Kafka 实战教程(二)
1.下载
你可以在 Kafka 官网:http://kafka.apache.org/downloads,下载到最新的 Kafka 安装包,选择下载二进制版本的 tgz 文件,这里我们选择的版本是 kafka_2.11-1.1.0。
2.安装
Kafka 是使用 Scala 编写的运行于 JVM 上的程序,虽然也可以在 Windows 上使用,但是 Kafka 基本上是运行在 Linux 服务器上,因此我们这里也使用 Linux 来开始今天的实战。
首先确保你的机器上安装了 JDK,Kafka 需要 Java 运行环境,以前的 Kafka 还需要 Zookeeper,新版的 Kafka 已经内置了一个 Zookeeper 环境,所以我们可以直接使用。
说是安装,如果只需要进行最简单的尝试的话我们只需要解压到任意目录即可,这里我们将 Kafka 压缩包解压到 /home 目录。
3.配置
在 Kafka 解压目录下有一个 config 文件夹,里面放置的是我们的配置文件。
-
server.properties kafka:服务器的配置,此配置文件用来配置 Kafka 服务器,目前仅介绍几个最基础的配置。broker.id:申明当前 Kafka 服务器在集群中的唯一 ID,需配置为integer,并且集群中的每一个 Kafka 服务器的id都应是唯一的,我们这里采用默认配置即可。listeners:申明此 Kafka 服务器需要监听的端口号,如果是在本机上跑虚拟机运行可以不用配置本项,默认会使用localhost的地址,如果是在远程服务器上运行则必须配置,例如:listeners=PLAINTEXT://192.168.180.128:9092,并确保服务器的 9092 9092 9092 端口能够访问。zookeeper.connect:申明 Kafka 所连接的 Zookeeper 的地址 ,需配置为 Zookeeper 的地址,由于本次使用的是 Kafka 高版本中自带 Zookeeper,使用默认配置即可zookeeper.connect=localhost:2181。
当我们有多个应用,在不同的应用中都使用 Zookeeper,都使用默认的 zk 端口的话,就会
2181
2181
2181 端口冲突。我们可以设置自己的端口号,在 config 文件夹下 zookeeper.properties 文件中修改为 clientPort=2185,也就是 zk 开放接口为
2185
2185
2185。
同时修改 Kafka 的接入端口,server.properties 文件中修改为 zookeeper.connect=localhost:2185。这样我们就成功修改了 Kafka 里面的端口号。
4.运行
4.1 启动 Zookeeper
cd 进入 kafka 解压目录,输入如下命令:
bin/zookeeper-server-start.sh config/zookeeper.properties
启动 zookeeper 成功后,会看到如下输出:

4.2 启动 Kafka
cd 进入 kafka 解压目录,输入如下命令:
bin/kafka-server-start.sh config/server.properties
启动 kafka 成功后,会看到如下输出:

5.第一个消息
5.1 创建一个 Topic
Kafka 通过 Topic 对同一类的数据进行管理,同一类的数据使用同一个 Topic 可以在处理数据时更加的便捷。
在 kafka 解压目录打开终端,输入以下命令,创建一个名为 test 的 Topic。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test

在创建 Topic 后,可以通过输入以下命令,来查看已经创建的 Topic。
bin/kafka-topics.sh --list --zookeeper localhost:2181
5.2 创建一个消息消费者
在 kafka 解压目录打开终端,输入以下命令:
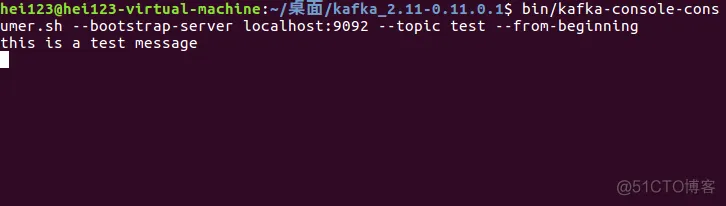
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
可以创建一个用于消费 Topic 为 test 的消费者。

消费者创建完成之后,因为还没有发送任何数据,因此这里在执行后没有打印出任何数据。不过别着急,不要关闭这个终端,打开一个新的终端,接下来我们创建第一个消息生产者。
5.3 创建一个消息生产者
在 kafka 解压目录打开一个新的终端,输入以下命令:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
在执行完毕后会进入编辑器页面。
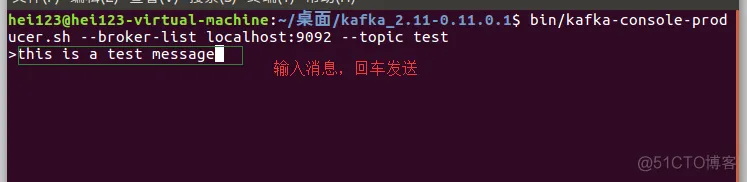
在发送完消息之后,可以回到我们的消息消费者终端中,可以看到,终端中已经打印出了我们刚才发送的消息。