存储管理
- 概述
- 存储管理器的体系结构
- 存储管理器的主要任务
- 读写元组过程
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书以及一些相关参考资料
概述
数据库管理系统(DBMS)的本质是向存储设备上写入数据或者读出数据,因此存储的管理是一项非常基础且重要的技术。在 PostgreSQL 中,存储管理器是专门负责管理存储设备的模块,其提供了一组统一管理外存和内存的功能模块。因此从本质上看,存储管理器提供了 PostgreSQL 与物理存取设备的接口。因为外存对应着各种磁盘设备,而内存则对应着各种随机存储器。存储管理器是整个 PostgreSQL 系统的底层模块,各种需要访问底层硬件的操作都需要调用其提供的接口。数据库存储管理系统的一般组件和功能的描述如下所示:
- 缓存管理: 这是数据库系统的核心部分,负责缓存数据页以提高访问速度。它与磁盘存储进行交互,将频繁访问的数据页保存在内存中,以减少直接的磁盘 I/O 操作。
- 基础存储管理: 这一层处理与磁盘的实际交互,包括数据页的读写。它确保数据能够持久化存储在磁盘上,并在需要时加载到缓存中。
- 大对象存储: 数据库中的大对象(如文本或图像)通常需要特殊的存储管理,因为它们的大小通常超过标准数据页的大小。
- 内存/日志文件管理: 这部分负责管理事务日志,确保所有的数据库操作都可以在系统故障后进行恢复。日志文件通常存储了所有的事务操作记录。
- 数据库备份与恢复: 这部分涉及到的操作包括数据库的备份,以及在数据丢失或损坏时的恢复。
- 空间管理: 数据库需要跟踪磁盘上的可用空间,这通常涉及到文件空间管理(FSM)和可见性图(VM),以跟踪哪些页是空的,哪些页是可见的。
- 垃圾回收: 为了优化存储空间和性能,数据库需要定期进行垃圾回收,如 PostgreSQL 中的 VACUUM 操作。这个过程包括清理不再需要的数据,如已删除的行。
- 可视化文件描述符(VFD): 这可能是指管理文件描述符的组件,这些是操作系统提供的用于引用打开文件的句柄。
- 进程间通信(IPC): 数据库系统可能包括多个进程或线程,这个部分负责这些进程之间的通信。
- 并发控制: 数据库系统必须处理多个并发操作,这部分负责管理并发访问,保证事务的隔离性和一致性。
- 索引管理: 数据库使用索引来快速定位数据,这部分负责索引的创建、维护和优化。
- 外部接口: 数据库需要与外部世界进行交互,例如,通过 SQL 接口与用户或其他系统通信。
存储管理器的体系结构
PostgreSQL存储管理器主要包括两个功能:内存管理与外存管理。存储管理器的体系结构如下图所示:
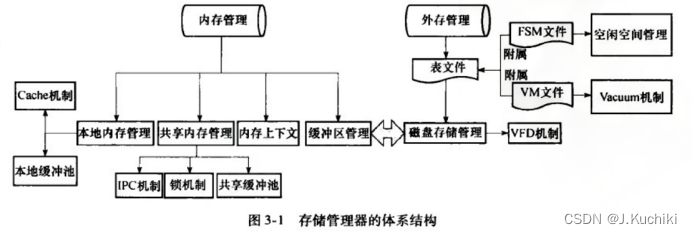
- 内存管理: 负责共享内存管理以及进程本地内存的管理。在共享内存中存储着所有进程的共享数据,包括锁变量,进程通信状态,缓冲区等。而本地内存为各个后台进程所有,是它们的工作区域,存储着属于该进程的 Cache、事务管理信息、进程信息等。为了防止多个进程并发地访问共享数据,PostgreSQL 还提供了轻量级的锁,用于支持对共享数据的互斥访问。此外,存储管理器还提供了内存上下文(MemoryContext)用于统一管理内存的分配与回收,从而更加安全有效地对内存空间进行管理;
- 外存管理: 负责表文件管理、空闲空间管理、虚拟文件描述符管理以及大数据存储管理等。在 PostgreSQL 中,每个表都用表文件存储,表文件以表的 OID 命名。当一个表文件超过文件大小限制时,PostgreSQL会自动将其切分为多个文件进行存储,并在 OID 的基础上加上编号作为该文件的名字。每个表除了表文件以外,还有两个附属文件:可见性映射表文件(VM),空闲空间映射表文件(FSM)。前者用于加快清理操作(VACUUM),后者则用于对表的空闲空间进行管理。为了避免打开的文件超过 OS 的限制,存储管理器还引入了虚拟文件描述符管理的机制。此外,存储管理器还提供了大对象机制以及 TOAST 机制用于支持对大数据的存储。
PostgreSQL 的存储管理是为了优化和保证数据库操作的效率和安全。内存管理负责处理运行时数据和进程间的快速交互,而外存管理确保数据持久性和有效的空间利用。通过这样的机制,PostgreSQL 能够高效地处理大量数据,支持高并发的数据库操作,并且提供了数据的持久化存储和恢复能力。同时,这种架构也支持了大数据和复杂数据类型的存储,满足现代应用对数据库的多样化需求。
PostgreSQL 的存储管理器采用与操作系统类似的分页存理方式,即据在内存中是以页面块的形式存在。每个表文件由多个 BLCKSZ (一个可配置的常量) 字节大小的文件块组成,每个文件块又可以包含多个元组。表文件以文件块为单位读入内存中,每一个文件块在内存中形成一个页面块。由于页面块是文件块在内存中的存在形式,因此在后文中如不进行特殊说明也会使用页面来指代文件块。同样,文件的写入也是以页面块为单位。PostgreSQL 采用传统的行式存储,即以元组为单位进行数据的存储。一个文件块中可以存放多个元组,但是 PostgreSQL 不支持元组的跨块存储,每个元组最大为 MaxHeapTupleSize。这样保证了每个文件块中存储的是多个完整的元组。
与操作系统一样,PostgreSQL在内存中开辟了缓冲区域用于存储这些文件块,我们将其在内存中开辟的缓冲区域称为缓冲池,缓冲池被划分成若于个固定大小(和文件块的尺寸相同,也是 BLCKSZ)的缓冲区,磁盘上的文件块读入内存后被存放在缓冲区中,称之为页面块或者缓冲块。BLCKSZ 的默认值是 8192,因此一个标准缓冲块的大小默认为 8KB。
用 AI 生成了一张图,但貌似有点抽象。。。
存储管理器的主要任务
总的来说,存储管理器的主要任务包括:
- 缓冲池管理: 为了提高事务执行的效率,事务在执行时,首先会先把数据放入的缓冲区中,PostgreSQL设立了进程间共享的缓冲池以及进程私有的缓冲池。
- Cache机制: 将进程最近使用的一些数据缓存到其私有内存中,其级别高于缓冲池。
- 虚拟文件描述符(VFD)管理: PostgreSQL 通过 VFD 来对物理文件进行管理,避免因为操作系统对进程打开文件数的限制出现错误。
- 空闲空间管理: PostgreSQL 通过 FSM 快速定位到表文件中的空闲空间以便插入新数据,从而提高对空间的利用率。
- 进程间通信机制(IPC): PostgreSQL 是一个多进程系统,IPC 用来在多个后台进程间进行通信和消息传递。
- 大数据存储管理: 提供大对象和 TOAST 机制。大对象是一种由用户控制的大数据存储方法,它由用户调用函数,通过 SQL 语句直接向表中插入一个大尺寸文件。而 TOAST 机制则是在用户插入变长数据超过一定限度时自动触发的,用户无法对其加以控制。(但是可以更改存储模式,比如说)
读写元组过程
当一个 PostgreSQL 进程从数据库中读写一个元组时,对于以上各个功能模块的使用顺序如下图所示:
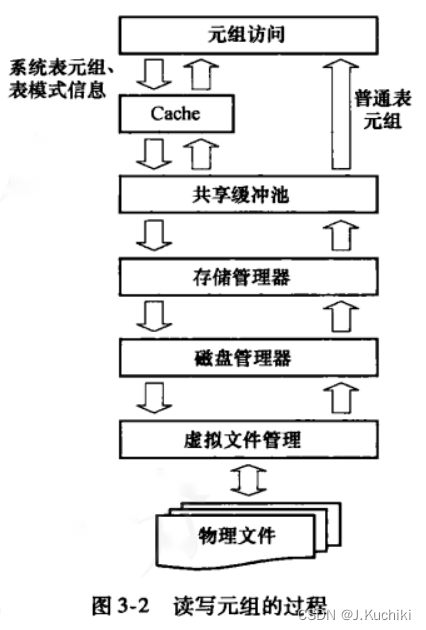
- 读取一个元组数据时,首先需要先获取表的基本信息,如表OID、索引信息以及统计信息,这些信息分散在多个系统表中。因此读写一个表需要访问多个系统表,但是这些每次都去读取系统表是没有必要的。因此每个进程在都会在本地内存区域设置两种 Cache,分别保存系统表元组与存储表的基本信息,从而使得进程能够快速地构建出表的基本信息和元组的模式结构。
- 获取表基本信息和元组的模式信息后,需要从元组所在的文件块中获取元组数据。这时首先判断元组所在的文件块是否在缓冲池里面,若是则直接返回,否则需要从存储介质中读取相应的文件块到缓冲区中,再从缓冲区中读取元组。
- 缓冲区与存储介质的交互是通过存储介质管理器(SMGR)进行。不同存储介质的底层实现各有差异,SMGR 负责统管各种存储介质,并对上层请求提供统一的接口,对下层则根据不同的介质调用相应的介质管理器,因此 SMGR 是 PostgreSQL 外存管理的核心。
- 在磁盘管理器与物理文件之间还存在一层虚拟文件描述符机制(VFD),这是为了防止PostgreSQL 打开的文件数超过 OS 限制而引起不可预知的错误。VFD 机制通过合理利用有限个实际文件描述符为 PostgreSQL 提供了虚拟的无限的文件描述符。
- 在写入元组的时候,当目标表的目标文件块容量不足时,需要查找该表中具有空闲区域的文件块读入内存。但是如果遍历该表所有的文件块,效率是很低的。为了加快查找的速度,PostgreSQL 为每个表增加了一个附属文件(FSM)用于记录每个文件块的空闲空间大小,通过一定的查找机制和数据组织实现文件块的快速选择。
- 在删除元组时,PostgreSQL 使用标记的方法快速处理。该元组的物理清除工作将由VACUUM 机制来完成。当然,如果 VACUUM 依次遍历所有的文件块也是非常慢的,于是 PostgreSQL 设计了一个可见性映射表(VM)来加快查找速度。
- 除了一般的数据外,PostgreSQL 还提供了大对象机制与 TOAST 机制存储大对象数据。前者发生在用户需要为数据库存储一个大文件时,PostgreSQL 为用户提供一个创建大对象的接口函数用于存储并获得一个大对象 OID。后者则主要用于变长字符串。