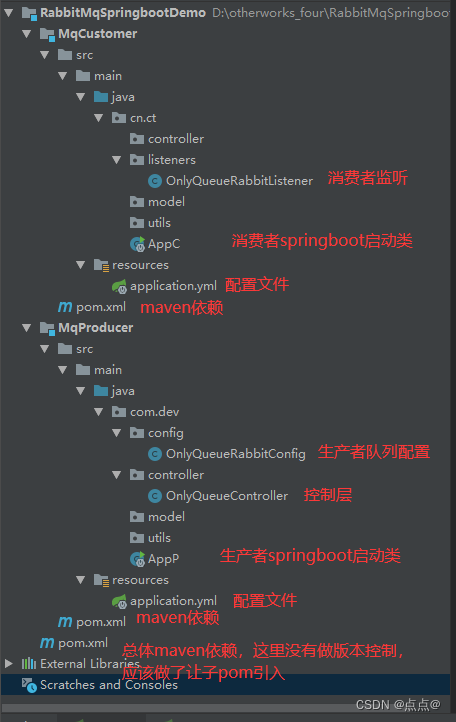
本章的内容描述从源代码发布安装PostgreSQL(如果你安装的是打包好的版本如RPM或Debian包,那么请略过这一章并且阅读打包者的指导)。
一、简单版
./configure
make
su
make install
adduser postgres
mkdir /usr/local/pgsql/data
chown postgres /usr/local/pgsql/data
su - postgres
/usr/local/pgsql/bin/initdb -D /usr/local/pgsql/data
/usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data >logfile 2>&1 &
/usr/local/pgsql/bin/createdb test
/usr/local/pgsql/bin/psql test本章剩余部分都是完全版。
二、要求
一般说来,一个现代的与 Unix 兼容的平台应该就能运行PostgreSQL。 到发布为止已经明确测试过的平台的列表在 下面第六节中列出。在发布的doc子目录里面有许多平台相关的 FAQ文档,如果你碰到问题你可能会需要参考它们。
编译PostgreSQL需要下列软件包:
make --version
-
你需要一个ISO/ANSI C 编译器(至少是 C89兼容的)。我们推荐使用最近版本的GCC,不过,众所周知的是PostgreSQL可以利用许多不同厂商的不同编译器进行编译。
-
除了gzip和bzip2之外,我们还需要tar来解包源代码发布。
-
默认的时候将使用zlib压缩库。 如果你不想使用它,那么你必须给
configure声明--without-zlib选项。使用这个选项关闭了在pg_dump和pg_restore中对压缩归档的支持。
下列包是可选的。在默认配置的时候并不要求它们,但是如果打开了一些编译选项之后就需要它们了,如下文所解释的:
-
要编译服务器端编程语言PL/Perl,你需要一个完整的 Perl安装,包括
libperl库和头文件。 所需的最低版本是Perl 5.8.3。 因为PL/Perl是一个共享库,libperl库在大多数平台上也必须是一个共享库。最近的版本的 Perl好像已经默认这样做了,但是早先的版本可不是 这样的,而且这总是一种在站点上安装 Perl 的选择。如果选择了编译 PL/Perl但是它却找不到一个共享的libperl,那么configure将会失败。 在这种情况下,你将不得不重新手工编译并且安装Perl 以便能编译PL/Perl。在 Perl的配置处理过程中,需要一个共享库。如果你想更多地使用PL/Perl, 你应当保证Perl安装在编译时启用了
usemultiplicity选项(perl -V将会显示是否是这样)。 -
要编译PL/Python服务器端编程语言, 你需要一个Python的安装,包括头文件和distutils模块。最低的版本要求是Python 2.4。如果是版本3.1或更高版本,则支持Python 3。
-
如果你想编译PL/Tcl过程语言, 你当然需要安装Tcl,要求的最低版本是 Tcl 8.4。
-
要打开本地语言支持(NLS),也就是说, 用英语之外的语言显示程序的消息,你需要一个Gettext API的实现。有些操作系统内置了这些(例如Linux、NetBSD、Solaris), 对于其它系统,你可以从gettext - GNU Project - Free Software Foundation下载一个额外的包。如果你在使用GNU C 库里面的Gettext实现, 那么你就额外需要GNU Gettext包,因为我们需要里面的几个工具程序。对于任何其它的实现,你应该不需要它。
-
如果您想支持加密的客户端连接,则需要OpenSSL。最低要求的版本是0.9.8。
-
如果你想支持使用Kerberos、OpenLDAP和/或PAM服务的认证,那你需要相应的包。
-
要编译PostgreSQL文档,有一些独立的要求集,请见 J.2 。
如果你正从Git树而不是使用发布的源代码包进行编译,或者你想做服务器端开发, 那么你还需要下面的包:
-
如果你需要从 Git 检出中编译,或者你修改了实际的扫描器和分析器的定义文件, 那么你需要 GNU Flex和Bison。 如果你需要它们,那么确保自己拿到的是Flex 2.5.31 或更新的版本, 以及Bison 1.875 或者更新的版本。不能使用其他lex和yacc程序。
-
如果需要从 Git 检出中编译,或者你修改了任何使用 Perl 脚本的编译步骤的输入文件,那么你需要Perl 5.8.3或以后的版本。如果你在 Windows 上编译,你在任何情况下都需要Perl。运行一些测试套件时也需要Perl。
如果你需要获取GNU包,你可以在你的本地GNU镜像站点 (看看 GNU Mirror List- GNU Project - Free Software Foundation或ftp://ftp.gnu.org/gnu/找到它们。
还要检查一下你是否有足够的磁盘空间。你将大概需要近 100MB 用于存放编译过程中的源码树和大约 20 MB 用于安装目录。 一个空数据库集簇大概需要 35 MB。一个数据库所占的空间大约是存储同样数据的平面文件所占空间的五倍。如果你要运行回归测试,还临时需要额外的 150MB。请用df命令检查剩余磁盘空间。
三、获取源码
PostgreSQL 11.2 源代码可以从我们的官方网站 PostgreSQL: Downloads的下载区中获得。你将得到一个名为postgresql-11.2.tar.gz或postgresql-11.2.tar.bz2的文件。在你获取文件之后,解压缩它:
gunzip postgresql-11.2.tar.gz
tar xf postgresql-11.2.tar如果你得到的是.bz2文件,请用bunzip2代替gunzip)。这样将在当前目录创建一个目录postgresql-11.2, 里面是PostgreSQL源代码。 进入这个目录完成安装过程的其他步骤。
你也可以直接从版本控制库中获得源代码。
四、安装过程
4.1. 配置
安装过程的第一步就是为你的系统配置源代码树并选择你喜欢的选项。这个工作是通过运行configure脚本实现的,对于默认安装,你只需要简单地输入:
./configure该脚本将运行一些测试来决定一些系统相关的变量, 并检测你的操作系统的特殊设置,并且最后将在编译树中创建一些文件以记录它找到了什么。如果你想保持编译目录的独立,你也可以在一个源码树之外的目录中运行configure 。这个过程也被称为一个VPATH编译。做法如下:
mkdir build_dir
cd build_dir
/path/to/source/tree/configure [options go here]
make默认设置将编译服务器和辅助程序,还有只需要 C 编译器的所有客户端程序和接口。默认时所有文件都将安装到/usr/local/pgsql。
你可以通过给出下面的configure命令行选项中的一个或更多的选项来自定义编译和安装过程:
--prefix=PREFIX
把所有文件装在目录PREFIX中而不是/usr/local/pgsql中。 实际的文件会安装到数个子目录中;没有一个文件会直接安装到PREFIX目录里。
如果你有特殊需要,你还可以用下面的选项自定义不同的子目录的位置。 不过,如果你把这些设置保留默认,那么安装将是可重定位的,意思是你可以在安装过后移动目录(man和doc位置不受此影响)。
对于可重定位的安装,你可能需要使用configure的--disable-rpath选项。 还有,你需要告诉操作系统如何找到共享库。
--exec-prefix=EXEC-PREFIX
你可以把体系相关的文件安装到一个不同的前缀下(EXEC-PREFIX),而不是PREFIX中设置的地方。 这样做可以比较方便地在不同主机之间共享体系相关的文件。 如果你省略这些,那么EXEC-PREFIX就会被设置为等于 PREFIX并且体系相关和体系无关的文件都会安装到同一棵目录树下,这也可能是你想要的。
--bindir=DIRECTORY
为可执行程序指定目录。默认是EXEC-PREFIX/bin/usr/local/pgsql/bin。
--sysconfdir=DIRECTORY
用于各种各样配置文件的目录,默认为PREFIX/etc
--libdir=DIRECTORY
设置安装库和动态装载模块的目录。默认是EXEC-PREFIX/lib
--includedir=DIRECTORY
C 和 C++ 头文件的目录。默认是PREFIX/include
--datarootdir=DIRECTORY
设置多种只读数据文件的根目录。这只为后面的某些选项设置默认值。默认值为PREFIX/share
--datadir=DIRECTORY
设置被安装的程序使用的只读数据文件的目录。默认值为DATAROOTDIR
--localedir=DIRECTORY
设置安装区域数据的目录,特别是消息翻译目录文件。默认值为DATAROOTDIR/locale
--mandir=DIRECTORY
PostgreSQL自带的手册页将安装到这个目录,它们被安装在相应的man子目录里。 默认是xDATAROOTDIR/man
--docdir=DIRECTORY
设置安装文档文件的根目录,“man”页不包含在内。这只为后续选项设置默认值。这个选项的默认值为DATAROOTDIR/doc/postgresql
--htmldir=DIRECTORY
PostgreSQL的HTML格式的文档将被安装在这个目录中。默认值为DATAROOTDIR
注意:
为了让PostgreSQL能够安装在一些共享的安装位置(例如/usr/local/include), 同时又不至于和系统其它部分产生名字空间干扰,我们特别做了一些处理。 首先,安装脚本会自动给datadir、sysconfdir和docdir后面附加上“/postgresql”字符串, 除非展开的完整路径名已经包含字符串“postgres”或者“pgsql”。 例如,如果你选择/usr/local作为前缀, 那么文档将安装在/usr/local/doc/postgresql,但如果前缀是/opt/postgres, 那么它将被放到/opt/postgres/doc。客户接口的公共 C 头文件安装到了includedir,并且是名字空间无关的。内部的头文件和服务器头文件都安装在includedir下的私有目录中。参考每种接口的文档获取关于如何访问头文件的信息。最后,如果合适,那么也会在libdir下创建一个私有的子目录用于动态可装载的模块。
--with-extra-version=STRING
把STRING追加到 PostgreSQL 版本号。例如,你可以使用它来标记从未发布的 Git 快照或者包含定制补丁(带有一个如git describe标识符之类的额外版本号或者一个分发包发行号)创建的二进制文件。
--with-includes=DIRECTORIES
DIRECTORIES是一个冒号分隔的目录列表,这些目录将被加入编译器的头文件搜索列表中。 如果你有一些可选的包(例如 GNU Readline)安装在非标准位置, 你就必须使用这个选项,以及可能还有相应的 --with-libraries选项。
例子:--with-includes=/opt/gnu/include:/usr/sup/include.
--with-libraries=DIRECTORIES
DIRECTORIES是一个冒号分隔的目录列表,这些目录是用于查找库文件的。 如果你有一些包安装在非标准位置,你可能就需要使用这个选项(以及对应的--with-includes选项)。
例子:--with-libraries=/opt/gnu/lib:/usr/sup/lib.
--enable-nls[=LANGUAGES]
打开本地语言支持(NLS),也就是以非英文显示程序消息的能力。LANGUAGES是一个空格分隔的语言代码列表, 表示你想支持的语言。例如--enable-nls='de fr' (你提供的列表和实际支持的列表之间的交集将会自动计算出来)。如果你没有声明一个列表,那么就会安装所有可用的翻译。
要使用这个选项,你需要一个Gettext API 的实现。见上文。
--with-pgport=NUMBER
把NUMBER设置为服务器和客户端的默认端口。默认是 5432。 这个端口可以在以后修改,不过如果你在这里声明,那么服务器和客户端将有相同的编译好了的默认值。这样会非常方便些。 通常选取一个非默认值的理由是你企图在同一台机器上运行多个PostgreSQL服务器。
--with-perl
制作PL/Perl服务器端编程语言。
--with-python
制作PL/Python服务器端编程语言。
--with-tcl
制作PL/Tcl服务器编程语言。
--with-tclconfig=DIRECTORY
Tcl 安装文件tclConfig.sh,其中里面包含编译与 Tcl 接口的模块的配置信息。该文件通常可以自动地在一个众所周知的位置找到,但是如果你需要一个不同版本的 Tcl,你也可以指定可以找到它的目录。
--with-gssapi
编译 GSSAPI 认证支持。在很多系统上,GSSAPI(通常是 Kerberos 安装的一部分)系统不会被安装在默认搜索位置(例如/usr/include、/usr/lib),因此你必须使用选项--with-includes和--with-libraries来配合该选项。configure将会检查所需的头文件和库以确保你的 GSSAPI 安装足以让配置继续下去。
--with-krb-srvnam=NAME
默认的 Kerberos 服务主的名称(也被 GSSAPI 使用)。默认是postgres。通常没有理由改变这个值,除非你是一个 Windows 环境,这种情况下该名称必须被设置为大写形式POSTGRES。
--with-llvm
支持基于LLVM的JIT编译 。 这需要安装LLVM库。 当前LLVM的最低要求版本是3.9。
llvm-config 可用于查找所需的编译选项。llvm-config会在PATH 上搜索所有受支持版本的llvm-config-$major-$minor。 如果那还不能找到正确的二进制文件,请使用LLVM_CONFIG指定正确的 llvm-config的路径。例如:
./configure ... --with-llvm LLVM_CONFIG='/path/to/llvm/bin/llvm-config'
LLVM支持需要兼容的clang编译器 (必要时使用CLANG环境变量指定)和有效的C++编译器 (必要时使用使用CXX环境变量指定)。
--with-icu
支持ICU库。 这需要安装ICU4C软件包。 目前要求的最低ICU4C版本是4.2。
默认的,pkg-config 将被用来查找所需的编译选项。支持ICU4C版本4.6及更高版本。 对于较老版本,或者如果pkg-config不可用, 可以将变量ICU_CFLAGS和ICU_LIBS 指定为configure,就像下面的示例中那样:
./configure ... --with-icu ICU_CFLAGS='-I/some/where/include' ICU_LIBS='-L/some/where/lib -licui18n -licuuc -licudata'
(如果ICU4C在编译器的默认搜索路径中, 那么你仍然需要指定一个非空的字符串,以避免使用pkg-config, 例如ICU_CFLAGS=' '。)
编译SSL(加密)连接支持。这个选项需要安装OpenSSL包。configure将会检查所需的头文件和库以确保你的 OpenSSL安装足以让配置继续下去。
--with-pam
--with-bsd-auth
编译 BSD 认证支持(BSD 认证框架目前只在 OpenBSD 上可用)。
--with-ldap
为认证和连接参数查找编译LDAP支持。在 Unix 上,这需要安装OpenLDAP包。在 Windows 上将使用默认的WinLDAP库。configure将会检查所需的头文件和库以确保你的 OpenLDAP安装足以让配置继续下去。
--with-systemd
编译对systemd 服务通知的支持。如果服务器是在systemd 机制下被启动,这可以提高集成度,否则不会有影响 否则,要使用这个选项,必须安装libsystemd 以及相关的头文件。
--without-readline
避免使用Readline库(以及libedit)。这个选项禁用了psql中的命令行编辑和历史, 因此我们不建议这么做。
--with-libedit-preferred
更倾向于使用BSD许可证的libedit库而不是GPL许可证的Readline。这个选项只有在你同时安装了两个库时才有意义,在那种情况下默认会使用Readline。
--with-bonjour
编译 Bonjour 支持。这要求你的操作系统支持 Bonjour。在 macOS 上建议使用。
--with-uuid=LIBRARY
使用指定的 UUID 库编译uuid_ossp模块(提供生成 UUID 的函数)。 LIBRARY必须是下列之一:
-
bsd,用来使用 FreeBSD、NetBSD 和一些其他 BSD 衍生系统 中的 UUID 函数 -
e2fs,用来使用e2fsprogs项目创建的 UUID 库, 这个库出现在大部分的 Linux 系统和 macOS 中,并且也能找到用于其他平台的 版本 -
ossp,用来使用OSSP UUID library
--with-ossp-uuid
--with-uuid=ossp的已废弃的等效选项。
--with-libxml
编译 libxml (启用 SQL/XML 支持)。这个特性需要 Libxml 版本 2.6.23 及以上。
Libxml 会安装一个程序xml2-config,它可以被用来检测所需的编译器和链接器选项。如果能找到,PostgreSQL 将自动使用它。要制定一个非常用的 libxml 安装位置,你可以设置环境变量XML2_CONFIG指向xml2-config程序所属的安装,或者使用选项--with-includes和--with-libraries。
--with-libxslt
编译xml2模块时使用 libxslt。xml2依赖这个库来执行XML的XSL转换。
--disable-float4-byval
禁用 float4 值的“传值”,导致它们只能被“传引用”。这个选项会损失性能,但是在需要兼容使用 C 编写并使用“version 0”调用规范的老用户定义函数时可能需要这个选项。更好的长久解决方案是将任何这样的函数更新成使用“version 1”调用规范。
--disable-float8-byval
禁用 float8 值的“传值”,导致它们只能被“传引用”。这个选项会损失性能,但是在需要兼容使用 C 编写并使用“version 0”调用规范的老用户定义函数时可能需要这个选项。更好的长久解决方案是将任何这样的函数更新成使用“version 1”调用规范。注意这个选项并非只影响 float8,它还影响 int8 和某些相关类型如时间戳。在32位平台上,--disable-float8-byval是默认选项并且不允许选择--enable-float8-byval。
--with-segsize=SEGSIZE
设置段尺寸,以 G 字节计。大型的表会被分解成多个操作系统文件,每一个的尺寸等于段尺寸。这避免了与操作系统对文件大小限制相关的问题。默认的段尺寸(1G字节)在所有支持的平台上都是安全的。如果你的操作系统有“largefile”支持(如今大部分都支持),你可以使用一个更大的段尺寸。这可以有助于在使用非常大的表时消耗的文件描述符数目。但是要当心不能选择一个超过你将使用的平台和文件系统所支持尺寸的值。你可能希望使用的其他工具(如tar)也可以对可用文件尺寸设限。如非绝对必要,我们推荐这个值应为2的幂。注意改变这个值需要一次 initdb。
--with-blocksize=BLOCKSIZE
设置块尺寸,以 K 字节计。这是表内存储和I/O的单位。默认值(8K字节)适合于大多数情况,但是在特殊情况下可能其他值更有用。这个值必须是2的幂并且在 1 和 32 (K字节)之间。注意修改这个值需要一次 initdb。
--with-wal-segsize=SEGSIZE
设置WAL 段尺寸,以 M 字节计。这是 WAL 日志中每一个独立文件的尺寸。调整这个值来控制传送 WAL 日志的粒度非常有用。默认尺寸为 16 M字节。这个值必须是2的幂并且在 1 到 1024 (M字节)之间。注意修改这个值需要一次 initdb。
--with-wal-blocksize=BLOCKSIZE
设置WAL 块尺寸,以 K 字节计。这是 WAL 日志存储和I/O的单位。默认值(8K 字节)适合于大多数情况,但是在特殊情况下其他值更好有用。这个值必须是2的幂并且在 1 到 64(K字节)之间。注意修改这个值需要一次 initdb。
--disable-spinlocks
即便PostgreSQL对于该平台没有 CPU 自旋锁支持,也允许编译成功。自旋锁支持的缺乏会导致较差的性能,因此这个选项只有当编译终端或者通知你该平台缺乏自旋锁支持时才应被使用。如果在你的平台上要求使用该选项来编译PostgreSQL,请将此问题报告给PostgreSQL的开发者。
--disable-strong-random
即使PostgreSQL不支持平台上的强大随机数,也允许构建成功。 一些认证协议以及pgcrypto 模块中的一些例程需要随机数的来源。--disable-strong-random 禁用需要密码强的随机数的功能,并用弱伪随机数生成器代替验证盐值生成和查询取消密钥。 它可能会使认证安全性降低。
--disable-thread-safety
禁用客户端库的线程安全性。这会阻止libpq和ECPG程序中的并发线程安全地控制它们私有的连接句柄。
--with-system-tzdata=DIRECTORY
PostgreSQL包含它自己的时区数据库,它被用于日期和时间操作。这个时区数据库实际上是和 IANA 时区数据库相兼容的,后者在很多操作系统如 FreeBSD、Linux和Solaris上都有提供,因此再次安装它可能是冗余的。当这个选项被使用时,将不会使用DIRECTORY中系统提供的时区数据库,而是使用包括在 PostgreSQL 源码发布中的时区数据库。DIRECTORY必须被指定为一个绝对路径。/usr/share/zoneinfo在某些操作系统上是一个很有可能的路径。注意安装例程将不会检测不匹配或错误的时区数据。如果你使用这个选项,建议你运行回归测试来验证你指定的时区数据能正常地工作在PostgreSQL中。
这个选项主要针对那些很了解他们的目标操作系统的二进制包发布者。使用这个选项主要优点是不管何时当众多本地夏令时规则之一改变时, PostgreSQL 包不需要被升级。另一个优点是如果时区数据库文件在安装时不需要被编译, PostgreSQL 可以被更直接地交叉编译。
--without-zlib
避免使用Zlib库。这样就禁用了pg_dump和 pg_restore中对压缩归档的支持。这个选项只适用于那些没有这个库的少见的系统。
--enable-debug
把所有程序和库以带有调试符号的方式编译。这意味着你可以通过一个调试器运行程序来分析问题。 这样做显著增大了最后安装的可执行文件的大小,并且在非 GCC 的编译器上,这么做通常还要关闭编译器优化, 这些都导致速度的下降。但是,如果有这些符号的话,就可以非常有效地帮助定位可能发生问题的位置。目前,我们只是在你使用 GCC 的情况下才建议在生产安装中使用这个选项。但是如果你正在进行开发工作,或者正在使用 beta 版本,那么你就应该总是打开它。
--enable-coverage
如果在使用 GCC,所有程序和库都会用代码覆盖率测试工具编译。在运行时,它们会在编译目录中生成代码覆盖率度量的文件。这个选项只用于 GCC 以及做开发工作时。
--enable-profiling
如果在使用 GCC,所有程序和库都被编译成可以进行性能分析。在后端退出时,将会创建一个子目录,其中包含用于性能分析的gmon.out文件。这个选项只用于 GCC 和做开发工作时。
--enable-cassert
打开在服务器中的assertion检查, 它会检查许多“不可能发生”的条件。它对于代码开发的用途而言是无价之宝, 不过这些测试可能会显著地降低服务器的速度。并且,打开这个测试不会提高你的系统的稳定性! 这些断言检查并不是按照严重性分类的,因此一些相对无害的小故障也可能导致服务器重启 — 只要它触发了一次断言失败。 目前,我们不推荐在生产环境中使用这个选项,但是如果你在做开发或者在使用 beta 版本的时候应该打开它。
--enable-depend
打开自动倚赖性跟踪。如果打开这个选项,那么制作文件(makefile)将设置为在任何头文件被修改的时候都将重新编译所有受影响的目标文件。 如果你在做开发的工作,那么这个选项很有用,但是如果你只是想编译一次并且安装,那么这就是浪费时间。 目前,这个选项只对 GCC 有用。
--enable-dtrace
为PostgreSQL编译对动态跟踪工具 DTrace 的支持。
要指向dtrace程序,必须设置环境变量DTRACE。这通常是必需的,因为dtrace通常被安装在/usr/sbin中,该路径可能不在搜索路径中。
dtrace程序的附加命令行选项可以在环境变量DTRACEFLAGS中指定。在 Solaris 上,要在一个64位二进制中包括 DTrace,你必须为 configure 指定DTRACEFLAGS="-64"。例如,使用 GCC 编译器:
./configure CC='gcc -m64' --enable-dtrace DTRACEFLAGS='-64' ...使用 Sun 的编译器:
./configure CC='/opt/SUNWspro/bin/cc -xtarget=native64' --enable-dtrace DTRACEFLAGS='-64' ...
--enable-tap-tests
启用 Perl TAP 工具进行测试。这要求安装了 Perl 以及 Perl 模块IPC::Run。
如果你喜欢用那些和configure选取的不同的 C 编译器,那么你可以你的环境变量CC设置为你选择的程序。默认时,只要gcc可以使用,configure将选择它, 或者是该平台的默认(通常是cc)。类似地,你可以用CFLAGS变量覆盖默认编译器标志。
你可以在configure命令行上指定环境变量, 例如:
./configure CC=/opt/bin/gcc CFLAGS='-O2 -pipe'
下面是可以以这种方式设置的有效变量的列表:
BISON
Bison程序
CC
C编译器
CFLAGS
传递给 C 编译器的选项
CLANG
clang程序的路径,用于处理使用-with-llvm 进行编译时内联的源代码。
CPP
C 预处理器
CPPFLAGS
传递给 C 预处理器的选项
CXX
C++编译器
CXXFLAGS
传给C++编译器的选项
DTRACE
dtrace程序的位置
DTRACEFLAGS
传递给dtrace程序的选项
FLEX
Flex程序
LDFLAGS
链接可执行程序或共享库时使用的选项
LDFLAGS_EX
只用于链接可执行程序的附加选项
LDFLAGS_SL
只用于链接共享库的附加选项
LLVM_CONFIG
llvm-config程序用于查找 LLVM安装。
MSGFMT
用于本地语言支持的msgfmt程序
PERL
Perl 解释器的全路径名称。这将被用来决定编译 PL/Perl 时的依赖性。
PYTHON
Python 解释器程序。这将被用来决定编译 PL/Python 时的依赖性。另外这里指定的是 Python 2 还是 Python 3 (或者是隐式选择)决定了 PL/Python 语言的哪一种变种将成为可用的。 如果未设置,则按以下顺序探测:python python3 python2。
TCLSH
Tcl 解释器的程序。这将被用来决定编译 PL/Tcl 时的依赖性,并且它将被替换到 Tcl 脚本中。
XML2_CONFIG
用于定位 libxml 安装的xml2-config程序。
有时候,将编译器标志事后添加到由configure选择的集合中非常有用。 一个重要的例子是,gcc的-Werror 选项不能包含在传递给configure的CFLAGS中, 因为它会中断许多configure的内置测试。要添加这样的标志, 在运行make时将它们包含在COPT环境变量中。 将COPT的内容添加到由configure设置的 CFLAGS和LDFLAGS中。例如,你可以这样做
make COPT='-Werror'
或者
export COPT='-Werror'
make注意:
在开发服务器内部代码时,我们推荐使用配置选项
--enable-cassert(它会打开很多运行时错误检查)和--enable-debug(它会提高调试工具的有用性)。如果在使用 GCC,最好使用至少
-O1的优化级别来编译,因为不使用优化(-O0)会禁用某些重要的编译器警告(例如使用未经初始化的变量)。但是,非零的优化级别会使调试更复杂,因为在编译好的代码中步进通常将不能和源代码行一一对应。如果你在尝试调试优化过的代码时觉得困惑,将感兴趣的特定文件使用-O0编译。一种简单的方式是传递一个选项给make:make PROFILE=-O0 file.o。
COPT和PROFILE环境变量同样由PostgreSQL makefile实际处理。要使用哪个是一个性能问题,但是开发者的共同习惯是将PROFILE用于一次性的标识调整,而始终保持设置COPT。
4.2. 编译
要开始编译,键入:
make
(一定要记得用GNU make)。依你的硬件而异,编译过程可能需要 5 分钟到半小时。显示的最后一行应该是:
All of PostgreSQL successfully made. Ready to install.
如果你希望编译所有能编译的东西,包括文档(HTML和手册页)以及附加模块(contrib),这样键入:
make world
显示的最后一行应该是:
PostgreSQL, contrib, and documentation successfully made. Ready to install.
如果要调用另一个makefile而不是手动构建,则必须取消设置 MAKELEVEL或将其设置为零,例如这样:
build-postgresql:
$(MAKE) -C postgresql MAKELEVEL=0 all
否则可能会导致奇怪的错误消息,通常是有关缺少头文件的消息。
4.3. 回归测试
如果你想在安装文件前测试新编译的服务器, 那么你可以在这个时候运行回归测试。 回归测试是一个用于验证PostgreSQL在你的系统上是否按照开发人员设想的那样运行的测试套件。键入:
make check
(这条命令不能以 root 运行;请在非特权用户下运行该命令)。 (This won't work as root; do it as an unprivileged user.) 你可以在以后的任何时间通过执行这条命令来运行这个测试。
4.4. 安装文件
要安装PostgreSQL,输入:
make install
这条命令将把文件安装到在步骤4.1中指定的目录。确保你有足够的权限向该区域写入。通常你需要用 root 权限做这一步。或者你也可以事先创建目标目录并且分派合适的权限。
要安装文档(HTML和手册页),输入:
make install-docs
如果你按照上面的方法编译了所有东西,输入:
make install-world
这也会安装文档。
你可以使用make install-strip代替make install, 在安装可执行文件和库文件时把它们剥离。 这样将节约一些空间。如果你编译时带着调试支持,那么抽取将有效地删除调试支持, 因此我们应该只是在不再需要调试的时候做这些事情。 install-strip力图做一些合理的工作来节约空间, 但是它并不了解如何从可执行文件中抽取每个不需要的字节, 因此,如果你希望节约所有可能节约的磁盘空间,那么你可能需要手工做些处理。
标准的安装只提供客户端应用开发和服务器端程序开发所需的所有头文件,例如用 C 写的定制函数或者数据类型(在PostgreSQL 8.0 之前,后者需要独立地执行一次make install-all-headers命令,不过现在这个步骤已经融合到标准的安装步骤中)。
只安装客户端:. 如果你只想装客户应用和接口,那么你可以用下面的命令:
make -C src/bin install
make -C src/include install
make -C src/interfaces install
make -C doc installsrc/bin中有一些服务器专用的二进制文件,但是它们很小。
卸载:. 要撤销安装可以使用命令make uninstall。不过这样不会删除任何创建出来的目录。
清理:. 在安装完成以后,你可以通过在源码树里面用命令make clean删除编译文件。 这样会保留configure程序生成的文件,这样以后你就可以用make命令重新编译所有东西。 要把源码树恢复为发布时的状态,可用make distclean命令。 如果你想从同一棵源码树上为多个不同平台制作,你就一定要运行这条命令并且为每个编译重新配置(另外一种方法是在每种平台上使用一套独立的编译树,这样源代码树就可以保留不被更改)。
如果你执行了一次制作,然后发现你的configure选项是错误的, 或者你修改了任何configure所探测的东西(例如,升级了软件), 那么在重新配置和编译之前运行一下make distclean是个好习惯。如果不这样做, 你修改的配置选项可能无法传播到所有需要变化的地方。
五、安装后设置
5.1 共享库
在一些有共享库的系统里,你需要告诉你的系统如何找到新安装的共享库。那些并不是必须做这个工作的系统包括 FreeBSD、HP-UX、Linux、NetBSD、OpenBSD和Solaris。
设置共享库的搜索路径的方法因平台而异, 但是最广泛使用的方法是设置环境变量LD_LIBRARY_PATH,例如在 Bourne shells (sh、ksh、bash、zsh)中:
LD_LIBRARY_PATH=/usr/local/pgsql/lib
export LD_LIBRARY_PATH或者在csh或tcsh中:
setenv LD_LIBRARY_PATH /usr/local/pgsql/lib
把/usr/local/pgsql/lib换成你在步骤4.1时设置的--libdir/etc/profile或~/.bash_profile中。 和这个方法相关的一些注意事项和很好的信息可以在Why LD_LIBRARY_PATH is bad 找到。
在有些系统上,更好的方法可能是在编译之前设置环境变量LD_RUN_PATH。
在Cygwin上,把库目录放在PATH中或者把.dll文件移动到bin目录。
如果有疑问,请参考你的系统的手册页(可能是ld.so或rld)。 如果稍后你收到下面这样的消息:
psql: error in loading shared libraries
libpq.so.2.1: cannot open shared object file: No such file or directory那么这一步就是必须的了。这个只需关注一下就是了。
如果你用的系统是Linux,并且你还有 root 权限,那么你可以在安装之后运行:
/sbin/ldconfig /usr/local/pgsql/lib(或者等效的目录)以便让运行时链接器更快地找到共享库。请参考ldconfig的手册页获取更多信息。在FreeBSD、NetBSD和OpenBSD上,命令是:
/sbin/ldconfig -m /usr/local/pgsql/lib
我们不知道其它的系统有等效的命令。
5.2 环境变量
如果你安装到/usr/local/pgsql或者其他默认不在搜索路径中的地方, 那你应该在你的PATH环境变量里面增加一个 /usr/local/pgsql/bin(或者是你在步骤 1时给选项--bindir
要做这些事情,把下面几行加到你的 shell 启动文件,如~/.bash_profile(如果想影响所有用户就放在/etc/profile):
PATH=/usr/local/pgsql/bin:$PATH
export PATH如果你用的是csh或者tcsh,那么用这条命令:
set path = ( /usr/local/pgsql/bin $path )为了让你的系统找得到man文档,你需要加类似下面的一行到一个shell启动文件里 (除非你安装到了默认搜索的位置):
MANPATH=/usr/local/pgsql/share/man:$MANPATH
export MANPATH环境变量PGHOST和PGPORT为客户端应用指定了数据库服务器的主机和端口, 它们会覆盖编译时的默认项。如果你想从远程运行客户端应用, 那么为每个准备使用该数据库的用户都设置PGHOST将会非常方便。但这不是必须的,而且大部分客户端程序也可以通过命令行选项替换这些设置。
六、平台支持
如果代码包含规定要工作在一个平台(即一种 CPU 架构和操作系统的结合)上并且它最近已经被验证能在该平台上编译并通过其回归测试,PostgreSQL开发社区才会认为该平台是被支持的。目前,大部分平台兼容性的测试都是由PostgreSQL 编译农场的测试机器自动完成的。如果你对在一个并没有出现在编译农场中的平台上运行PostgreSQL感兴趣,但是代码确实能够工作或者能被修改得工作,我们强烈鼓励你建立一个编译农场成员机器,这样进一步的兼容性可以被确认。
通常,PostgreSQL被期望能在这些 CPU 架构上工作:x86、 x86_64、IA64、PowerPC、PowerPC 64、S/390、S/390x、Sparc、Sparc 64、ARM、MIPS、MIPSEL和PA-RISC。存在对 M68K、M32R 和 VAX 的代码支持,但是这些架构上并没有近期测试的报告。通常也可以在一个为支持的 CPU 类型上通过使用--disable-spinlocks配置来进行编译,但是性能将会比较差。
PostgreSQL被期望能在这些操作系统上工作: Linux(所有最近的发布)、Windows(Win2000 SP4及以上)、 FreeBSD、OpenBSD、NetBSD、macOS、AIX、HP/UX 和 Solaris。其他类 Unix 系统可能也可以工作,但是目前没有被测试。在大部分情况下,一个给定操作系统所支持的所有 CPU 架构都能工作。查找下文的第七节来看是否有与你的操作系统相关的信息,特别是使用一个老的系统时更应该这样做。
如果你在一个平台上有安装问题,并且该平台根据最近的编译农场结果已经可以被支持,请将问题报告给<pgsql-bugs@lists.postgresql.org>。如果你有兴趣将PostgreSQL移植到一个新的平台,<pgsql-hackers@lists.postgresql.org>是一个合适的讨论它的地方。
七、平台相关的说明
这一节提供了考虑 PostgreSQL 安装和设置的附加平台相关的话题。确保阅读安装指导,特别是第二节。
这里没有覆盖的平台不存在平台相关的安装问题。
7.1 AIX
PostgreSQL 能在 AIX 上工作,但是正确地安装它却富有挑战性。从4.3.3到6.1的 AIX 被认为是可支持的。你可以使用 GCC 或本地 IBM 编译器xlc。通常,使用最新版本的 AIX 和 PostgreSQL 能有所帮助。在编译农场中检查有关已知能工作的 AIX 版本的最新信息。
被支持的 AIX 版本的最小推荐修理级别是:
AIX 4.3.3
Maintenance Level 11 + post ML11 bundle
AIX 5.1
Maintenance Level 9 + post ML9 bundle
AIX 5.2
Technology Level 10 Service Pack 3
AIX 5.3
Technology Level 7
AIX 6.1
Base Level
要检查你当前的修理级别,在AIX 4.3.3 至 AIX 5.2 ML 7中使用 oslevel -r,或者在后面的版本中使用 oslevel -s。
如果你已经在/usr/local中安装了 Readline 或 libz,在你自己的选项之外使用下列configure标志: --with-includes=/usr/local/include --with-libraries=/usr/local/lib.
7.1.1. GCC问题
在 AIX 5.3 上,使用 GCC 编译和运行 PostgreSQL 有一些问题。
你将要使用 GCC 继 3.3.2 之后的一个版本,特别是如果你在使用一个打包好的版本。我们在 4.0.1 上获得了成功。早期版本的问题看起来更多地与 IBM 打包的 GCC 有关,而非 GCC 真正的问题,因此如果你自己编译 GCC, 你更有可能使用早期版本的 GCC 取得成功。
7.1.2. Unix域套接字崩溃
AIX 5.3 有一个问题是sockaddr_storage定义得不够大。在版本 5.3 中,IBM 增加了sockaddr_un(Unix域套接字的地址结构)的尺寸,但是没有相应地增加sockaddr_storage的尺寸。这样做的结果是在 PostgreSQL 中尝试使用 Unix域套接字会导致 libpq 让该数据结构溢出。 TCP/IP 连接工作正常,但是 Unix域套接字不行,这将使回归测试不能工作。
该问题已经被报告给了 IBM,并且已被记录为缺陷报告 PMR29657。如果你升级到 maintenance level 5300-03 或更新,将会包括这个修复。一种快速的解决方法是把/usr/include/sys/socket.h中的_SS_MAXSIZE改成 1025。在两种情况中,一旦你得到了修正过的头文件,你都需要重编译 PostgreSQL。
7.1.3. Internet地址问题
PostgreSQL 依赖系统的getaddrinfo函数来解析listen_addresses、pg_hba.conf等中的 IP 地址。旧版本的 AIX 在这个函数中有各种各样的缺陷。如果你存在与此有关的问题,更新到上文所示的合适的 AIX fix level 将会解决它。
一个用户报告:
当在 AIX 5.3 上实现 PostgreSQL 版本 8.1 时,我们会周期性地碰到问题,在其中统计收集器会“神秘地”无法成功启动。这似乎是在 IPv6 实现中意外行为的结果。看起来 PostgreSQL 和 IPv6 无法和 AIX 5.3 一起很好地工作。
下面任意一种动作都可以“修复”该问题。
-
删除 localhost 的 IPv6 地址:
(as root)
# ifconfig lo0 inet6 ::1/0 delete- 从网络服务删除 IPv6。AIX 上的
/etc/netsvc.conf大概等价于 Solaris/Linux 上的/etc/nsswitch.conf。在 AIX 上的默认值因此是:
hosts=local,bind
将其换成:
hosts=local4,bind4
来使 IPv6 地址的搜索无效。
警告:
这实际上是对有关 IPv6 支持不成熟性的问题的一种变通方案,这在 AIX 5.3 发布的过程中有了显著地改进。它可以和 AIX 5.3 一起工作,但是不代表对此问题的一种华丽的解决方案。有报告称该变通方案不仅仅是多余的,还会在 AIX 6.1 上导致问题,在 AIX 6.1 中 IPv6 支持已变得更加成熟。
7.1.4 内存管理
AIX 的特别之处在于它的内存管理。你可能有一个装备有好多个吉字节空闲 RAM 的服务器,但是在运行应用时仍然会得到内存不足或者地址空间错误。一个例子是加载扩展会因为罕见的错误失败。例如,作为 PostgreSQL 安装的拥有者运行:
=# CREATE EXTENSION plperl;
ERROR: could not load library "/opt/dbs/pgsql/lib/plperl.so": A memory address is not in the address space for the process.作为拥有 PostgreSQL 安装的组中的非拥有者运行:
=# CREATE EXTENSION plperl;
ERROR: could not load library "/opt/dbs/pgsql/lib/plperl.so": Bad address另一个例子是 PostgreSQL 服务器日志中的内存不足错误,每次内存分配接近或者超过 256 MB 时都会失败。
所有这些问题的总体成因是服务器进程所用的寻址空间和内存模型。默认情况下,所有在 AIX 上编译的二进制都是32位。这并不依赖于硬件类型或使用的内核。这些32位进程被限制在 4GB 的内存中,并被使用几种模型之一安排成 256 MB 的段。该默认值允许在堆中低于 256 MB,因为它和栈共享一个单独的段。
在plperl的例子中,检查你的 umask 和你的 PostgreSQL 安装中的二进制的权限。这个例子中涉及的二进制是32位的并且被用模式 750 而不是 755 安装。由于这种方式的权限设置,只有所有者或拥有组的成员可以载入该库。因为它不是所有人可读的,载入器将该对象放在进程的堆中而不是它应该被放入的共享库段中。
这个问题的“理想的”解决方案是使用 PostgreSQL 的64位编译,但是这不是总是实用的,因为有32位处理器的系统可以编译64位二进制但是却不能运行它。
如果想要一个 32 位二进制,在开始 PostgreSQL 服务器之前将LDR_CNTRL设置为MAXDATA=0x,其中 1 <= n <= 8,并且尝试不同的值以及n0000000postgresql.conf设置来找一个能让你满意的配置。这种LDR_CNTRL的使用告诉 AIX 你希望服务器留出MAXDATA字节给堆,以 256 MB 的段分配。当你找到了一个可工作的配置时,ldedit可以被用来修改二进制,这样它们默认使用想要的堆尺寸。PostgreSQL 也可以被重新编译,传递configure LDFLAGS="-Wl,-bmaxdata:0x来达到相同的效果。n0000000"
对于一个 64 位编译,设置OBJECT_MODE为 64 并且传递CC="gcc -maix64"和LDFLAGS="-Wl,-bbigtoc"给configure(给xlc的选项可能不同)。如果你省略OBJECT_MODE的输出,你的编译可能会因为链接器错误而失败。当OBJECT_MODE被设置时,它告诉 AIX 的编译工具(如ar、as和ld)默认要处理哪些对象类型。
默认情况下,过量使用页面空间的情况可能会发生。不过我们还没有看到过,当进程用尽内存并且出现了过量使用时 AIX 会杀死进程。我们见到过的最接近于此的是 fork 失败,其原因是系统觉得已经没有足够的内存给另一个进程。和 AIX 的很多其他部分一样,如果这成为了一个问题,页面空间分配方法和耗尽内存导致的杀死在系统范围或进程范围是可以配置的。
参考和资源
“Large Program Support”. AIX Documentation: General Programming Concepts: Writing and Debugging Programs.
“Program Address Space Overview”. AIX Documentation: General Programming Concepts: Writing and Debugging Programs.
“Performance Overview of the Virtual Memory Manager (VMM)”. AIX Documentation: Performance Management Guide.
“Page Space Allocation”. AIX Documentation: Performance Management Guide.
“Paging-space thresholds tuning”. AIX Documentation: Performance Management Guide.
Developing and Porting C and C++ Applications on AIX. IBM Redbook.
7.2. Cygwin
PostgreSQL 可以使用 Cygwin 来编译,它是用于 Windows 的一个类 Linux 环境,但是这种方法不如原生 Windows 编译见下一章)并且我们已经不再推荐在 Cygwin 下运行一个服务器。
在从源代码编译时,按照正常安装过程进行(即./configure; make; 等;只要注意下列 Cygwin 相关的区别:
-
将你的路径设置为使用 Cygwin 的 bin 目录并且把它放在 Windows 工具的前面。这将帮助避免很多编译的问题。
-
不支持
adduser命令;使用 Windows NT、2000 或 XP 上的用户管理应用来替代。否则,跳过这一步。 -
不支持
su命令;在 Windows NT、2000 或 XP 上使用 ssh 来模拟 su。否则,跳过这一步。 -
不支持 OpenSSL。
-
为共享内存支持启动
cygserver。要这样做,输入命令/usr/sbin/cygserver &。这个程序在你启动 PostgreSQL 服务器或初始化一个数据集簇(initdb)时的任何时刻都需要被运行。默认的cygserver配置可能需要被更改(例如增加SEMMNS)来防止 PostgreSQL 因为缺少系统资源而失败。 -
在某些不使用 C 区域的系统上编译可能会失败。要修复这个问题,通过在边以前
export LANG=C.utf8把区域设置为 C,并且在安装完 PostgreSQL 之后把区域恢复成之前的设置。 -
并行回归测试(
make check)可能产生虚假的回归测试错误,这是由于溢出的listen()连接缓冲区,它会导致连接拒绝错误或挂起。你可以使用MAX_CONNECTIONS来限制连接数:
make MAX_CONNECTIONS=5 check
(在某些系统上你可以有大约 10 个同时连接)。
可以把cygserver PostgreSQL 服务器安装为 Windows NT 服务。关于如何这样做的信息,请参考包含在 Cygwin 上 PostgreSQL 二进制包中的README文档。它被安装在目录/usr/share/doc/Cygwin中。
7.3. HP-UX
给定合适的系统补丁级别和编译工具,PostgreSQL 7.3+ 应该可以工作在运行 HP-UX 10.X 或 11.X 的 Series 700/800 PA-RISC 机器上。至少一个开发者例行地在 HP-UX 10.20 上测试过,并且我们有在 HP-UX 11.00 和 11.11 上成功安装的报告。
除了 PostgreSQL 源代码发布,你将需要 GNU make(HP 的 make 不行),并且需要 GCC 或 HP 的 ANSI C 编译器。如果你想从 Git 源编译而不是一个发布包,你还将需要 Flex(GNU lex)和 Bison(GNU yacc)。我们还推荐确认你真的在使用最新的 HP 补丁。最低限度下,如果你在 HP-UX 11.11 上编译 64 位二进制,你可能需要 PHSS_30966 (11.11) 或一个后继补丁,否则initdb可能中止:
PHSS_30966 s700_800 ld(1) and linker tools cumulative patch
在一般原则上,你应该使用 libc 和 ld/dld 的当前补丁,如果你在使用 HP 的 C 编译器也一样要用当前的编译器补丁。它们最新补丁的免费拷贝请见 HP 的支持站点如ftp://us-ffs.external.hp.com/。
如果你正在一台 PA-RISC 2.0 机器上编译并且项使用 GCC 得到 64 位二进制,你必须使用 GCC 的 64 位版本。
如果你正在一台 PA-RISC 2.0 机器上编译并且想让编译好的二进制运行在 PA-RISC 1.1 机器上,你将需要在CFLAGS中指定+DAportable。
如果你正在一台 HP-UX Itanium 机器上编译,你将需要最新的 HP ANSI C 编译器,以及它的依赖补丁或后继补丁:
PHSS_30848 s700_800 HP C Compiler (A.05.57)
PHSS_30849 s700_800 u2comp/be/plugin library Patch
如果你同时有 HP 的 C 编译器和 GCC 的编译器,那么在运行configure时你可能希望显式地选择要使用的编译器:
./configure CC=cc
用于 HP 的 C 编译器,或者
./configure CC=gcc
用于 GCC。如果你忽略这个设置,configure 在可以选择时会使用gcc。
默认的安装目标位置是/usr/local/pgsql,你可能希望修改它为/opt之下的某个地方。如果是这样,使用configure的--prefix开关。
在回归测试中,在几何测试中可能会有某些低序位差别,这会根据你使用的编译器和数学库版本而变化。任何其他错误都需要怀疑。
7.4 macOS
在最新的macOS版本中,有必要将“sysroot” 路径嵌入用于查找某些系统头文件的include选项中。这导致configure 脚本的输出会有所不同,具体取决于在configure期间使用的SDK版本。 在简单的情况下,这应该不会造成任何问题,但是,如果您要尝试在与构建服务器代码不同 的计算机上构建扩展程序,则可能需要强制使用其他sysroot路径。为此,需要设置 PG_SYSROOT,例如:
make PG_SYSROOT=/desired/path all要在您的计算机上找到合适的路径,请运行
xcodebuild -version -sdk macosx Path
请注意,实际上不建议使用与构建核心服务器不同的sysroot版本构建扩展。 在最坏的情况下,它可能导致难以调试的ABI不一致。
您还可以在配置时选择非默认的sysroot路径,通过在 configure中指定PG_SYSROOT:
./configure ... PG_SYSROOT=/desired/path
macOS的“系统完整性保护”(SIP) 功能破坏了make check,因为它阻止通过 设置所需的DYLD_LIBRARY_PATH传递给被测试的可执行文件。 您可以通过在make check之前执行make install来解决此问题。 不过,大多数Postgres开发人员关闭了SIP。
7.5. MinGW/原生 Windows
用于 Windows 的 PostgreSQL 可以使用 MinGW 编译,它是一个用于微软操作系统的类 Unix 的编译环境。也可以使用微软的Visual C++编译器套件来编译。MinGW 编译使用本章中描述的正常编译系统;而 Visual C++ 编译的工作完全不同并且在 下一章中描述。后者是一种完全原生的编译并且没有像 MinGW 那样使用额外软件。在 PostgreSQL 的主网站上有一个现成的安装器可用。
原生 Windows 移植要求一个 Windows 2000 或更高的 32 或 64 位版本。早期的操作系统没有足够的基础设施(但 Cygwin可以用在它们之上)。类 Unix 的编译工具 MinGW 和 MSYS(一个 Unix 工具集合,用于运行如configure之类的 shell 脚本)可以从http://www.mingw.org/下载。运行结果二进制两者都需要,它们只在创建二进制时需要。
要使用 MinGW 编译 64 位二进制,从MinGW-w64安装 64 位工具。把它放在PATH中的 bin 目录,并且使用--host=x86_64-w64-mingw32选项运行configure.
在你安装完所有的东西之后,我们建议你在CMD.EXE下运行psql,因为 MSYS 控制台有缓冲问题。
7.5.1. 在 Windows 上收集崩溃转储
如果 PostgreSQL 在 Windows 上崩溃,它有能力产生minidumps,这可以被用来追踪崩溃发生的原因,这与 Unix 上的核心转储相似。这些转储可以被使用Windows Debugger Tools或Visual Studio读取。要启用在 Windows 上的转储生成,可在集簇数据目录下创建一个名为crashdumps的子目录。转储将被写入到这个目录,转储的名字基于崩溃进程的标识符和崩溃的当前时间来确定。
7.6. Solaris
PostgreSQL 在 Solaris 上得到了很好的支持。你的操作系统越新,你将会碰到更少的问题;细节如下。
7.6.1. 要求的工具
你可以使用 GCC 或 Sun 的编译器套件进行编译。为了更好的代码优化,我们强烈推荐在 SPARC 架构下使用 Sun 的编译器。我们已经得到一些使用 GCC 2.95.1 时的问题报告;我们推荐 GCC 2.95.3 或之后的版本。如果你正在使用 Sun 的编译器,注意不要选择/usr/ucb/cc;而是使用/opt/SUNWspro/bin/cc。
你可以从Oracle Developer Studio Downloads下载 Sun Studio。很多 GNU 工具都被整合到了 Solaris 10,或者它们在 Solaris companion CD 中。如果你喜欢用于老版本 Solaris 的包,你可以在http://www.sunfreeware.com找到这些工具。如果你想要源码,在GNU Mirror List- GNU Project - Free Software Foundation上找找。
7.6.2. configure 抱怨一个失败的测试程序
如果configure抱怨一个失败的测试程序,可能的情况是运行时链接器无法找到某些库,可能是libz、libreadline或某些其他非标准库如 libssl。要向它指出正确的位置,在configure命令行上设置LDFLAGS环境变量,例如:
configure ... LDFLAGS="-R /usr/sfw/lib:/opt/sfw/lib:/usr/local/lib"
更多信息可见ld手册页。
7.6.3. 64-位编译有时会崩溃
在 Solaris 7 和更老的版本上,64-位版本的 libc 有一个有缺陷的vsnprintf例程,这导致 PostgreSQL 中不稳定的核心转储。最简单的已知解决方案是强制 PostgreSQL 使用它自己的vsnprintf版本而不是库中的拷贝。要这样做,运行configure之后编辑一个由configure产生的文件: 在文件src/Makefile.global中将行
LIBOBJS =
改成
LIBOBJS = snprintf.o
(可能有其他文件已经被列在这个变量中。顺序无影响)。然后正常编译。
7.6.4. 为最优性能编译
在 SPARC 架构上,我们强烈推荐使用 Sun Studio来编译。尝试使用-xO5优化标志来生成显著加快的二进制。不要使用任何修改浮点操作和errno处理(例如-fast)行为的标志。这些标志可能会做出某些非标准 PostgreSQL 行为,例如在日期/时间计算中。
如果你没有理由要使用 SPARC 上的 64 位二进制,最好用 32 位版本。64 位操作较慢并且 64 位二进制比其 32 位变体要慢。并且在另一方面,AMD64 CPU 家族上的32 位代码不是原生的,并且这也是问什么在这个 CPU 族中 32 位代码要明显地更慢。
7.6.5. 用 DTrace 来跟踪 PostgreSQL
是的,可以使用 DTrace。
如果你看到postgres可执行程序的链接中断并且报出下面的错误消息:
Undefined first referenced
symbol in file
AbortTransaction utils/probes.o
CommitTransaction utils/probes.o
ld: fatal: Symbol referencing errors. No output written to postgres
collect2: ld returned 1 exit status
make: *** [postgres] Error 1说明你的 DTrace 安装太旧,无法处理静态函数中的探测。你需要 Solaris 10u4 或更新的版本。