PostgreSQL是如何实现隔离级别的?
事务有哪些特性?
事务看起来感觉简单,但是要实现事务必须要遵守 4 个特性,分别如下:
- 原子性(Atomicity):一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节,而且事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样,就好比买一件商品,购买成功时,则给商家付了钱,商品到手;购买失败时,则商品在商家手中,消费者的钱也没花出去。
- 一致性(Consistency):是指事务操作前和操作后,数据满足完整性约束,数据库保持一致性状态。比如,用户 A 和用户 B 在银行分别有 800 元和 600 元,总共 1400 元,用户 A 给用户 B 转账 200 元,分为两个步骤,从 A 的账户扣除 200 元和对 B 的账户增加 200 元。一致性就是要求上述步骤操作后,最后的结果是用户 A 还有 600 元,用户 B 有 800 元,总共 1400 元,而不会出现用户 A 扣除了 200 元,但用户 B 未增加的情况(该情况,用户 A 和 B 均为 600 元,总共 1200 元)。
- 隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致,因为多个事务同时使用相同的数据时,不会相互干扰,每个事务都有一个完整的数据空间,对其他并发事务是隔离的。也就是说,消费者购买商品这个事务,是不影响其他消费者购买的。
- 持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务隔离
PostgreSQL 是如何保证isolation的? 接下来我们通过这篇文章来了解 PostgreSQL 如何实现事务隔离
标准SQL事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 可能 |
| 可串行化 | 不可能 | 不可能 | 不可能 |
SQL标准定义了四个级别的事务隔离。
各个级别不应该发生的现象是:
-
脏读
一个事务读取了另一个未提交事务写入的数据。
-
不可重复读
一个事务重新读取前面读取过的数据,发现该数据已经被另一个已经提交的事务修改。
-
幻读
一个事务重新执行一个查询,返回符合查询条件的行的集合,发现满足查询条件的行的集合因为其它最近提交的事务而发生了改变。
**在PostgreSQL里,你可以请求四种可能的事务隔离级别中的任意一种。但是在内部, 实际上只有三种独立的隔离级别,分别对应读已提交,可重复读和可串行化。**如果你选择了读未提交的级别, 实际上你获得的是读已提交,并且在PostgreSQL的可重复读实现中,幻读是不可能的, 所以实际的隔离级别可能比你选择的更严格。这是 SQL 标准允许的:四种隔离级别只定义了哪种现像不能发生, 但是没有定义那种现像一定发生。PostgreSQL只提供三种隔离级别的原因是, 这是把标准的隔离级别与多版本并发控制架构映射起来的唯一合理方法。
PostgreSQL实现的事务隔离等级如下表所示:
| 隔离等级 | 脏读 | 不可重复读 | 幻读 | 串行化异常 |
|---|---|---|---|---|
| 读已提交 | 不可能 | 可能 | 可能 | 可能 |
| 可重复读[1] | 不可能 | 不可能 | PG中不可能 | 可能 |
| 可串行化 | 不可能 | 不可能 | 不可能 | 不可能 |
PostgreSQL 在 MVCC 里如何工作的?
PostgreSQL事务标识
每当事务开始时,事务管理器就会为其分配一个称为**事务标识(transaction id, txid)**的唯一标识符。 PostgreSQL的txid是一个32位无符号整数,总取值约42亿。在事务启动后执行内置的txid_current()函数,即可获取当前事务的txid,如下所示。
testdb=# BEGIN;
BEGIN
testdb=# SELECT txid_current();
txid_current
--------------
100
(1 row)
PostgreSQL保留以下三个特殊txid:
- 0表示**无效(Invalid)**的
txid。 - 1表示**初始启动(Bootstrap)**的
txid,仅用于数据库集群的初始化过程。 - 2表示**冻结(Frozen)**的
txid.
txid可以相互比较大小。例如对于txid=100的事务,大于100的txid属于“未来”,且对于txid=100的事务而言都是**不可见(invisible)**的;小于100的txid属于“过去”,且对该事务可见,如下图(a)所示。
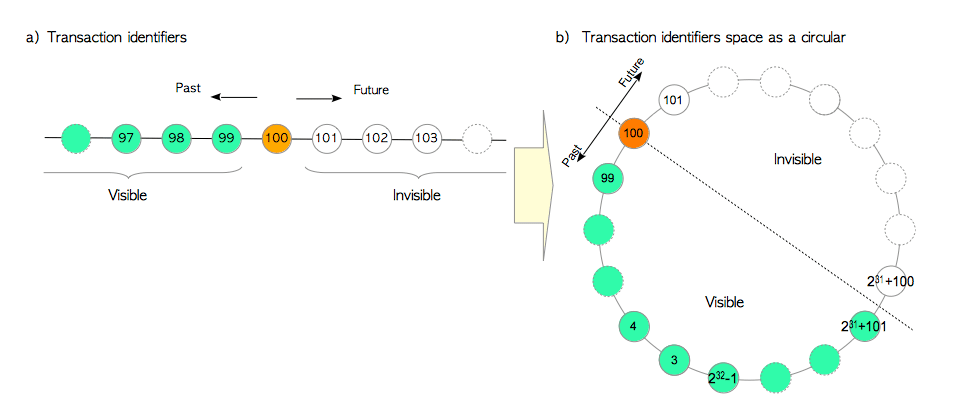
因为txid在逻辑上是无限的,而实际系统中的txid空间不足(4字节取值空间约42亿),因此PostgreSQL将txid空间视为一个环。对于某个特定的txid,其前约21亿个txid属于过去,而其后约21亿个txid属于未来。如(b)所示。
元组结构
可以将表页中的堆元组分为两类:普通数据元组与TOAST元组。本节只会介绍普通元组。
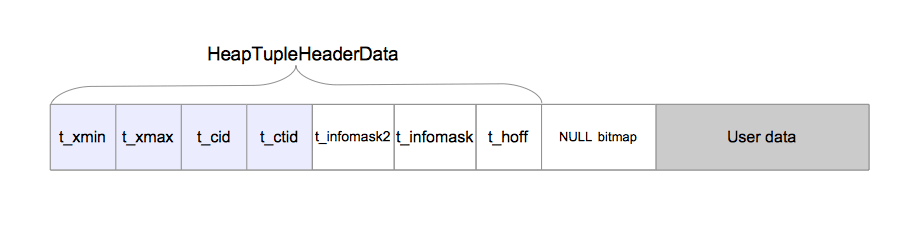
堆元组由三个部分组成,即HeapTupleHeaderData结构,空值位图,以及用户数据,如下图所示。
元组结构
HeapTupleHeaderData结构在src/include/access/htup_details.h中定义。
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* 插入事务的ID */
TransactionId t_xmax; /*删除或锁定事务的ID*/
union
{
CommandId t_cid; /* 插入或删除的命令ID */
TransactionId t_xvac; /* 老式VACUUM FULL的事务ID */
} t_field3;
} HeapTupleFields;
typedef struct DatumTupleFields
{
int32 datum_len_; /* 变长头部长度*/
int32 datum_typmod; /* -1或者是记录类型的标识 */
Oid datum_typeid; /* 复杂类型的OID或记录ID */
} DatumTupleFields;
typedef struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* 当前元组,或更新元组的TID */
/* 下面的字段必需与结构MinimalTupleData相匹配! */
uint16 t_infomask2; /* 属性与标记位 */
uint16 t_infomask; /* 很多标记位 */
uint8 t_hoff; /* 首部+位图+填充的长度 */
/* ^ - 23 bytes - ^ */
bits8 t_bits[1]; /* NULL值的位图 —— 变长的 */
/* 本结构后面还有更多数据 */
} HeapTupleHeaderData;
typedef HeapTupleHeaderData *HeapTupleHeader;
虽然HeapTupleHeaderData结构包含七个字段,但后续部分中只需要了解四个字段即可。
t_xmin保存插入此元组的事务的txid。t_xmax保存删除或更新此元组的事务的txid。如果尚未删除或更新此元组,则t_xmax设置为0,即无效。t_cid保存命令标识(command id, cid),cid意思是在当前事务中,执行当前命令之前执行了多少SQL命令,从零开始计数。例如,假设我们在单个事务中执行了三条INSERT命令BEGIN;INSERT;INSERT;INSERT;COMMIT;。如果第一条命令插入此元组,则该元组的t_cid会被设置为0。如果第二条命令插入此元组,则其t_cid会被设置为1,依此类推。t_ctid保存着指向自身或新元组的元组标识符(tid)。tid用于标识表中的元组。在更新该元组时,其t_ctid会指向新版本的元组;否则t_ctid`会指向自己。
元组的增删改查
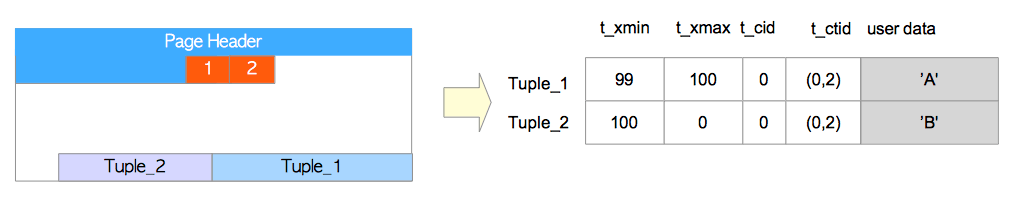
元组的具体表示如下图所示:
插入
在插入操作中,新元组将直接插入到目标表的页面中,如下图所示:
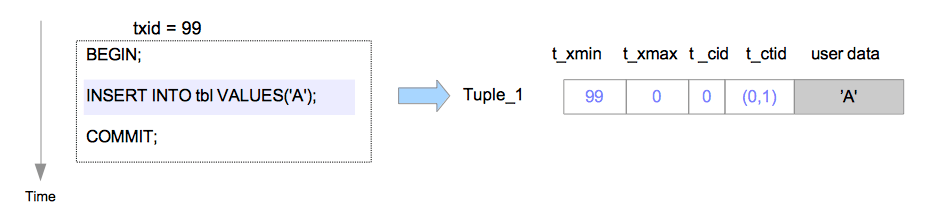
假设元组是由txid=99的事务插入页面中的,在这种情况下,被插入元组的首部字段会依以下步骤设置。
Tuple_1:
t_xmin设置为99,因为此元组由txid=99的事务所插入。t_xmax设置为0,因为此元组尚未被删除或更新。t_cid设置为0,因为此元组是由txid=99的事务所执行的第一条命令所插入的。t_ctid设置为(0,1),指向自身,因为这是该元组的最新版本。
pageinspectPostgreSQL自带了一个第三方贡献的扩展模块
pageinspect,可用于检查数据库页面的具体内容。testdb=# CREATE EXTENSION pageinspect; CREATE EXTENSION testdb=# CREATE TABLE tbl (data text); CREATE TABLE testdb=# INSERT INTO tbl VALUES(A); INSERT 0 1 testdb=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid FROM heap_page_items(get_raw_page(tbl, 0)); tuple | t_xmin | t_xmax | t_cid | t_ctid -------+--------+--------+-------+-------- 1 | 99 | 0 | 0 | (0,1) (1 row)
删除
在删除操作中,目标元组只是在逻辑上被标记为删除。目标元组的t_xmax字段将被设置为执行DELETE命令事务的txid。如下图所示:
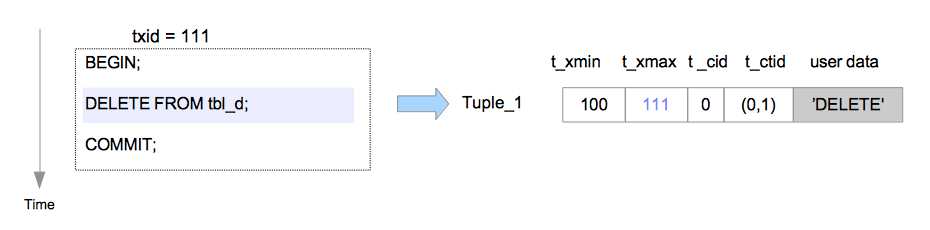 假设
假设Tuple_1被txid=111的事务删除。在这种情况下,Tuple_1的首部字段会依以下步骤设置。
Tuple_1:
t_xmax被设为111。
如果txid=111的事务已经提交,那么Tuple_1就不是必需的了。通常不需要的元组在PostgreSQL中被称为死元组(dead tuple)。
死元组最终将从页面中被移除。清除死元组的过程被称为清理(VACUUM)过程。
更新
在更新操作中,PostgreSQL在逻辑上实际执行的是删除最新的元组,并插入一条新的元组。
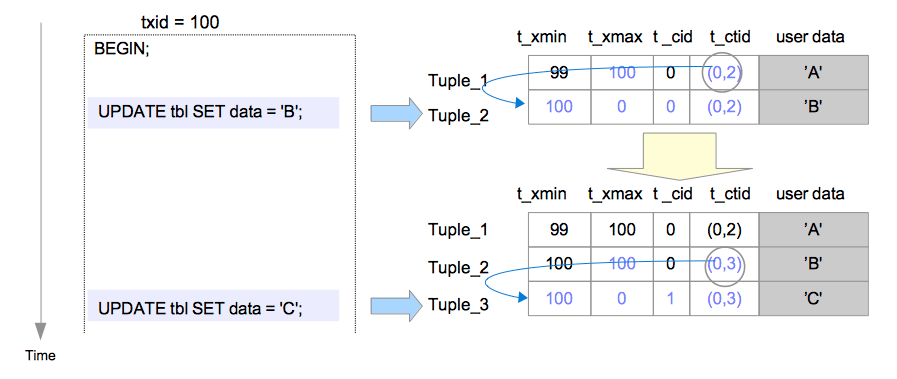
假设由txid=99的事务插入的行,被txid=100的事务更新两次。
当执行第一条UPDATE命令时,Tuple_1的t_xmax被设为txid 100,在逻辑上被删除;然后Tuple_2被插入;接下来重写Tuple_1的t_ctid以指向Tuple_2。Tuple_1和Tuple_2的头部字段设置如下。
Tuple_1:
t_xmax被设置为100。t_ctid从(0,1)被改写为(0,2)。
Tuple_2:
t_xmin被设置为100。t_xmax被设置为0。t_cid被设置为0。t_ctid被设置为(0,2)。
当执行第二条UPDATE命令时,和第一条UPDATE命令类似,Tuple_2被逻辑删除,Tuple_3被插入。Tuple_2和Tuple_3的首部字段设置如下。
Tuple_2:
t_xmax被设置为100。t_ctid从(0,2)被改写为(0,3)。
Tuple_3:
t_xmin被设置为100。t_xmax被设置为0。t_cid被设置为1。t_ctid被设置为(0,3)。
与删除操作类似,如果txid=100的事务已经提交,那么Tuple_1和Tuple_2就成为了死元组,而如果txid=100的事务中止,Tuple_2和Tuple_3就成了死元组。
提交日志(clog)
PostgreSQL在提交日志(Commit Log, clog)中保存事务的状态。提交日志(通常称为clog)分配于共享内存中,并用于事务处理过程的全过程。
事务状态
PostgreSQL定义了四种事务状态,即:IN_PROGRESS,COMMITTED,ABORTED和SUB_COMMITTED。
前三种状态涵义显而易见。例如当事务正在进行时,其状态为IN_PROGRESS,依此类推。
SUB_COMMITTED状态用于子事务。
提交日志如何工作
提交日志(下称clog)在逻辑上是一个数组,由共享内存中一系列8KB页面组成。数组的序号索引对应着相应事务的标识,而其内容则是相应事务的状态。clog的工作方式如下图所示:
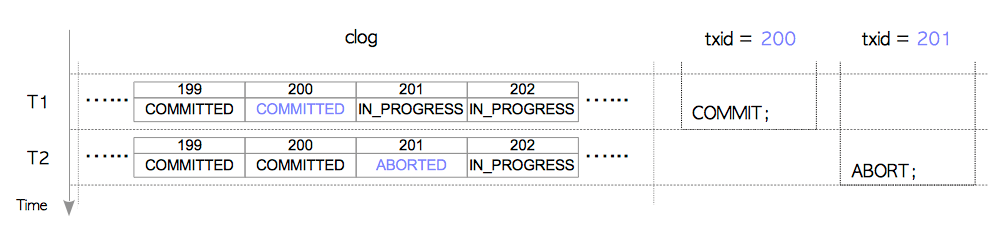
T1:
txid 200提交;txid 200的状态从IN_PROGRESS变为COMMITTED。 T2:txid 201中止;txid 201的状态从IN_PROGRESS变为ABORTED。
txid不断前进,当clog空间耗尽无法存储新的事务状态时,就会追加分配一个新的页面。
当需要获取事务的状态时,PostgreSQL将调用相应内部函数读取clog,并返回所请求事务的状态。
事务快照
**事务快照(transaction snapshot)**是一个数据集,存储着某个特定事务在某个特定时间点所看到的事务状态信息:哪些事务处于活跃状态。这里活跃状态意味着事务正在进行中,或还没有开始。
事务快照在PostgreSQL内部的文本表示格式定义为100:100:。举个例子,这里100:100:意味着txid < 100的事务处于非活跃状态,而txid ≥ 100的事务处于活跃状态。
内置函数
txid_current_snapshot及其文本表示函数
txid_current_snapshot显示当前事务的快照。testdb=# SELECT txid_current_snapshot(); txid_current_snapshot ----------------------- 100:104:100,102 (1 row)
txid_current_snapshot的文本表示是xmin:xmax:xip_list,各部分描述如下。
xmin最早仍然活跃的事务的
txid。所有比它更早的事务txid < xmin要么已经提交并可见,要么已经回滚并生成死元组。
xmax第一个尚未分配的
txid。所有txid ≥ xmax的事务在获取快照时尚未启动,因而其结果对当前事务不可见。
xip_list获取快照时活跃事务的
txid列表。该列表仅包括xmin与xmax之间的txid。例如,在快照
100:104:100,102中,xmin是100,xmax是104,而xip_list为100,102。以下显示了两个具体的示例:
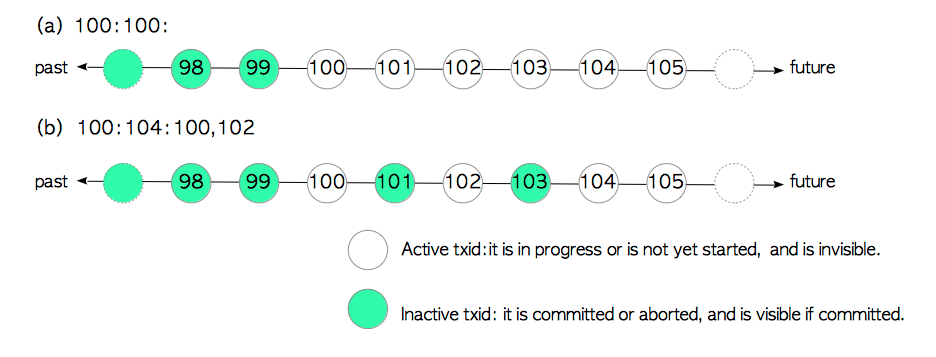
事务快照的表示样例
第一个例子是
100:100:,如图图(a)所示,此快照表示:
- 因为
xmin为100,因此txid < 100的事务是非活跃的- 因为
xmax为100,因此txid ≥ 100的事务是活跃的第二个例子是
100:104:100,102,如图(b)所示,此快照表示:
txid < 100的事务不活跃。txid ≥ 104的事务是活跃的。txid等于100和102的事务是活跃的,因为它们在xip_list中,而txid等于101和103的事务不活跃。
**事务快照是由事务管理器提供的。在READ COMMITTED隔离级别,事务在执行每条SQL时都会获取快照;其他情况下(REPEATABLE READ或SERIALIZABLE隔离级别),事务只会在执行第一条SQL命令时获取一次快照。**获取的事务快照用于元组的可见性检查。
使用获取的快照进行可见性检查时,所有活跃的事务都必须被当成IN PROGRESS的事务等同对待,无论它们实际上是否已经提交或中止。这条规则非常重要,因为它正是READ COMMITTED和REPEATABLE READ/SERIALIZABLE隔离级别中表现差异的根本来源,我们将在接下来几节中频繁回到这条规则上来。
如下图所示:
事务管理器与事务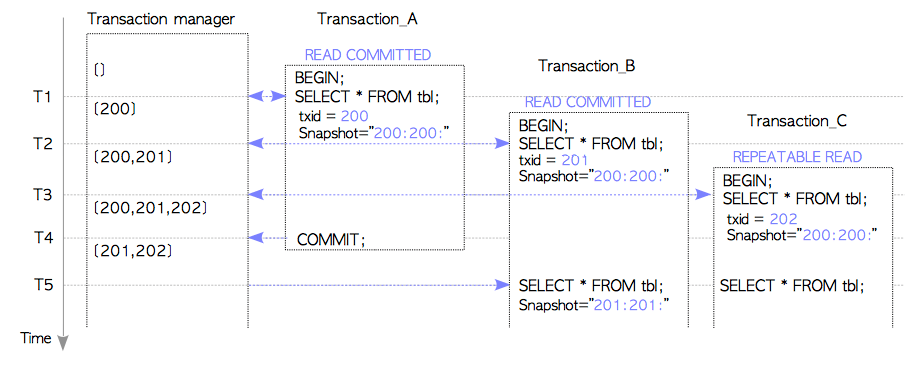
事务管理器始终保存着当前运行的事务的有关信息。假设三个事务一个接一个地开始,并且Transaction_A和Transaction_B的隔离级别是READ COMMITTED,Transaction_C的隔离级别是REPEATABLE READ。
-
T1:
Transaction_A启动并执行第一条SELECT命令。执行第一个命令时,Transaction_A请求此刻的txid和快照。在这种情况下,事务管理器分配txid=200,并返回事务快照200:200:。 -
T2:
Transaction_B启动并执行第一条SELECT命令。事务管理器分配txid=201,并返回事务快照200:200:,因为Transaction_A(txid=200)正在进行中。因此无法从Transaction_B中看到Transaction_A。 -
T3:
Transaction_C启动并执行第一条SELECT命令。事务管理器分配txid=202,并返回事务快照200:200:,因此不能从Transaction_C中看到Transaction_A和Transaction_B。 -
T4:
Transaction_A已提交。事务管理器删除有关此事务的信息。 -
T5:
Transaction_B和Transaction_C执行它们各自的SELECT命令。Transaction_B需要一个新的事务快照,因为它使用了READ COMMITTED隔离等级。在这种情况下,Transaction_B获取新快照201:201:,因为Transaction_A(txid=200)已提交。因此Transaction_A的变更对Transaction_B可见了。Transaction_C不需要新的事务快照,因为它处于REPEATABLE READ隔离等级,并继续使用已获取的快照,即200:200:。因此,Transaction_A的变更仍然对Transaction_C不可见。
总结
PostgreSQL 是支持事务的,事务的四大特性是原子性、一致性、隔离性、持久性,我们这次主要讲了隔离性。
当多个事务并发执行的时候,会引发脏读、不可重复读、幻读这些问题,那为了避免这些问题,SQL 提出了四种隔离级别,分别是读未提交、读已提交、可重复读、串行化,从左往右隔离级别顺序递增,隔离级别越高,意味着性能越差,PostgreSQL 引擎的默认隔离级别是读已提交。
**在PostgreSQL里,你可以请求四种可能的事务隔离级别中的任意一种。但是在内部, 实际上只有三种独立的隔离级别,分别对应读已提交,可重复读和可串行化。**如果你选择了读未提交的级别, 实际上你获得的是读已提交,并且在PostgreSQL的可重复读实现中,幻读是不可能的, 所以实际的隔离级别可能比你选择的更严格。
而对于幻读现象,不建议将隔离级别升级为串行化,因为这会导致数据库并发时性能很差。PostgreSQL 引擎的默认隔离级别虽然是「读已提交」
PostgreSQL 事务快照是由事务管理器提供的。在READ COMMITTED隔离级别,事务在执行每条SQL时都会获取快照;其他情况下(REPEATABLE READ或SERIALIZABLE隔离级别),事务只会在执行第一条SQL命令时获取一次快照。获取的事务快照用于元组的可见性检查;
参考资料
- [1] Abraham Silberschatz, Henry F. Korth, and S. Sudarshan, “Database System Concepts”, McGraw-Hill Education, ISBN-13: 978-0073523323
- [2] Dan R. K. Ports, and Kevin Grittner, “Serializable Snapshot Isolation in PostgreSQL”, VDBL 2012
- [3] Thomas M. Connolly, and Carolyn E. Begg, “Database Systems”, Pearson, ISBN-13: 978-0321523068
- [4] PostgreSQL指南:内幕探索
- [5] PostgreSQL 9.4.4 中文手册
- [6] 事务隔离级别是怎么实现的?