开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,(共2150人左右 1 + 2 + 3 + 4 +5) 新人直接分配到5群,另欢迎 OpenGauss 的技术人员加入。
最近写了一篇揭露人性的文章,被下架了,看来是写对了,的确是不适宜公开传阅了,我一点都不惊讶,很多事情只可意会,不能宣之于口.

话归正处,咱们今天继续说PostgreSQL ,对于PostgreSQL中的重要的功能实际上都是尤其是内部的一些功能本身,都是围绕着POSTGRESQL 的原理,MVCC 中UNDO 实现的方式而来的,如果你一直埋怨PG 不能按你心愿,那么你一定是没有理解他本身的设计原理。
今天要说的就是基于PG的原理的 HOT UPDATE 和 FillFactor ,如果这两个理解了,并且对于fillfactor做好了,那么对于使用PG 会有良好的适用性。
HOT UPDATE,对于PG来说这是一个重要的功能,在我们理解来,表和索引是一体的,在更新表的数据的同时,索引里面的数据也会更新,当然如果要启动 heap only tuple 的这个功能,是要特定的条件的。
1 更新的数据必须与原来的这行数据在一个页面内,这是启动数据更新heap Only Tuple 的前提。
2 要完成这个前提,对于POSTGRESQL的表设计中的 fillfactor要有认知和好的设计,这可和 mysql 那样的数据库的简单实用的思路不一样了。
下面我们说说根因,
为了实现高并发,PG实用了多版本并非控制,来存储行,对于UPDATE来说有一个问题,更新行需要不是在原有的位置来修改,而是插入新的行,这就需要为每个更新的行添加新的索引条目,那么必然索引中的对于原有行的指向是要变动的,这就会导致这个操作很复杂,导致我们的操作变得比较“贵”。
为了解决这个问题,提出了HOT heap-Only-Tuples , 通过这样的方式来减少在进行数据行的更新后,新的索引行的产生情况。我这里大致画一个简图来说明这样操作后的好处是什么。
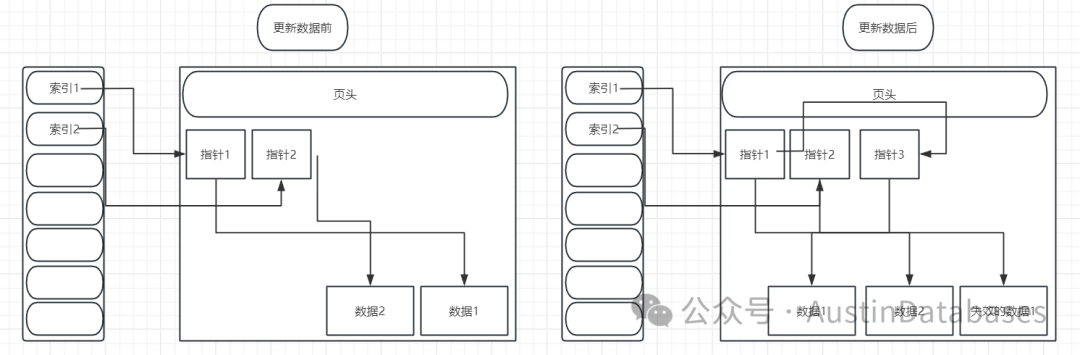
为了大家看清楚,将上图拆分在进行粘贴
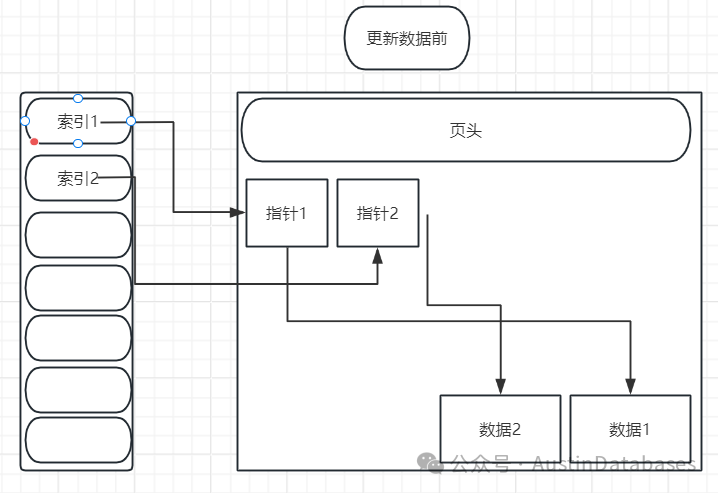
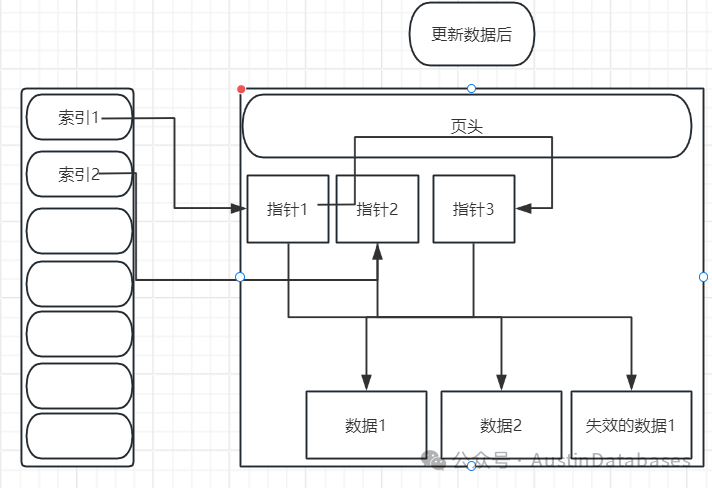
从上图我们可以很清楚的看到,图一为更新数据前的,图2为更新数据后,因为更新数据后,会直接插入一行,所以第二张图就会将原有的数据行的位置进行标记,然后在新的位置插入更新后的数据行,这里可以注意,因为使用了 HOT,所以索引1 的指针还是没有变化而,变化的仅仅是指针1 将自己的指针指向了指针3.
以前读取数据是 索引1 ---指针1---数据 1, 现在的读取的方式是索引1--指针1--指针3--数据1.
因这样的方式仅仅变动的是业内的指针重定向,所以这个样的方式相对于修改索引1的指针指向指针3 要方便的多,节省了大量的数据处理的资源。
那么说到这里,如果要满足这样的操作必须保证更新后的行和被更新的行在一个页面内,才可以进行此操作,如果是下面的情况那么HOT无法进行工作的,下图展示的是由于原有更新行的数据并为插入到原有的数据页面中,而是插入到了新的页面中,所以索引必须指向新的位置,而不能再指向原有的页面了。
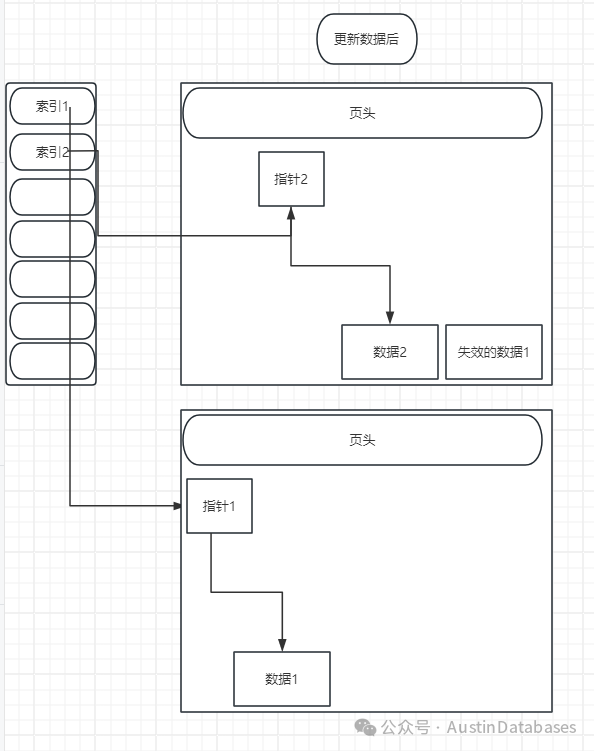
所以说到这里,要保证一个页面可以容纳UPDATE后,还写入本页的插入的数据的方法里面,必须有保证原有页面内的空间有冗余,这也就谈到我们说的第二个问题 fillfactor. 填充率。
对的填充率,填充率在POSTGRESQL中尤其的重要,对于一个在PG里面经常被UPDATE的表,fillfactor 在首次填充率一般都不建议超过85%。当然这样操作后的后果是,数据页面在第一次的插入后,会保留15%的空间,者就导致这样的数据页面比100%填充的页面要浪费15%的空间。
那么这里,空间换时间,时间换空间的道理,在POSTGRESQL HOT, Fillfactor 里面又再次的应验了。
postgres=# \c test
You are now connected to database "test" as user "postgres".
test=# SELECT
relname AS table_name,
seq_scan AS sequential_scans,
idx_scan AS index_scans,
n_tup_ins AS inserts,
n_tup_upd AS updates,
n_tup_hot_upd AS hot_updates
FROM
pg_stat_user_tables
ORDER BY
hot_updates DESC;
table_name | sequential_scans | index_scans | inserts | updates | hot_updates
------------+------------------+-------------+---------+---------+-------------
test_data | 14 | 4 | 16 | 6 | 6
test | 0 | | 0 | 0 | 0
(2 rows)最后是如何你来查看你的表中设置的fillfactor是对的,用上面的语句来去查看你的表中 hot_updates的次数,和UDPATE的次数的对比,也可以算一个百分比,即可。
ALTER TABLE your_table SET (FILLFACTOR = 80);
修改一个表的填充率也很简单,直接对于这个表即刻进行填充率的修改,当然这仅仅是对这个表中新加的页面生效。
Adjournment