声明
非完全原创,大部分内容来自于学习其他人的理论。如果有侵权,请联系我,可以立即删除掉。
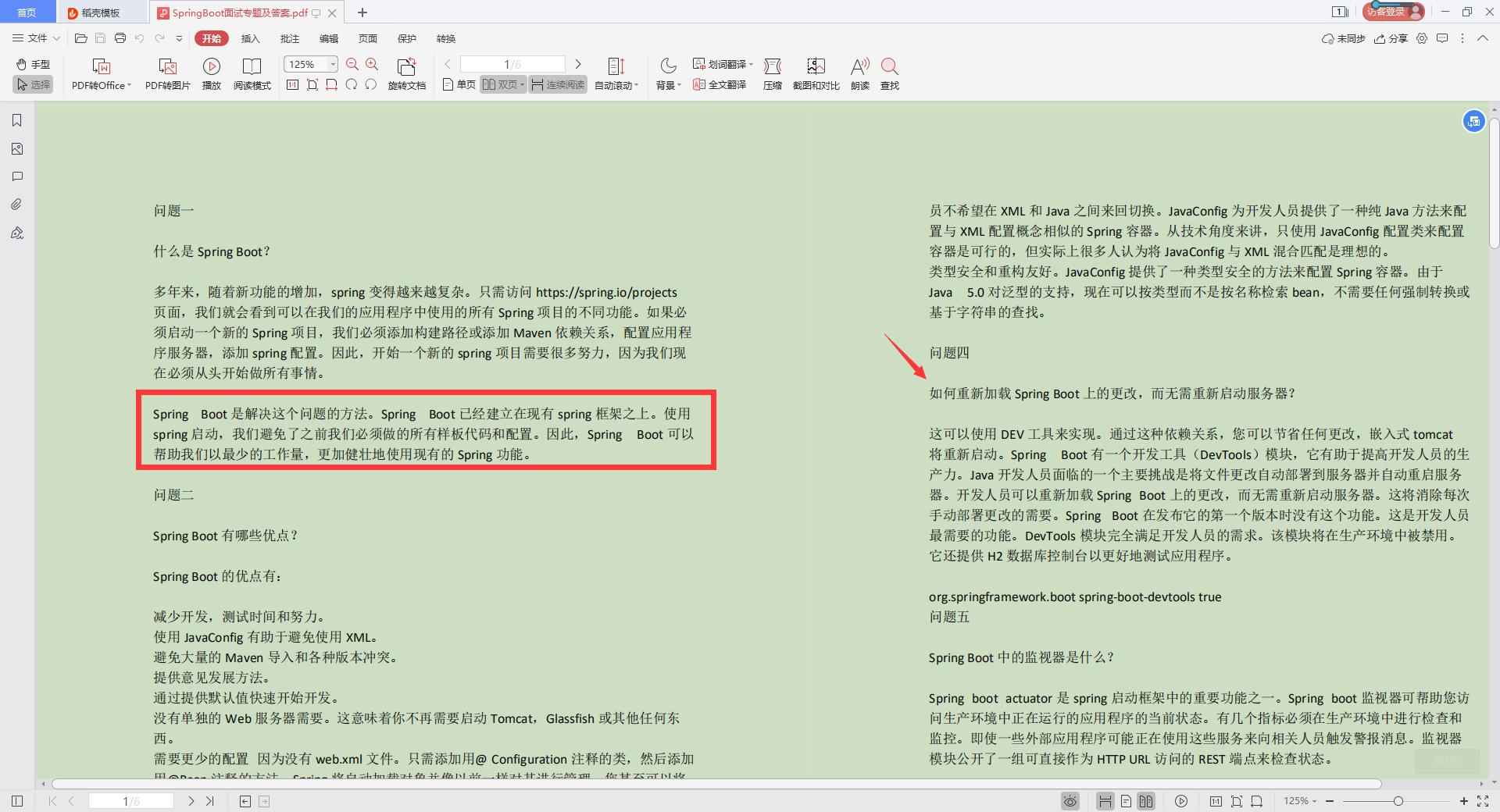
Linux进程的内存使用

CPU对内存的访问
- CPU 上有个Memory Management Unit(MMU) 单元
- CPU 把虚拟地址给MMU,MMU 去物理内存中查询页表,得到实际的物理地址
- CPU 维护一份缓存Translation Lookaside Buffer(TLB),缓存虚拟地址和物理地址的映射关系

进程切换开销
直接开销
- 切换页表全局目录(PGD)
- 切换内核态堆栈
- 切换硬件上下文(进程恢复前,必须装入寄存器的数据统称为硬件上下文)
- 刷新TLB
- 系统调度器的代码执行
间接开销
- CPU 缓存失效导致的进程需要到内存直接访问的IO 操作变多
线程切换开销
• 线程本质上只是一批共享资源的进程,线程切换本质上依然需要内核进行进程切换
• 一组线程因为共享内存资源,因此一个进程的所有线程共享虚拟地址空间,线程切换相比进程切换,主要节省了虚拟地址空间的切换
用户线程
无需内核帮助,应用程序在用户空间创建的可执行单元,创建销毁完全在用户态完成。

Goroutine
Go 语言基于GMP 模型实现用户态线程
• G:表示goroutine,每个goroutine 都有自己的栈空间,定时器,初始化的栈空间在2k 左右,空间会随着需求增长。
• M:抽象化代表内核线程,记录内核线程栈信息,当goroutine 调度到线程时,使用该goroutine 自己的栈信息。
• P:代表调度器,负责调度goroutine,维护一个本地goroutine 队列,M 从P 上获得goroutine 并执行,同时还负责部分内存的管理。
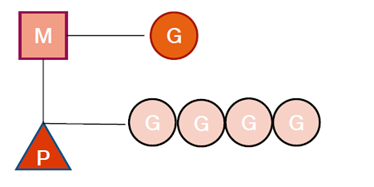
GMP对应关系

GMP模型细节

G的状态转换图

G 所处的位置
• 进程都有一个全局的G 队列
• 每个P 拥有自己的本地执行队列
• 有不在运行队列中的G
- 处于channel 阻塞态的G 被放在sudog
- 脱离P 绑定在M 上的G,如系统调用
- 为了复用,执行结束进入P 的gFree 列表中的G
Goroutine 创建过程
获取或者创建新的Goroutine 结构体
- 从处理器的gFree 列表中查找空闲的Goroutine
- 如果不存在空闲的Goroutine,会通过runtime.malg 创建一个栈大小足够的新结构体
• 将函数传入的参数移到Goroutine 的栈上
• 更新Goroutine 调度相关的属性,更新状态为_Grunnable
• 返回的Goroutine 会存储到全局变量allgs 中
将Goroutine 放到运行队列上
• Goroutine 设置到处理器的runnext 作为下一个处理器执行的任务
• 当处理器的本地运行队列已经没有剩余空间时,就会把本地队列中的一部分Goroutine 和待加入的Goroutine通过runtime.runqputslow 添加到调度器持有的全局运行队列上
调度器行为
• 为了保证公平,当全局运行队列中有待执行的Goroutine 时,通过schedtick 保证有一定几率(1/61)会从全局的运行队列中查找对应的Goroutine
• 从处理器本地的运行队列中查找待执行的Goroutine
• 如果前两种方法都没有找到Goroutine,会通过runtime.findrunnable 进行阻塞地查找Goroutine
- 从本地运行队列、全局运行队列中查找
- 从网络轮询器中查找是否有Goroutine 等待运行
- 通过runtime.runqsteal 尝试从其他随机的处理器中窃取待运行的Goroutine