How PostgreSQL writes data
在我们更详细地讨论检查点之前,了解PostgreSQL如何写数据是很重要的。让我们看一下下面的图片。
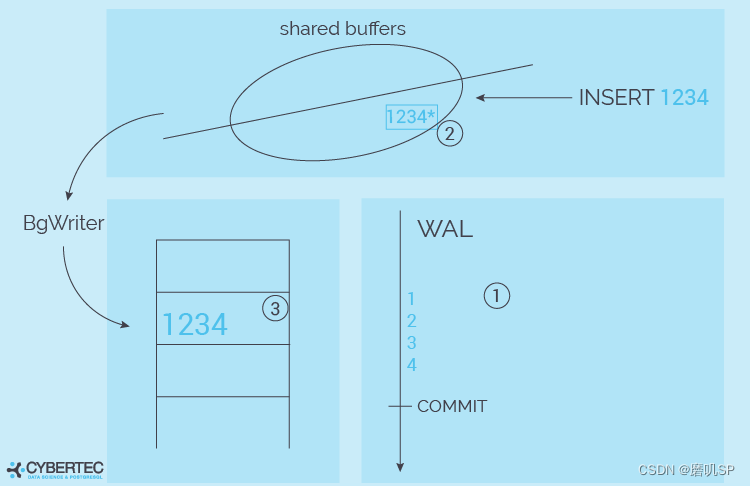
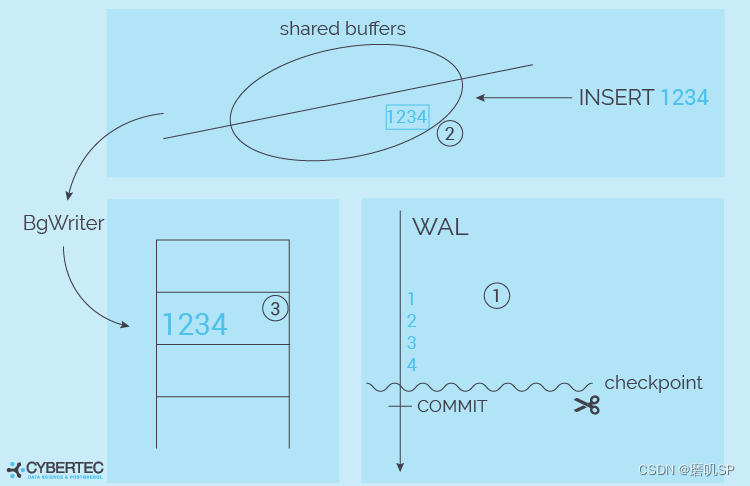
最重要的是,我们必须假设崩溃可能在任何时候发生。为什么会有这样的关系?嗯,我们要确保你的数据库永远不会被破坏。其后果是,我们不能直接向数据文件写数据。这是为什么呢?假设我们想写 "1234 "到数据文件。如果我们在 "12 "之后崩溃了怎么办?其结果将是在表的某个地方出现断裂的行。也许索引项会丢失,等等–我们必须不惜一切代价来防止这种情况。
因此,有必要采用更复杂的方式来写入数据。它是如何工作的呢?PostgreSQL做的第一件事就是把数据发送到WAL(=Write Ahead Log)。WAL就像一个偏执的顺序磁带,包含二进制变化。如果增加了一行,WAL可能包含一条记录,表明数据文件中的一行必须被改变,它可能包含几条指令来改变索引条目,也许需要写一个额外的块,等等。它只是包含一个变化的流。
一旦数据被发送到WAL,PostgreSQL将对共享缓冲区中的块的缓存版本进行修改。注意,数据仍然不在数据文件中。我们现在有了WAL条目以及对共享缓冲区的修改。如果一个读取请求进来,它无论如何也不会进入数据文件–因为数据是在缓冲区中找到的。
在某些时候,这些修改过的内存页面会被后台写程序写入磁盘。这里重要的是,数据可能会被写错顺序,这没有问题。请记住,如果用户想读取数据,PostgreSQL会在向操作系统索取数据块之前检查共享缓冲区。因此,脏块的写入顺序并不那么相关。甚至晚一点写数据也是有意义的,这样可以增加在一次I/O请求中向磁盘发送许多变化的几率。
Getting rid of WAL
然而,我们不能无限期地将数据写入WAL中。在某些时候,空间必须被回收。这正是检查点的作用。
检查点的目的是确保到某一时刻为止创建的所有脏缓冲区都被写到磁盘上,这样到该时刻为止的WAL就可以被回收了。PostgreSQL的方法是启动一个检查点进程,将那些可能丢失的变化(还是share buffers)写到磁盘上。然而,这个进程并没有尽可能快地将数据发送到磁盘。原因是我们想把I/O曲线拉平,以保证稳定的响应时间。
test=# SHOW checkpoint_completion_target;
checkpoint_completion_target
------------------------------
0.5
(1 row)
这个参数的意思是:一个检查点完成一半后,下一个检查点才有望启动。
在生产中,0.7 - 0.9的值似乎是大多数工作负载的最佳选择,但可以试验一下。
注意:在PostgreSQL 14中,这个参数很可能不再存在了。硬编码的值将是0.9,
这将使终端用户更容易接受。
下一个重要问题是:检查点何时真正启动?有一些参数可以控制这种行为。
test=# SHOW checkpoint_timeout;
checkpoint_timeout
--------------------
5min
(1 row)
test=# SHOW max_wal_size;
max_wal_size
--------------
1GB
(1 row)
如果你的系统的负载很低,检查点会在一定时间后发生。默认值是5分钟。然而,我们建议增加这个值以优化写入性能。
max_wal_size是一个比较棘手的问题:首先,这是一个软限制–不是一个硬限制。所以,要做好准备。WAL的数量可以超过这个数字。这个参数的意思是告诉PostgreSQL它可能积累多少WAL,并相应地调整检查点。一般的规则是:增加这个值会导致更多的空间消耗,但同时也会提高写入性能。
那么,为什么不直接将max_wal_size设置为无穷大呢?第一个原因很明显:你将需要大量的空间。然而,还有更多的原因–在你的数据库崩溃的情况下,PostgreSQL必须重复上次检查点以来的所有变化。换句话说,在崩溃之后,你的数据库可能需要更长的时间来恢复–由于自上次检查点以来积累了大量的WAL。从正面看,如果增加检查点的距离,性能确实有所提高–但是,可以做的和实现的东西是有限的。在某些时候,在问题上投入更多的存储并不能改变什么。
background writer正在向磁盘写入一些脏块。然而,在许多情况下,更多的工作是由检查点进程本身完成的。因此,把注意力放在检查点上比放在优化后台写程序上更有意义。
min_wal_size: The mysterious parameter
人们经常询问min_wal_size和max_wal_size的含义。关于这两个参数,外面有很多混乱的说法。让我试着解释一下这里发生了什么。如前所述,PostgreSQL会自行调整其检查点距离。它试图使WAL保持在max_wal_size以下。然而,如果你的系统是空闲的,PostgreSQL将逐渐减少WAL的数量,再次一直减少到min_wal_size。这不是一个快速的过程–它是逐渐发生的,在很长的一段时间内。
让我们假设一个简单的场景来说明这个情况。假设你有一个系统,在一周内有很大的写入负荷,但在周末闲置。周五下午,WAL的大小因此很大。然而,在周末,PostgreSQL会逐渐减少WAL的大小。当周一负载再次增加时,那些丢失的WAL文件将被重新创建(从性能上讲,这可能是一个问题)。
因此,不要把min_wal_size设置得太低(与max_wal_size相比),以减少在负载再次增加时创建新的WAL文件的需要,可能是一个好主意。