
场景:
-
数据抽样:要求平台根据要求进行数据抽样
-
模型训练:要求平台根据指定的算法进行模型训练
目标:
-
探索平台训练模型的专业能力
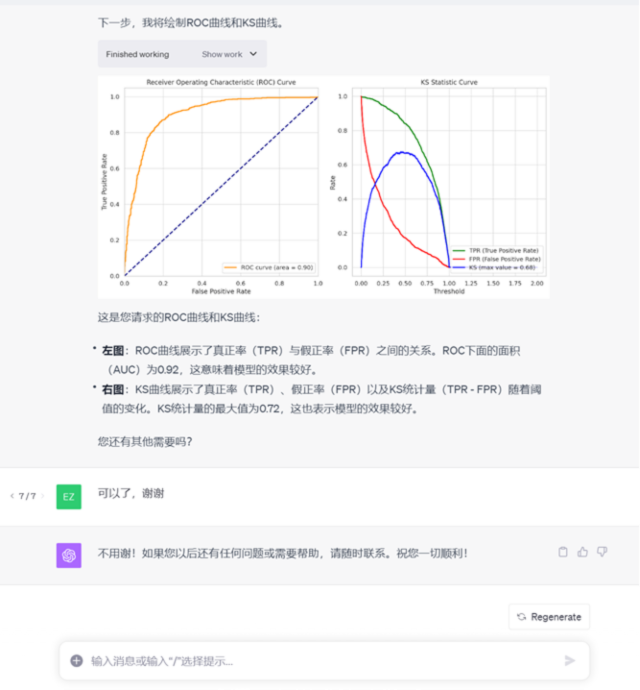
探索与发现:
-
专业性:在训练模型的过程中,平台自动设置最大迭代次数,并在运行后自动识别迭代次数达到最大模型是否收敛,并告知用户,既专业又贴心。
我们已经详细探讨了如何利用先进的大模型技术,如ChartGPT4.0,来极大地提升数据挖掘的效率和深度,见证了这一平台自动化处理数据的能力、对于一般性和专业性指令的高度理解、图表生成的精确性,以及面对错误时的自我修复能力。通过对这些技术进展的剖析,可以预见一个越来越自动化、智能化的未来,在这个未来中,数据的价值将以前所未有的速度被挖掘和实现。
正如本文所展示的,这些进步不仅优化了数据科学家的工作流程,也为业务决策者提供了强有力的支持。交互式数据挖掘使得非技术人员也能够进行复杂的数据分析与挖掘,从而降低了数据科学的门槛。同时,随着平台自愈能力的增强,连续的运营成为可能,进一步保证了数据分析与挖掘任务的稳定性和可靠性。
交互式数据挖掘时代,已经悄然来临。