optimizer_README_0">optimizer README
src/backend/optimizer/README长达1000行,6万多个字母,翻译出来中文2万字,本身就硬核,不翻译出来都看不下去。这段优化器的README主要描述planner的源码结构和逻辑,以及简单介绍并行和partition wise join/aggregate,对于理解planner的源码非常有帮助。这里仅做全文翻译,翻译过程中也会敲重点和批注:
原文重点
自己添加的解读
重点&解读
Optimizer
#optimizer源码的结构
optimizer/
|--geqo/
|--path/
|--plan/
|--prep/
这些目录采用解析器返回的查询结构(query tree),并生成执行程序使用的计划(plan)。 /plan 目录生成
实际的输出计划,/path 生成所有可能的连接表的方法,/prep 处理特殊情况下的各种预处理步骤。 /geqo 是单独的“遗传优化”planner—它通过join tree空间进行半随机搜索,而不是详尽地考虑所有可能的join tree。 (但是 /geqo 考虑的每个连接(join)都会提供给 /path 来创建路径,因此即使在 GEQO 模式下,我们也会考虑每个特定连接(join)对应所有可能的路径。)
Paths and Join Pairs
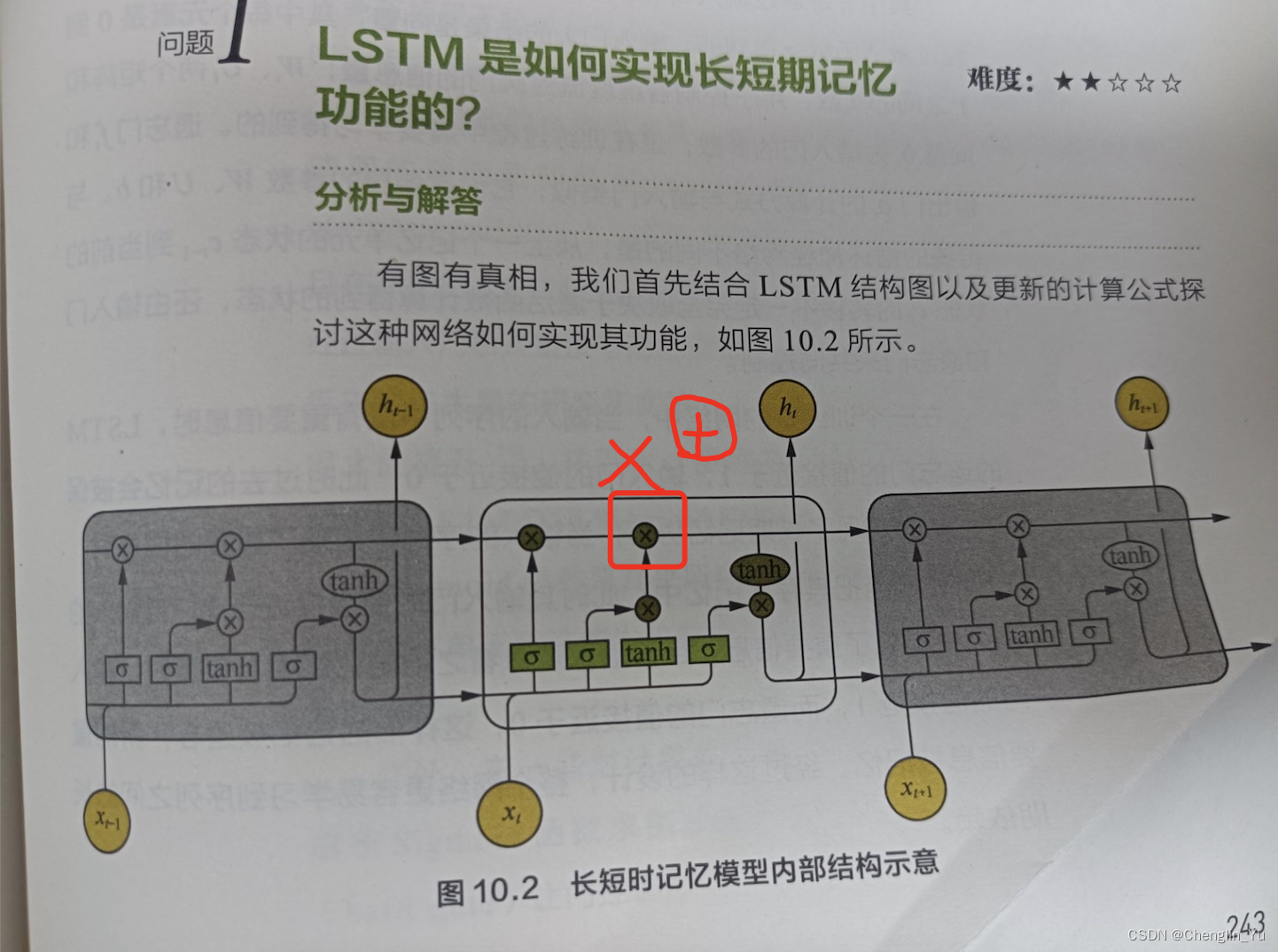
在planning/optimizing过程中,我们构建“路径”树(“Path” trees),代表执行查询的不同方式。 我们选择生成所需关系的最低代价路径,并将其转换为要传递给executor的计划。 (路径和计划树之间几乎是一对一的对应关系,但路径节点省略了规划期间不需要的信息,并包含执行者不需要的计划所需的信息。(path tree≈plan tree)
optimizer为查询中使用的每个基本relation构建一个 RelOptInfo 结构。 基本relation要么是原始表,要么是通过递归调用计划而来的子查询。 也会为planning期间考虑的每个join relation构建一个 RelOptInfo。join relation只是基本relation的组合。 对于任何给定的基本rels,只有一个连接 RelOptInfo,例如,join {A B C} 由相同的 RelOptInfo 表示,无论我们是先连接 A 和 B 然后添加 C,还是先连接 B 和 C 然后添加 A来构建它。 这些构建 Joinrel 的不同方法就是路径Path。 对于每个 RelOptInfo,我们都会构建一个路径列表,这些路径表示实现该关系的扫描或连接的合理方法。一旦我们为一个rel考虑完了所有合理的路径,我们就根据planner的成本估算选择最便宜(cheapest)的路径。 最终计划派生自 RelOptInfo 的最便宜路径,其中包含了查询所需的所有基本 rel。
原始表的可能路径包括顺序扫描(plain old sequential scan)、表上存在的任何索引的索引扫描(index scans ),以及使用一个或多个索引的位图索引扫描( bitmap index scans )。 专用 RTE 类型(如函数 RTE)可能只有一个可能的路径。
joins始终使用两个 RelOptInfos 进行连接。 一个是外在的(驱动表),另一个是内在的(被驱动表)。外部驱动内部查找值。 在嵌套循环(nested loop)中,每扫描一次外部元组,都会驱动内部路径以查找每个匹配的内部行的值。 在合并联接(mergejoin)中,内行和外行是按顺序排序和访问的,因此只需一次扫描即可执行整个联接:同步扫描内部和外部路径。 在合并联接中,内部和外部之间没有太大区别…。 在哈希连接中,首先扫描内部,将其所有行输入到哈希表中,然后扫描外部,对于每一行,我们在哈希表中查找连接键。
联接relation的 Path 实际上是一个树结构,最顶层的 Path 节点表示最后应用的联接方法。 它具有左子路径和右子路径,这些子路径表示用于两个输入关系的扫描或联接方法。
Join Tree Construction
optimizer通过执行或多或少的执行查询的详尽搜索来生成最佳查询计划。 最好的路径树(path tree)是通过递归过程找到的:
1) 获取查询中的每个基本关系,并为其创建一个 RelOptInfo 结构。 查找访问关系的每种可能有用的方法,包括顺序扫描和索引扫描,并使 Path 表示这些方式。为给定关系创建的所有路径都放置在其 RelOptInfo.pathlist中 。 (实际上,我们在路径进入pathlist之前会丢弃明显较差的路径—最终出现在路径列表中的路径是生成的每个潜在有用的排序和relation参数化的最廉价的方法。 还要创建一个 RelOptInfo.joininfo 列表,其包含涉及此relation的所有join子句。 例如,WHERE 子句 “tab1.col1 = tab2.col1” 在joininfo列表中生成 tab1 和 tab2 两个条目。
如果我们在查询中只有一个基本relation,那我们完成了。否则,我们必须弄清楚如何将基础relation连接成单个join relation。
2)通常,任何显式的JOIN子句都是“扁平化的”,因此我们只有一个要连接的关系列表。 但是,如果展平过程因join_collapse_limit或from_collapse_limit限制而停止,则FULL OUTER JOIN子句永远不会平展,其他类型的 JOIN 也可能不会被展平。 因此,我们最终会遇到一个计划问题,即是按任何顺序连接的关系列表,其中任何单个关系都可能是必须连接在一起的子列表,然后我们才能考虑将其连接到其同级。我们自下而上递归地处理这些子问题。 请注意,join list结构约束了可能的联接顺序,但它不会约束每个联接(nestloop、merge、hash)的联接实现方法,也不会说明在每个联接时哪个 rel 被视为外部或内部。 我们在构建路径时考虑了所有这些可能性。我们为每个可行的连接方法生成一个路径,并选择最便宜的路径。
因此,对于每个planning问题,我们将有一个关系列表,这些关系要么是基本关系,要么是每个子连接列表构造的连接关系。我们可以按照planner认为合适的任何顺序将这些关系连接在一起。标准(非GEQO)planner按如下方式执行此操作:
考虑将每个 RelOptInfo 连接到每个有join子句的 RelOptInfo,并为每个这样的配对生成所有可能的连接方式的路径。 (如果我们有一个没有连接子句的 RelOptInfo,我们别无选择,只能生成一个无子句的笛卡尔积连接;所以我们考虑将该 rel 连接到彼此可用的 rel。 但是,如果存在join子句,我们将只考虑使用可用的join子句的join。 请注意,还会检查由外连接和 IN/EXISTS 子句引起的连接顺序的限制,以确保在这些限制强制 执行无子句连接的情况下 找到可行的连接顺序。)
如果我们在列表中只有两个关系,我们就完成了:我们只需选择cheapest的路径加入 RelOptInfo。 如果我们有两个以上,我们现在需要考虑将 RelOptInfos 相互连接的方式,以使代表两个以上列表项的 RelOptInfos 加入。
连接树是使用“动态规划”算法构造的:在第一次传递(已经描述)中,我们考虑创建仅表示两个列表项的连接 rel 的方法。 第二次考虑创建正好表示三个列表项的联接 rel 的方法;下一遍,四个项目,等等。 最后一遍考虑如何建立包含所有列表项的最终联接关系 —显然,在此顶层只能有一个联接 rel,而在较低级别可以有多个联接 rel。 如果可能,在每个级别上,我们使用遵循可用连接子句的连接,就像第一级所述一样。
For example:
SELECT *
FROM tab1, tab2, tab3, tab4
WHERE tab1.col = tab2.col AND
tab2.col = tab3.col AND
tab3.col = tab4.col
Tables 1, 2, 3, and 4 are joined as:
{1 2},{2 3},{3 4}
{1 2 3},{2 3 4}
{1 2 3 4}
(other possibilities will be excluded for lack of join clauses)
SELECT *
FROM tab1, tab2, tab3, tab4
WHERE tab1.col = tab2.col AND
tab1.col = tab3.col AND
tab1.col = tab4.col
Tables 1, 2, 3, and 4 are joined as:
{1 2},{1 3},{1 4}
{1 2 3},{1 3 4},{1 2 4}
{1 2 3 4}
我们考虑左边的计划(upper join的the outer rel是joinrel,但inner始终是单个list item);右边的计划(outer rel始终是单个item);浓密(bushy)的计划(内部和外部都可以自己连接)。 例如,在构建 {1 2 3 4} 时,我们考虑将 {1 2 3} 连接到 {4}(左手边),{4}连接到 {1 2 3}(右手),将 {1 2} 连接到 {3 4}(bushy),以及其他选择。 尽管 jointree 扫描代码一次生成一个潜在的连接组合,但生成同一组连接基本 rel 的所有方法都将共享相同的 RelOptInfo,因此从产生等效连接的不同连接组合生成的路径,将在 add_path() 中竞争(没懂啥意思)。
动态规划方法有一个不是很明显但很重要的属性:在我们为所有relation构造path之后,我们构造任何包含这些rels的relation path。这意味着我们可以在需要知道上级关系之前可靠地确定每个rel的“最廉价路径”。 此外,当我们发现同一 rel 的另一条path更好时,我们可以安全地丢弃一条path,而不必担心在某些更高级别的连接路径中可能已经存在该路径的引用。 如果没有这个,路径的内存管理将更加复杂。
一旦我们构建了最终的join rel,我们就使用最廉价的路径或具有所需排序的最便宜的路径(如果这比将排序应用于其他最廉价的路径还廉价)。
如果查询包含单侧外连接(LEFT 或 RIGHT 连接),或者包含转换为半连接或反连接的 IN 或 EXISTS WHERE 子句,则某些可能的联接顺序可能是非法的。 通过oin_is_legal查阅此类“特殊”join的部分list以查看所建议join是否非法,从而可以排除这种非法情况。 (相同的查阅允许它查看应将哪种连接样式应用于有效的连接,即JOIN_INNER、JOIN_LEFT等)
Valid OUTER JOIN Optimizations
planner对外连接重新排序的处理基于以下标识:
- (A leftjoin B on (Pab)) innerjoin C on (Pac)
= (A innerjoin C on (Pac)) leftjoin B on (Pab)
其中 Pac 是引用 A 和 C 的谓词(在这种情况下,显然 Pac 不能引用 B,不然转换是无意义的)。
-
(A leftjoin B on (Pab)) leftjoin C on (Pac)
= (A leftjoin C on (Pac)) leftjoin B on (Pab) -
(A leftjoin B on (Pab)) leftjoin C on (Pbc)
= A leftjoin (B leftjoin C on (Pbc)) on (Pab)
仅当谓词 Pbc在B是all-null情况必须失效时,标识 3 才成立(即,Pbc 至少对 B 的一列是严格的)。 如果 Pbc 不严格,则第一种形式可能会生成一些包含非空 C 列的行,而第二种形式将使这些条目为 null。
切换两个输入表后的 RIGHT JOIN 等效于 LEFT JOIN,因此相同的标识适用于右连接。
一个不工作的情况是将内部连接移入或移出外部连接的可为空端(nullable side):
A leftjoin (B join C on (Pbc)) on (Pab)
!= (A leftjoin B on (Pab)) join C on (Pbc)
SEMI joins的工作方式略有不同。 半连接可以重新关联到另一个半连接、左连接或反连接的左侧或从左侧重新关联,但不能重新关联到右侧或从右侧重新关联。 同样,内联接、左联接或反联接可以重新关联到半联接的左侧或从半联接的左侧重新关联,但不能重新关联到右侧或从右侧重新关联。(眩晕!!总之是join的逻辑转换)
ANTI joins的工作方式与 LEFT join大致类似,只是如果对 C 的连接是反连接,则恒等式 3 会失败(即使 Pbc 是严格的,并且在另一个连接是左连接和反连接这两种情况下)。 因此,我们不能将反连接重新排序到左连接或反连接的 RHS 中或从中取出,即使相关子句很严格。
当前代码根本不会尝试对full join的重新排序。FULL JOIN 排序是通过在将 JOINTREE 转换为 “joinlist” 形式时不折叠 FULL JOIN 节点来强制执行的。其他类型的 JOIN 节点通常处于折叠状态,以便它们完全参与连接顺序的搜索。为了避免生成非法连接顺序,计划程序为每个非inner join创建一个 SpecialJoinInfo 节点,join_is_legal检查此列表以确定建议的连接是否合法。
我们存储在SpecialJoinInfo 节点中的是连接的每一侧形成外部连接所需的最小 Relid 集。 请注意,这些是最小值,没有明确的最大值,因为 joining 其他rels到OJ的语法rels中可能是合法的。 根据标识 1 和 2,非 FULL join可以自由关联到 OJ 的左侧,但在某些情况下,它们不能关联到右侧。因此,join_is_legal强制执行的限制是,建议的join不能将 RHS 边界内(或部分内)的 rel join到边界外的 rel,除非提议的join是可以使用标识 3 关联到SpecialJoinInfo的RHS的LEFT join。
使用最小 Relid 集有一些陷阱,考虑一个这样的查询:
A leftjoin (B leftjoin (C innerjoin D) on (Pbcd)) on Pa
其中 Pa 根本没有提到 B/C/D。 在这种情况下,朴素计算会将左上连接的最小 LHS 作为 {A},将最小 RHS 作为 {C,D}(因为我们知道inner join不能关联出left join的 RHS,并通过将其relid包含在左连接的最小 RHS 中来强制执行)。 左下角的最小 LHS 为 {B},最小 RHS 为 {C,D}。 有了这些信息,join_is_legal会认为可以将上联接关联到下联接的 RHS 中,从而将查询转换为
B leftjoin (A leftjoin (C innerjoin D) on Pa) on (Pbcd)
这会产生完全错误的结果。 我们通过强制upper join的最小 RHS 包含 B 来防止这种情况。 这可能过于严格,但这种情况并不经常出现,因此不清楚是否值得开发更复杂的系统。
Pulling Up Subqueries
如上所述,出现在范围表(range table)中的子查询是独立规划的,并在规划外部查询期间被视为“黑盒”。 当子查询使用聚合、GROUP 或 DISTINCT 等功能时,这是必需的。 但是,如果子查询只是一个简单的扫描或连接,则与将其视为整个计划搜索空间的一部分相比,将子查询视为黑盒可能会产生较差的计划。因此,在计划过程开始时,计划器查找简单的子查询,并将它们拉到主查询的jointree中。
拉出子查询可能会导致FROM-list联接显示在jointree顶部下面。 每个FROM-list都是使用上述动态规划搜索方法规划的。 如果拉出一个子查询会产生一个 FROM-list作为另一个 FROM-list 的直接子级,那么我们可以将两个 FROM 列表合并在一起。 完成此操作后,子查询是外部查询的绝对组成部分,根本不会限制jointree搜索空间。 但是,这可能会导致计划时间不愉快低增长,因为动态编程搜索在运行时所考虑的 FROM 项数量呈指数级增长。因此,如果结果在一个列表中包含太多 FROM 项,我们不会合并 FROM 列表。
Optimizer Functions
主入口函数是planner()(planner()的解释,非常关键)
planner()
设置为递归处理子查询
-subquery_planner()
如果可能,从范围表中提取子链接和子查询
canonicalize qual 规范化qual
尝试将WHERE子句简化为最有用的形式;这包括
展平嵌套的 AND/OR,并检测在 OR 的不同分支中重复的子句。
简化常量表达式
处理子链接
将outer query级别的Vars转换为Params
--grouping_planner()
非SELECT查询的预处理target list
处理UNION/INTERSECT/EXCEPT, GROUP BY, HAVING,aggregates,ORDER BY, DISTINCT, LIMIT
---query_planner()
创建查询中使用的base relations列表
将qual拆分为restrictions (a=1) and joins (b=c)
查找启用merge和hash join的qual子句
----make_one_rel()
set_base_rel_pathlists()
查找每个base relation的SeqScan和所有索引路径
查找join中使用的列的选择率
make_rel_from_joinlist()
将连接子问题移交给plugin、GEQO or standard_join_search()
------standard_join_search()
为所需的每个join tree level调用join_search_one_level()
join_search_one_level():
对于前一级别的每个连接,如果它有连接子句,则执行 make_rels_by_clause_joins(),
如果没有,则执行make_rels_by_clauseless_joins()。
在较低级别的joinrels之间生成“bushy plan” join。
回到standard_join_search(),如果需要为每个新构建的joinrel生成gather paths,
然后应用set_cheapest()为其提取最佳的路径。
如果这不是top join level,Loop back。
回到grouping_planner:
执行分组(GROUP BY)和聚合
执行窗口函数
执行去重(DISTINCT)
进行排序(ORDER BY)
执行limit(LIMIT/OFFSET)
回到planner():
将完成的Path tree转换为Plan tree
执行计划后的最后清理
Optimizer Data Structures
PlannerGlobal - 单个planer调用的全局信息
PlannerInfo - information for planning a particular Query(我们为每个子查询造一个的单独PlannerInfo节点)
RelOptInfo - a relation or joined relations
RestrictInfo - WHERE 子句,如“x = 3”或“y = z”(请注意,restriction和join子句使用相同的结构)
Path - 生成RelOptInfo(sequential,index,joins)的每个路径
一个一般的Path节点可以代表多个简单计划,每个都是pathtype:
T_SeqScan - sequential scan
T_SampleScan - tablesample scan
T_FunctionScan - function-in-FROM scan
T_TableFuncScan - table function scan
T_ValuesScan - VALUES scan
T_CteScan - CTE (WITH) scan
T_NamedTuplestoreScan - ENR scan
T_WorkTableScan - scan worktable of a recursive CTE
T_Result - childless Result plan node (used for FROM-less SELECT)
IndexPath - index scan
BitmapHeapPath - top of a bitmapped index scan
TidPath - scan by CTID
TidRangePath - scan a contiguous range of CTIDs
SubqueryScanPath - scan a subquery-in-FROM
ForeignPath - scan a foreign table, foreign join or foreign upper-relation
CustomPath - for custom scan providers
AppendPath - append multiple subpaths together
MergeAppendPath - merge multiple subpaths, preserving their common sort order
GroupResultPath - childless Result plan node (used for degenerate grouping)
MaterialPath - a Material plan node
MemoizePath - a Memoize plan node for caching tuples from sub-paths
UniquePath - remove duplicate rows (either by hashing or sorting)
GatherPath - collect the results of parallel workers
GatherMergePath - collect parallel results, preserving their common sort order
ProjectionPath - a Result plan node with child (used for projection)
ProjectSetPath - a ProjectSet plan node applied to some sub-path
SortPath - a Sort plan node applied to some sub-path
IncrementalSortPath - an IncrementalSort plan node applied to some sub-path
GroupPath - a Group plan node applied to some sub-path
UpperUniquePath - a Unique plan node applied to some sub-path
AggPath - an Agg plan node applied to some sub-path
GroupingSetsPath - an Agg plan node used to implement GROUPING SETS
MinMaxAggPath - a Result plan node with subplans performing MIN/MAX
WindowAggPath - a WindowAgg plan node applied to some sub-path
SetOpPath - a SetOp plan node applied to some sub-path
RecursiveUnionPath - a RecursiveUnion plan node applied to two sub-paths
LockRowsPath - a LockRows plan node applied to some sub-path
ModifyTablePath - a ModifyTable plan node applied to some sub-path(s)
LimitPath - a Limit plan node applied to some sub-path
NestPath - nested-loop joins
MergePath - merge joins
HashPath - hash joins
EquivalenceClass - 表示一组已知相等的值的数据结构
PathKey - 表示路径排序顺序的数据结构
优化程序花费大量时间考虑一个路径返回的元组的顺序。 这很有用是因为,通过了解路径的排序顺序,我们可以将该路径用作merge join的左输入或右输入,并避免显式排序步骤。Nestloops 和hash join并不真正关心它们的输入顺序是什么,但 mergejoin 需要输入适当的排序。因此,在优化过程中生成的所有路径都标有其排序顺序(在已知范围内),以供更高级别的merge使用。
如果最终路径已经具有正确的排序,则还可以避免显式排序步骤来实现用户的 ORDER BY 子句,因此即使在顶层,排序也很有趣。grouping_planner() 将查找符合预期排序的最佳路径,然后将其成本与在使用最低成本的整体路径上显示排序的成本进行比较。
当我们为特定的RelOptinfo生成路径时,如果路径比具有相同或更好排序顺序的另一个已知路径更昂贵,我们将丢弃该路径。 我们永远不会丢弃一条唯一已知能实现排序目标的路径,(也就是说,没有显式排序)。 通过这种方式,下一级将有最大的自由度来构建mergejoins而无需排序,因为它可以从为其输入而保留的任何路径中进行选择。
EquivalenceClasses
在查询的qual 子句的deconstruct_jointree()扫描期间,我们寻找mergejoinable的等式子句 A = B,其适用性不会因外连接而延迟(delay);这些被称为“equivalence clauses”。 当我们找到一个时,我们创建一个包含表达式 A 和 B 的 EquivalenceClass 来记录这些信息。 如果我们后来发现另一个等价子句 B = C,我们将 C 添加到 {A B} 的现有EquivalenceClasses中;这可能需要合并两个现有的EquivalenceClasses。在扫描结束时,我们有一组已知的值,这些值彼此传递性等价(transitively equal)。 因此,我们可以使用任何一对值的对比作为restriction或join clause(当然,当这些值在扫描或连接时可用);此外,我们只需要测试一个这样的对比,而不是全部。 因此,equivalence clauses从标准qual分配流程中删除。 相反,在准备restriction或join clause list时,我们会检查每个 EquivalenceClass 以查看它是否可以贡献一个子句,如果是,我们选择适当的值对进行比较。 例如,如果我们尝试连接 A 与 C 的关系,我们可以生成子句 A = C,即使这在原始查询中没有明确出现。 这可能允许我们探索连接路径,不然这些路径会因为需要笛卡尔积连接而被拒绝。
有时,EquivalenceClass 可能包含伪常量表达式(即,不包含当前查询级别的 Vars 或 Aggs 表达式,也不包含volatile函数的表达式)。 在这种情况下,我们不遵循动态生成连接子句的策略:相反,我们动态生成限制子句 “var = const”,只要可以首先计算class的其中一个变量成员。 例如,如果我们有 A = B 和 B = 42,我们有效地生成restriction子句 A = 42 和 B = 42,然后我们不需要费心在连接relations时显式测试连接子句 A = B。 实际上,所有class成员都可以在relation-scan级别进行测试,并且永远不需要join测试。
EquivalenceClass的准确技术性诠释是,它断言在可以计算多个成员值的任何计划节点上,可以丢弃值不完全相等的输出行,而不会影响查询结果。 (我们要求计划的所有级别都强制实施EquivalenceClasses,因此join不需要重新检查其子级之一的可计算值的相等性。 对于“在任何地方都有效”的普通 EquivalenceClass,我们可以进一步推断这些值都是非空的,因为所有mergejoinable的运算符都是严格的。 但是,我们也允许出现在外部连接的可为空的侧下方的equivalence clauses形成EquivalenceClasses;对于这些class,解释为所有值都相等,或者所有值(伪常量除外)都变为 null。 (这需要限制非常量成员为严格的,否则当其他成员这样做时,它们可能不会变为 null)。 例如考虑如下
SELECT *
FROM a LEFT JOIN
(SELECT * FROM b JOIN c ON b.y = c.z WHERE b.y = 10) ss
ON a.x = ss.y
WHERE a.x = 42;
我们可以形成below-outer-join EquivalenceClass {b.y c.z 10},从而在扫描 c 时应用 c.z = 10。 (我们不允许outerjoin-delayed clauses形成 EquivalenceClass 的原因正是我们希望能够尽可能低地推动任何派生子句。 但是一旦超过outer join,就不再必然是b.y = 10的情况,因此我们不能使用这样的EquivalenceClasses来得出排序是不必要的结论,(参见下面的PathKeys讨论)。
在此示例中,还请注意 a.x = ss.y(实际上是 a.x = b.y)不是等价子句,因为它对 b 的适用性因外部连接而延迟;因此,我们不会尝试将 b.y 插入等价类 {a.x 42}。但是由于我们看到 a.x 等同于外连接上方的 42,因此我们能够形成一个below-outer-join class {b.y 42};因为没有 b.y = 42 的 b/c 行会影响外连接的结果,所以可以添加此限制,因此我们不需要计算此类行。 现在,这个类将与 {b.y c.z 10} 合并,导致矛盾 10 = 42,这让规划器推断出根本不需要计算 b/c 连接,因为它的任何行都不能对outer join做出贡献。 (这被实现为gating Result filter,因为更常见的潜在矛盾涉及 Param 值而不仅仅是 Consts,因此必须在运行时进行检查。)
为了帮助确定mergejoin有效的排序顺序,我们用其左右输入的 EquivalenceClass 标记每个mergejoinable子句。对于等价子句,这些当然是相同的EquivalenceClass。对于非等价mergejoinable子句(例如outer-join qualification),我们为左右输入生成两个单独的 EquivalenceClass。 这可能会导致创建单项等价“类”,当然,如果后来发现其他等价子句与相同的表达式有关,这些类仍会合并。 (outer join有qual,则是非等价的,也有可能合并)
我们形成单项EquivalenceClass 的另一种方法是创建一个 PathKey 来表示所需的排序顺序(见下文)。 这与上述情况略有不同,因为这样的 EquivalenceClass 可能包含聚合函数或volatile表达式。 (包含volatile函数的子句永远不会被视为mergejoinable,即使其顶级运算符是mergejoinable,否则volatile表达式无法进入EquivalenceClasses。 聚合在 WHERE 中是完全不允许的,因此永远不会在mergejoinable子句中找到。)这只是为了方便维护统一的 PathKey 表示形式:这样的 EquivalenceClass 永远不会与任何其他类merge。 特别要注意的是,单项EquivalenceClass {a.x} 不意味着 a.x = a.x 的断言;这样做的实际效果是 A.x 可以是 NULL。
EquivalenceClass还包含 btree opfamily oid 的列表,它决定了它所代表的等式实际上“意味着”什么。 所有有助于EquivalenceClass的等价子句都必须具有属于同一组opfamilies的相等运算符。 (注意:大多数情况下,特定的相等运算符只属于一个family,但它可能属于多个family。 我们跟踪所有families,以确保我们可以将属于任何一个families的索引用于mergejoin的目标。)
EquivalenceClass可以包含“em_is_child”成员,这些成员是包含appendrel parent relation Vars 的成员的副本,转置为包含等效的child-relation variables or expressions。 这些成员不是EquivalenceClass的成熟成员,根本不影响类的整体属性。 保留它们只是为了简化child-relation expressions与EquivalenceClass的匹配。对EquivalenceClasses的大多数操作都应忽略子成员。
PathKeys
PathKeys 数据结构表示已知有关特定 Path 生成的元组的排序顺序信息。 路径的pathkeys field是PathKey节点的列表,其中第 n 项表示结果的第 n 个排序键(path key)。 每个PathKey都包含以下fields:
- 对EquivalenceClass的引用
- 一个 btree opfamily oid(必须与 EC 中的一个匹配)
- 排序方向(升序或降序)
- 一个nulls-first-or-last标志
EquivalenceClass表示要排序的值。由于 EquivalenceClass 的各个成员根据opfamily 知道其相等,我们可以认为由其中任何一个排序的路径也由任何其他成员排序;这就是引用整个EquivalenceClass而不仅仅是其中的一个成员的理由。
在single/base relation RelOptinfo 中,路径表示扫描relation 的各种方式以及生成元组排序。顺序扫描路径具有 NIL pathkeys,表示没有已知的排序。索引扫描具有表示所选索引的顺序(如果有)的 Path.pathkeys。 单键索引将创建单 PathKey 列表,而多列索引将生成一个每个元素一个索引键列的列表。覆盖索引的 INCLUDE 子句中指定的非键列在列表中没有相应的 PathKey,因为它们对索引排序没有影响。 (实际上,由于索引可以向前或向后扫描,因此它可以生成两种可能的排序顺序和两个可能的 PathKey 列表。)
注意,位图扫描(bitmap scan )具有 NIL pathkeys,因为我们对其结果的总体顺序无话可说。 此外,对无序索引类型的索引进行索引扫描会生成 NIL pathkeys。 但是,我们始终可以通过执行显式排序来创建pathkeys。 排序计划输出的pathkeys仅表示排序键字段和使用的排序运算符。
当我们考虑join时,事情会变得更加有趣。 假设我们使用合并子句 A.X = B.Y. 在 A 和 B 之间进行mergejoin。 mergejoin的输出按 X排序——但也按 Y 排序。 同样,这可以通过引用包含 X 和 Y 的 EquivalenceClass 的 PathKey 来表示。
经过进一步思考,很明显,nestloop连接也可以产生排序输出。 例如,如果我们在outer relation A 和inner relation B 之间执行nestloop join,那么与 A 相关的任何pathkey对于连接结果仍然有效:我们没有更改 A 的元组顺序。 更有趣的是,如果有一个等价子句 A.X=B.Y,并且 A.X 是outer relation A 的pathkey,那么我们可以断言 B.Y 是连接结果的pathkey;X 之前是有序的,现在仍然是,Y 的连接值等于 X 的连接值,因此 Y 现在也必须排序。 即使我们在 Y 上既没有使用显式排序也没有使用merge join,也是如此。 (注意:不能指望hash join来保留其outer relation的顺序,因为执行者可能会决定“批处理”join,因此我们始终将hash join路径的pathkey设置为 NIL。) 例外:RIGHT 或 FULL JOIN不会保留其outer relation的顺序,因为它可能会在排序中的随机位置插入 null。
通常,我们可以证明使用 EquivalenceClasses 作为pathkey的基础是合理的,因为每当我们扫描包含多个 EquivalenceClass 成员的relation或join两个分别包含 EquivalenceClass 成员的relation时,我们都会应用从 EquivalenceClass 派生的restriction或join子句。 这保证了 EquivalenceClass 中列出的任何两个值在扫描或join发出的所有元组上实际相等,因此,如果元组按其中一个值排序,则也可以认为它们由任何其他值排序。 测试子句是用作mergeclause,还是仅作为 qpqual filter在事后强制执行,都并不重要。
请注意,使用 PathKey 标记相关EquivalenceClass路径的排序顺序并不特别困难,该EquivalenceClass包含尚未连接到路径输出中的变量。 我们可以简单地忽略这些条目,因为(还)不相关。 这样就可以在整个联接规划过程中使用相同的EquivalenceClasses。事实上,注意不要生成多个相同的 PathKey 对象,我们可以将 EquivalenceClasses 和 PathKeys 的比较简化为简单的指针比较,这是一个巨大的节省,因为add_path在决定竞争path是否等效排序时必须进行大量的 PathKey比较。
pathkey对于表示我们希望实现的排序也很有用,因为它们很容易与潜在候选路径的path进行比较。 因此,SortGroupClause 列表被转换为pathkey lists,以便在optimizer内部使用。
我们可以进行的另一个改进是坚持规范化pathkey lists(排序顺序)不会多次提及相同的EquivalenceClass。 例如,在所有这些情况下,第二个排序列都是多余的,因为它无法根据第一个排序列区分相同的值:
SELECT ... ORDER BY x, x
SELECT ... ORDER BY x, x DESC
SELECT ... WHERE x = y ORDER BY x, y
虽然用户可能不会直接编写ORDER BY x,x,但一旦考虑了EquivalenceClasses,这种冗余的可能性更大。 此外,在计算mergejoin所需的排序顺序时,系统可能会生成冗余pathkey list。通过消除冗余,我们节省了时间并改进了规划,因为planner将更容易将等效的顺序识别为等效的。(容易理解)
另一个有趣的属性是,如果底层 EquivalenceClass 包含一个常量并且不在外部连接下方,那么pathkey是完全冗余的,根本不需要排序! 每一行必须包含相同的常量值,因此无需排序。 (如果 EC(应该是指equal const)位于外连接下方,我们仍然需要排序,因为某些行可能已变为 null,而其他行则没有。 在这种情况下,我们必须小心选择一个非常量成员进行排序。 所有非常量成员在同一计划级别变为 null 的假设在这里至关重要,否则它们可能不会产生相同的排序顺序。 这似乎毫无意义,因为用户不太可能写... WHERE x = 42 ORDER BY x,但它允许我们识别特定索引列何时与排序顺序无关:如果我们有... WHERE x = 42 ORDER BY y,扫描 (x,y) 上的索引会生成正确排序的数据,而无需排序步骤。 我们曾经有非常丑陋的临时代码来识别有限的上下文,但是从pathkey中丢弃常量 EC 可以使其干净、自动地发生。
你可能会反对below-outer-join EquivalenceClass 并不总是在join tree的每个级别表示相同的值,因此使用它来唯一标识排序顺序是可疑的。 这是真的,但我们可以避免显式处理这一事实,因为我们总是认为外连接会破坏其nullable输入的任何排序。 因此,如果排序顺序很重要,即使路径在外连接下按 {a.x} 排序,我们也会重新排序;因此,对两种排序使用相同的 PathKey不会产生任何真正的问题。(outer relation的null值处理看上去比想象的麻烦)
Order of processing for EquivalenceClasses and PathKeys
如上所述,在规划过程中,在处理EquivalenceClasses和PathKeys阶段时有一个特定序列。 在对查询的 quals(deconstruct_jointree followed by reconsider_outer_join_clauses)进行初始化扫描期间,我们基于在 quals 中找到的mergejoinable子句构造 EquivalenceClasses。 在这个过程结束时,我们知道了所有我们可以知道的不同变量的等价性,所以随后不会再合并EquivalenceClasses。此时,可以将EquivalenceClasses视为“canonical规范”,并构建引用它们的canonical PathKeys。 此时,我们为查询的 ORDER BY 和相关子句构造 PathKeys。(任何未出现在其他地方的排序表达式都将导致创建新的EquivalenceClasses,但这不会导致合并现有类,因此规范性不会丢失。)
因为所有的EquivalenceClass 在我们开始生成路径之前都是已知的,所以我们可以使用它们作为哪些索引感兴趣的指南:如果索引的列在任何 EquivalenceClass 中都没有提及,那么该索引的排序顺序对查询没有帮助。 这允许简化(short-circuiting)处理大部分不相关索引的create_index_paths()。
在某些情况下,planner.c 会在query_planner完成后构造额外的 EquivalenceClasses 和 PathKey。在这些情况下,需要额外的 EC/PK 来表示query_planner期间未考虑的排序顺序。 这种情况应最小化,因为query_planner不可能返回生成此类排序顺序的计划,这意味着始终需要显式排序。目前,这仅适用于涉及查询具有不同顺序的多个窗口函数,这无论如何都需要额外的排序。
Parameterized Paths
使用像 WHERE A.X = B.Y 这样的子句连接两个关系的天真方法,是生成一个像这样的 nestloop 计划:
NestLoop
Filter: A.X = B.Y
-> Seq Scan on A
-> Seq Scan on B
我们可以通过使用merge或hash join来使其更棒,但它仍然需要扫描所有两个input relations。 如果 A 非常小,B 非常大,但 B 上有一个索引,那么做这样的事情可能会好得多:
NestLoop
-> Seq Scan on A
-> Index Scan using B_Y_IDX on B
Index Condition: B.Y = A.X
在这里,我们期望对于从 A 扫描的每一行,nestloop 计划节点会将 A.X 的当前值传递到 B 的扫描中。这允许 indexscan 将 A.X 视为任何一个调用的常量,从而将其用作索引键。 这是唯一可以避免获取所有 B 的计划类型,对于来自 A 的少量行,这将主导所有其他考虑因素。 (随着 A 变大,这变得不那么有吸引力,最终合并或哈希连接将获胜。因此,我们必须cost out所有替代方案来决定该怎么做。)
通过连接中间层向下传递参数值可能很有用,例如:
NestLoop
-> Seq Scan on A
Hash Join
Join Condition: B.Y = C.W
-> Seq Scan on B
-> Index Scan using C_Z_IDX on C
Index Condition: C.Z = A.X
如果所有joins都是普通的inner joins,则通常不需要这样做,因为可以对joins重新排序,以便紧邻提供它的 nestloop 节点下方使用参数。 但存在outer joins的情况下,可能无法进行此类join重新排序。
此外,bottom-level扫描可能需要来自多个其他relation的参数。 原则上,我们可以先连接其他relation,以便所有参数都从单个 nestloop 级别而来。但是,如果这些其他relation没有共同的join clause(例如,这在star-schema查询中很常见),则planner不会考虑将它们直接联接在一起。 在这种情况下,我们需要能够创建一个计划,例如
NestLoop
-> Seq Scan on SmallTable1 A
NestLoop
-> Seq Scan on SmallTable2 B
-> Index Scan using XYIndex on LargeTable C
Index Condition: C.X = A.AID and C.Y = B.BID
因此,我们应该希望通过联接传递 A.AID,即使没有联接顺序约束迫使计划看起来像这样。
在版本 9.2 之前,Postgres 使用临时方法来规划和执行此类 nestloop 查询,这些方法无法处理通过多个连接级别向下传递参数。
为了规划此类查询,我们现在使用“参数化路径”(parameterized path)的概念,该路径使用join clause来处理未被路径扫描的relation。 在上面的示例二中,我们将构造一个表示这样做的可能路径:
-> Index Scan using C_Z_IDX on C
Index Condition: C.Z = A.X
此路径将被标记为由relation A参数化 。 (请注意,这只是 C 的可能访问路径之一;我们仍然有一个普通的无参数化 seqscan,也许还有其他可能性。) 参数化标记不会阻止将路径连接到 B,因此为 joinrel {B C} 生成的路径之一将表示为:
Hash Join
Join Condition: B.Y = C.W
-> Seq Scan on B
-> Index Scan using C_Z_IDX on C
Index Condition: C.Z = A.X
此路径仍标记为由 A 参数化。 当我们尝试将 {B C} 连接到 A 以形成完整的join tree时,这样的路径只能用作 nestloop 连接的内侧:对于其他可能的连接类型,它将被忽略。 因此,我们将形成一个表示上面所示的查询计划的联接路径,它将以通常的方式与非参数化扫描构建的路径竞争。
虽然特定relation的所有普通路径都生成相同的行集(因为它们必须都应用同一组限制子句),但参数化路径通常比参数化程度较低的路径生成的行少,因为它们具有额外的子句可以使用。 这意味着我们必须将生成的行数视为额外的品质因数(figure of
merit)。 必须保留成本高于另一个路径但生成的行较少的路径,因为较少的行数可能会在某个中间连接级别节省工作 (如果立即连接到参数源,它不会保存任何内容)。
为了使成本估算规则相对简单,我们设置了一个实现限制,即给定相同参数化relation(即,同一组外部relation应用参数)的所有路径必须具有相同的估算行。 这是通过坚持每个此类路径应用可用于命名外部关系的所有join子句来证明这一点的。例如,不同的路径可能会选择不同的join子句用作索引子句;但是,它们随后必须应用与过滤条件相同的外部relation中可用的任何其他连接子句,保证返回的行集保持不变。此限制不会降低完成计划的质量:它相当于说我们应该始终将可移动连接子句推到尽可能低的评估级别,这无论如何都是一件好事。 此限制对于支持add_path_precheck中的联接路径的预筛选尤其有用。 如果没有此规则,我们永远无法在估算其行数之前拒绝参数化路径,这将大大降低预过滤机制的价值。
为了限制planning时间,我们必须避免生成大量不合理的参数化路径。 为此,我们只为索引扫描生成参数化的relation扫描路径,然后只为有合适的join子句可用的索引生成参数化的relation扫描路径。 join planning中也有启发式方法,试图限制所考虑的参数化路径的数量。
特别是,有一个深思熟虑的决策,即在参数化连接步骤(那些发生在为较低连接输入提供参数的 nestloop 下方)的merge joins之上。 虽然我们不会完全忽略merge joins,但 joinpath.c 并没有完全探索具有参数化输入的潜在merge joins的空间。 此外,add_path 将参数化路径视为没有pathkey,因此它们仅在成本和行数上对比;他们不会优先生成特殊的排序顺序。 这会额外产生对merge joins的偏见,因为我们可能会丢弃一个路径,该路径对于执行merge很有用,而无需显式排序步骤。 由于参数化路径最终必须在 nestloop 的内部使用,对其排序顺序不感兴趣,因此这些选择不会影响对查询最终输出顺序的任何需求——它们只会使在较低级别使用merge join变得更加困难。 planning工作的节省处证明了这一点。
同样,参数化路径通常不会通过add_path获得优先选择,因为启动成本低廉;在 Nestloop 的内部,这几乎没有多大价值,因此似乎不值得为此保留额外的路径。 SEMI 或 ANTI 连接的 RHS relation 的参数化路径会出现异常:在这些情况下,我们可以在第一次匹配后停止内部扫描,因此我们关心的主要是启动成本而不是总成本。
LATERAL subqueries
从 9.3 开始,我们支持 FROM 中引用子查询的 SQL 标准 LATERAL (以及 FROM 中的函数)。 planner通过为包含横向参照的任何 RTE 生成参数化路径来实现这些目标。 在这种情况下,该关系的所有路径将由至少在lateral中使用的relation集进行参数化(反过来,包含此类子查询的join relations可能没有任何未参数化的路径)。不过,上面对参数化路径所做的所有其他注释仍然适用;特别是,每个这样的路径仍应强制实施可向下推送到它的任何连接子句,以便同一参数化的所有路径具有相同的行数。
我们还允许optimizer展平LATERAL子查询(拉入父查询),但前提是这不会将LATERAL引用引入 JOIN/ON quals,这些引用将引用处于或高于outer join的外部连接的relations quals。 这种qual的语义会不清晰。 请注意,即使有此限制,LATERAL 子查询的上拉也可能导致创建包含对其语法范围之外的relation的横向(lateral)引用的 PlaceHolderVar。 我们仍然在语法位置或更低位置评估此类 PHV,但是在计划节点的质量或目标列表中存在此类 PHV 要求该节点相对于提供横向(lateral)引用的 rel 出现在 nestloop 连接的内部。 (也许现在这些东西有效了,我们可以放宽上拉限制?)
Security-level constraints on qual clauses
为了有效地支持行级安全(row-level security )和安全屏障视图(security-barrier views),我们使用“security_level”字段标记限定子句(RestrictInfo 节点)。基本概念是,security_level较低的qual必须在security_level较高的qual之前进行评估。 这可确保在应筛选出安全敏感行的安全屏障quals之后,不会评估可能公开敏感数据的“泄漏”quals。 但是,许多限定条件是“防漏”的,也就是说,我们相信它们用于不暴露数据的功能。 为了避免不必要的低效计划,防漏qual不会因考虑安全级别(security_level)而延迟,即使它具有比另一个qual更高的语法安全等级。
在不包含使用 RLS 或安全屏障视图的查询中,所有quals都将零级security_level,因此这些限制都不会启动;我们甚至不需要检查qual条件的防漏性。
如果存在安全屏障qual,则它们security_level为零(如果有多层屏障,则可能更高)。来自查询文本的常规qual比用于最高等级的障碍qual的更一级。
当 EquivalenceClass 生成新的qual子句时,必须为它们分配一个security_level。 这比看起来更棘手。人们的第一直觉是,使用在EquivalenceClass的source quals中找到的最大级别是安全的,但这根本不安全,因为它允许安全屏障qual的不必要的延迟。考虑一个障碍qual “t.x = t.y”加上一个查询qual “t.x = 常量”,并假设在检查障碍qual之前,我们不能评估另一个查询qual “leaky_function(t.z)”。
这有一个EC {t.x, t.y, constant},这将导致我们将 EC quals 替换为 “t.x = 常量 AND t.y = 常量”。 (我们也不想放弃这种行为,因为后一个条件可能允许在 t.y 上使用索引,我们永远不会从source quals中发现这一点。 如果为这些生成的qual条件分配了与查询qual条件相同的security_level,则可以首先评估leaky_function qual,从而允许leaky_function查看可能未通过屏障条件的行数据。
相反,我们使用 EC 处理安全级别的工作方式如下:
- 首先不接受qual作为 EC 的源子句,除非它们是防漏的或零级security_level。
- EC派生的qual被分配了在EC的源子句中找到的最小(而不是最大)security_level。
- 如果在 EC 的源子句中找到的最大security_level大于零,则为派生qual条件选择的等值运算符必须是防漏的。 当找不到这样的运算符时,EC 被视为“损坏”,我们回退到发出这个qual的源子句,该子句没有任何额外的派生qual。
这些规则共同确保不受信任的qual子句(security_level大于零的子句)不会导致 EC 生成泄漏的派生子句。 这样就可以安全地对派生子句使用最小而不是最大security_level。 由于根本无法生成派生子句,这些规则可能会导致计划不佳,但在实践中,这种风险很小,因为大多数 btree 等值运算符都是防漏的。此外,通过对零级qual的例外,我们确保在没有障碍qual的情况下不会出现计划降级。
一旦我们为所有子句分配了安全级别,障碍qual的排序限制将归结为两条规则:
- 表扫描计划节点不得选择提前执行的qual(例如,将它们用作索引扫描中的索引qualifiers),除非它们是防漏的或security_level不高于将在同一计划节点上执行的任何其他qual。 (使用utility function函数 restriction_is_securely_promotable()检查是否选择提前执行qual)
- qual列表必须以满足相同的安全规则的正常顺序执行,即更高的security_levels必须稍后评估,除非是防漏的。 (这由 createplan.c 中的 order_qual_clauses() 在某个地方进行处理)
order_qual_clauses()使用启发式方法来准确决定如何处理防漏子句。 通常,它会按security_level、成本(cost)对子句进行排序,注意排序是否稳定,这样我们就不会在没有明确原因的情况下对子句进行重新排序。 但这可能会导致在security_level更高的更便宜的qual之前完成非常昂贵的qual。如果更便宜的qual泄漏,我们别无选择,但如果它是防漏的,我们可以把它放在第一位。 我们选择对防漏qual进行分类,就好像它们security_level为零一样,但前提是它们的成本低于 10 倍cpu_operator_cost;这种限制减轻了相反的问题,即仅仅因为它们是防漏的,就首先执行昂贵的qual。
当join qual之间存在混合的安全级别时,将需要其他规则来支持join qual的安全处理;例如,有必要防止在低于安全级别的其他join qual级别评估泄漏的较高安全级别qual。目前无需考虑这一点,因为安全优先级qual只能是来自 RLS 策略或安全屏障视图的单表限制qual,并且安全屏障视图子查询永远不会平展到父查询中。 因此,安全优先级限定条件的强制实施仅在表扫描级别进行。通过安全处理 qual join之间的安全级别的额外规则,应该可以让安全屏障视图平展到父查询中,从而允许更大的plan灵活性,同时仍保留所需的qual评估顺序。 但那将在以后出现。
Post scan/join planning
到目前为止,我们只讨论了扫描/联接规划,即 SQL 查询的 FROM 和 WHERE 子句的实现。 但是,planner还必须确定如何处理 GROUP BY、聚合和其他查询的高级功能;在许多情况下,有多种方法可以执行这些步骤,从而有机会进行优化选择。 这些步骤(如扫描/联接规划)是通过构建表示执行步骤的不同方式的路径,然后选择最便宜的路径来处理的。
由于所有路径都需要 RelOptInfo 作为“parent”,因此我们创建了表示这些上层处理步骤输出的 RelOptInfo。 这些 RelOptInfos 大多是虚拟的,但它们的路径列表包含每个步骤认为是有用的所有路径。 目前,我们可能会在上层规划期间创建以下类型的附加相关选择信息:
| UPPERREL_SETOP | result of | UNION/INTERSECT/EXCEPT, if any |
| UPPERREL_PARTIAL_GROUP_AGG | result of | partial grouping/aggregation, if any |
| UPPERREL_GROUP_AGG | result of | grouping/aggregation, if any |
| UPPERREL_WINDOW | result of | window functions, if any |
| UPPERREL_PARTIAL_DISTINCT | result of | partial “SELECT DISTINCT”, if any |
| UPPERREL_DISTINCT | result of | “SELECT DISTINCT”, if any |
| UPPERREL_ORDERED | result of | ORDER BY, if any |
| UPPERREL_FINAL | result of | any remaining top-level actions |
UPPERREL_FINAL用于表示任何最终的处理步骤,当前为LockRows (SELECT FOR UPDATE), LIMIT/OFFSET, and ModifyTable。 这些步骤的完成顺序没有灵活性,因此无需更精细地细分此阶段。
这些“UPPERREL”由上面显示的 UPPERREL 枚举值以及一个 relids 集标识,该集合允许存在多个相同类型的上层。 如果不需要多个相同类型的upperrel,我们使用 NULL 作为upperrel。 事实上,目前,relids集是退化的,因为它总是 NULL,但预计将来会发生变化。 例如,在planning集合操作时,我们可能需要 relids 来表示叶 SELECT 的哪个子集已组合到相互竞争的特定路径组中。
subquery_planner()的结果始终返回作为存储在具有 NULL 的 UPPERREL_FINAL rel 中的一组路径。 其他类型的upperrels仅在特定查询需要时才创建。
Parallel Query and Partial Paths
并行查询涉及划分整个查询或部分查询的工作,以便其中一些工作可以由一个或多个worker进程(称为parallel workers)完成。 parallel workers是动态背景worker的一个子类型;请参阅 src/backend/access/transam/README.parallel 获取更完整的描述。 关于并行查询的学术文献表明,并行执行策略基本上可以分为两类:流水线并行,其中查询的执行分为多个阶段,每个阶段由单独的进程处理;分区并行性,其中数据在多个进程之间拆分,每个进程处理其中的一个子集。 然而,文献表明,由于难以避免流水线停滞,流水线并行性的收益通常非常有限。因此,我们目前不尝试生成使用此技术的查询计划。(pg使用分区并行)
相反,我们专注于分区并行,这不需要对基础表进行分区。 它只需要 (1) 有某种方法可以从多个进程的涉及关系中的至少一个基表中划分数据(2) 允许每个进程处理自己的数据部分,然后 (3) 收集结果。 要求 (2) 和 (3) 满足执行器节点 Gather(或 GatherMerge),该节点启动任意数量的worker,并在所有worker执行其中的单个子计划,如果子进程没有生成足够的数据来保持leader忙碌工作,则可能在leader中也是如此。 需求 (1) 由表扫描节点处理:当使用 parallel_aware = true 调用时,该节点实际上将逐块对表进行分区,从执行该扫描节点的每个worker的关系中返回元组的子集。(并行的两种方法:(1)对基表进行块级划分实施并行;(2)在执行计划节点中实施并行,最后把结果gather到一起)
就像我们对非并行访问方式所做的那样,我们构建路径来表示可在并行计划中使用的访问策略。 从本质上讲,这些策略与非并行计划中可用的策略相同,但有一个重要的区别:将在 Gather 节点下运行的路径仅返回每个工作线程中查询结果的子集,而不是所有查询结果。 要形成可以实际执行的路径,必须考虑 Gather 节点的(相当大的)成本。 出于这个原因,打算在 Gather 节点下运行的路径 - 我们称之为“部分”路径,因为它们只返回每个工作线程中结果的子集 - 必须与普通路径分开(请参阅 RelOptinfo 的partial_pathlist和函数add_partial_path)。
使并行查询有效的关键之一是尽可能多地并行运行查询。 因此,我们预计通常最好将聚集阶段推迟到尽可能接近计划的顶部。 扩大更多可以将更多工作推到Gather以下的情况(并准确地计算它们的成本)可能会让我们在未来保持忙碌很长一段时间。(确实如此,并行是这最近几个pg版本的重点优化功能)
Partitionwise joins
如果连接表的分区键之间存在等值连接条件,则可以将两个相似的分区表之间的连接分解为匹配分区之间的连接。分区键之间的等值连接意味着一个分区表中给定行的所有连接伙伴都必须位于另一个分区表的相应分区中。因此,分区表之间的连接将被分解为匹配分区之间的连接。生成的连接以与连接relation相同的方式进行分区,从而允许将分区键之间具有等值连接条件的类似分区表之间的 N个 连接分解为其匹配分区之间的 N个连接。这种将分区表之间的联接分解为分区之间的联接的技术称为partitionwise join。我们将使用术语“partitioned relation”来表示分区表或兼容分区表之间的连接。
即使join relation没有完全相同的分区边界,仍可以使用partitionwise join分区匹配算法应用分区连接。 对于这两种连接关系,该算法会检查一个join relation的每个分区是否最多只匹配另一个连接关系的一个分区。 在这种情况下,join relation之间的连接可以分解为匹配分区之间的连接。 然后,可以将join relation视为已分区。该算法生成匹配分区对以及join relation的分区边界,以允许partitionwise join用来计算连接。 该算法在 partition_bounds_merge() 中实现。对于以这种方式分区的 N 个join relation,并非每对join relation都可以使用partitionwise join。 例如:
(A leftjoin B on (Pab)) innerjoin C on (Pac)
其中 A、B 和 C 是分区表,与 B 和 C 相比,A 有一个额外的分区。 当考虑连接 {A B} 的分区时,A 的额外分区在可为空的端没有匹配的分区,这是当前partitionwise join无法处理的情况。 因此,{A B} 不被视为分区,并且 {A B} 和 C的3路连接不能使用partitionwise join。 另一方面,{A C} 和 B 对可以使用 partitionwise join,因为 {A C} 通过消除额外的分区而被视为分区(请参阅外联接重新排序中的identity 1)。 N 路连接是否可以使用partitionwise join取决于第一对join relation已分区且可以使用partitionwise join。
分区表的分区属性存储在其 RelOptinfo 中。 有关分区键数据类型的信息存储在PartitionSchemeData中。planner维护规范化的分区方案(区别于PartitionSchemeData对象)的列表,以便具有相同分区方案的任意两个分区关系的 RelOptInfo 指向相同的PartitionSchemeData对象。 这减少了 PartitionSchemeData 对象消耗的内存,并便于比较join relation的分区方案。
Partitionwise aggregates/grouping
如果 GROUP BY 子句包含所有分区键,则属于给定组的所有行都必须来自单个分区;因此完全可以为每个分区单独进行聚合。否则,可以为每个分区计算部分聚合(partial aggregates),然后在append各个分区的结果后finalized。 这种将分区关系上的聚合或分组分解为聚合或对其分区进行分组的技术称为partitionwise
aggregation。 特别是当分区键与 GROUP BY 子句匹配时,这可能比常规方法快得多。