PostGIS教程学习十九:基于索引的聚簇
数据库只能以从磁盘获取信息的速度检索信息。小型数据库将完全位于于RAM缓存(内存),并摆脱物理磁盘访问速度慢的限制。但是对于大型数据库,对物理磁盘的访问将限制数据库的信息检索速度。
数据是偶尔写入磁盘的,因此存储在磁盘上的有序数据与应用程序访问或组织该数据的方式之间不需要存在任何关联。
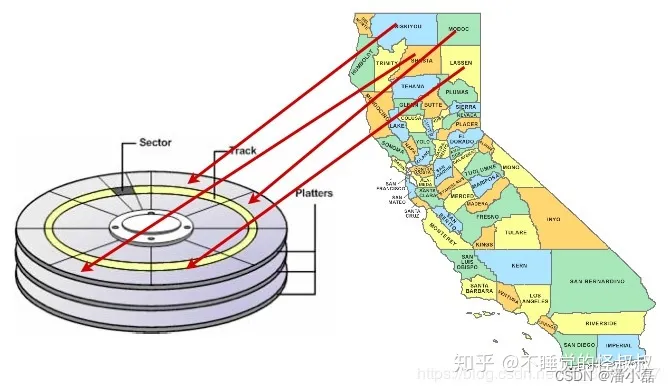
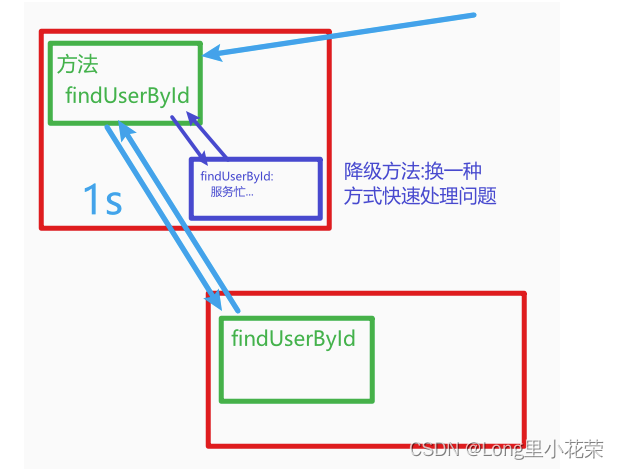
加速数据访问的一种方法是确保可能在同一结果集中一起被检索的记录位于硬盘上的相近物理位置。这就是所谓的"聚簇(clustering)"。
要使用正确的聚簇方案可能很棘手,但可以遵循一条通用性规则:索引定义了数据的自然排序方案,该方案类似于检索数据的访问模式。
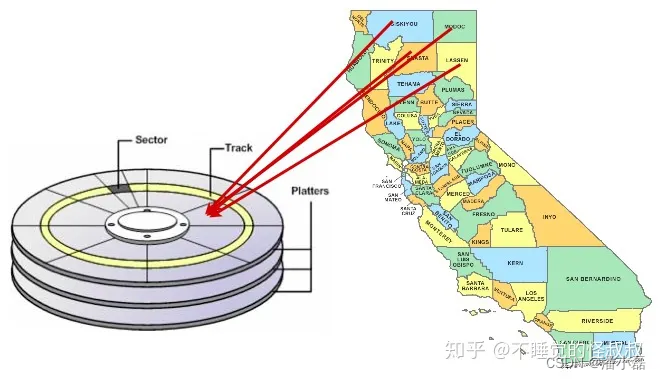
正因为如此,在某些情况下,以与索引相同的顺序对磁盘上的数据进行排序可以加速数据访问速度。
文章目录
- PostGIS教程学习十九:基于索引的聚簇
- 一、基于R-Tree的聚簇
- 二、GeoHash上的集群
- 三、本文涉及函数
一、基于R-Tree的聚簇
空间数据倾向于在客户端的窗口中访问:想想Web应用程序或桌面应用程序中的地图窗口。窗口中的所有数据都具有相近的位置信息(否则它们将不在相同的窗口中!)。
因此,基于空间索引的聚簇对于将通过空间查询访问的空间数据是有意义的:相似的事物往往具有相似的位置(地理学第一定律)。
让我们根据nyc_census_blocks的空间索引对该表数据进行聚簇(将数据放置在硬盘上的相近物理位置):
CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
该命令按照空间索引nyc_census_blocks_geom_idx所定义的顺序将数据重新写入nyc_census_blocks。你能感觉到访问数据的速度的差异吗?可能不会,因为表很小,很容易装入内存(缓存在内存中),所以磁盘访问开销不会影响性能。
R-Tree的一个令人惊讶的地方是,基于空间数据而递增构建的R-Tree可能没有很高的叶子结点(每个叶子结点对应一个地理区域和一个磁盘页)的空间协调性、一致性(spatial coherence)。例如,请参见不列颠哥伦比亚省(province of British Columbia)道路的空间索引叶节点的可视化:

我们更喜欢使用空间更均衡紧凑、排列合理的R-tree索引结构进行集群,比如这种平衡的R-Tree(balanced R-Tree)。
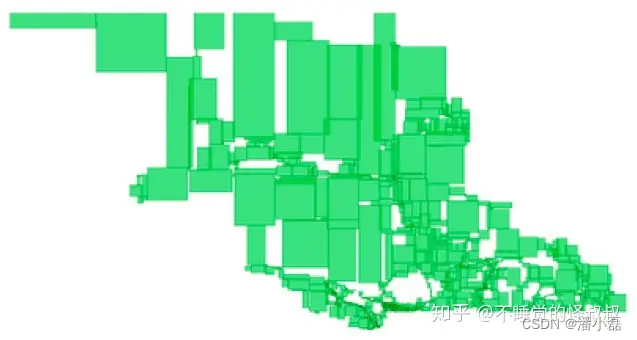
在PostGIS中没有平衡R-Tree的算法,但我们有一个有用的代替方法,可以对空间数据根据空间自相关的顺序进行排列,即ST_GeoHash()函数。
二、GeoHash上的集群
要使用ST_GeoHash()函数进行聚簇,首先需要在数据上有一个geohash索引。幸运的是,它们很容易构建。
geohash算法仅适用于地理(经度/纬度)坐标中的数据,因此我们需要在对其进行哈希操作之前先转换几何图形(转换为EPSG:4326,即经度/纬度):
CREATE INDEX nyc_census_blocks_geohash ON nyc_census_blocks (ST_GeoHash(ST_Transform(geom, 4326)));
一旦有了geohash索引,就可以使用和R-Tree聚簇相同的语法进行聚簇。
CLUSTER nyc_census_blocks USING nyc_census_blocks_geohash;
现在,数据就很好地以空间自相关的顺序排列!
三、本文涉及函数
ST_GeoHash(geometry A): Returns a text string representing the GeoHash of the bounds of the object.