postgresql-管理数据表
- 创建表
- 数据类型
- 字段约束
- 表级约束
- 模式搜索路径
- 修改表
- 添加字段
- 删除字段
- 添加约束
- 删除约束
- 修改字段默认值
- 修改字段数据类型
- 重命名字段
- 重命名表
- 删除表
创建表
在 PostgreSQL 中,使用 CREATE TABLE 语句创建一个新表:
CREATE TABLE table_name
(
column_name data_type column_constraint,
column_name data_type,
...,
table_constraint
);
- 首先,table_name 指定了新表的名称
- 括号内是字段的定义, column_name 是字段的名称, data_type 是它的类型,
column_constraint 是可选的字段约束;多个字段使用逗号进行分隔 - table_constraint 是可选的表级约束
数据类型
PostgreSQL 提供了丰富的内置数据类型,同时还允许用户自定义数据类型。最常见的基本
数据类型包括:
- 字符类型,包括定长字符串 CHAR(n),变长字符串 VARCHAR(n),以及支持更大长度的
字符串 TEXT。 - 数字类型,包括整数类型 SMALLINT、INTEGER、BIGINT,精确数字 NUMERIC (p, s),
浮点数 REAL、DOUBLE PRECISION - 时间类型,包括日期 DATE、时间 TIME、时间戳 TIMESTAMP
官网关于类型的介绍
字段约束
PostgreSQL 支持 SQL 标准中的所有字段约束和表约束
- NOT NULL,非空约束,该字段的值不能为空(NULL)
- UNIQUE,唯一约束,该字段每一行的值不能重复。不过,PostgreSQL 允许该字段存在
多个 NULL 值,并且将它们看作不同的值。需要注意的是 SQL 标准只允许UNIQUE字
段中存在一个 NULL 值 - PRIMARY KEY,主键约束,包含了 NOT NULL 约束和 UNIQUE 约束。如果主键只包
含一个字段,可以通过列级约束进行定义(参考上面的示例);但是如果主键包含多个
字段(复合主键)或者需要为主键指定一个自定义的名称,需要使用表级约束进行定义 - REFERENCES,外键约束,字段中的值必需已经在另一个表中存在。外键用于定义两
个表之间的参照完整性(referential integrity),例如,员工的部门编号字段必须是一个
已经存在的部门 - CHECK,检查约束,插入或更新数据时检查数据是否满足某个条件。例如,产品的价
格必需大于零 - DEFAULT,默认值,插入数据时,如果没有为这种列指定值,系统将会使用默认值代
替。
表级约束
表级约束和字段约束类似,只不过它是基于整个表定义的约束,还能够为约束指定自定义的
名称。PostgreSQL 支持的表级约束包括:
- UNIQUE(column1, …),唯一约束,括号中的字段值或字段值的组合必须唯一
- PRIMARY KEY(column1, …),主键约束,定义主键或者复合主键
- REFERENCES,定义外键约束
- CHECK,定义检查约束
/*
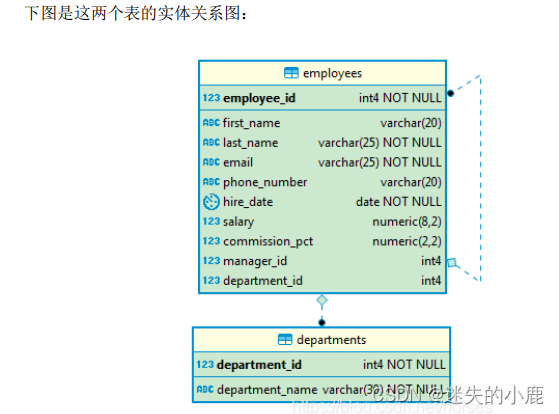
* 员工表包含以下字段和约束:
* employee_id , 员工 编 号, 整 数类 型 ,主 键 (通 过 表级 约 束为 主 键指 定 了名 称
* emp_emp_id_pk);
* first_name,名字,字符串;
* last_name,姓氏,字符串,不能为空;
* email,电子邮箱,字符串,不能为空,必须唯一(emp_email_uk);
* phone_number,电话号码,字符串;
* hire_date,雇佣日期,日期类型,不能为空;
* salary,薪水,数字类型,必须大于零(emp_salary_min);
* commission_pct,佣金百分比,数字类型;
* manager_id,经理编号,外键(通过外键 emp_manager_fk 引用员工表的员工编号);
* department_id,部门编号,外键(通过外键 emp_dept_fk 引用部门表 departments 的编号
* department_id)
* */
create table employees
( employee_id integer not null
, first_name character varying(20)
, last_name character varying(25) not null
, email character varying(25) not null
, phone_number character varying(20)
, hire_date date not null
, salary numeric(8,2)
, commission_pct numeric(2,2)
, manager_id integer
, department_id integer
, constraint emp_emp_id_pk
primary key (employee_id)
, constraint emp_salary_min
check (salary > 0)
, constraint emp_email_uk
unique (email)
, constraint emp_dept_fk
foreign key (department_id)
references departments(department_id)
, constraint emp_manager_fk
foreign key (manager_id)
references employees(employee_id)
) ;
除了自己定义表的结构之外,PostgreSQL 还提供了另一个创建表的方法,就是通过一个查
询的结果创建新表:
CREATE TABLE table_name
AS query;
或者
SELECT ...
INTO new_table
FROM ...;
--例如,我们可以基于 employees 复制出两个新的表:
CREATE TABLE emp1
AS
SELECT *
FROM employees;
SELECT *
INTO emp2
FROM employees;
-- where 语句后面添加1=2,保证只创建表结构,不复制数据
create table d2
as
select * from departments where 1=2;
这种方法除了复制表结构之外,还可以复制数据。官网关于create table as介绍
select into官网介绍
模式搜索路径
在 PostgreSQL 中,表属于某个模式(schema)。当我们创建表时,更完整的语法应该是:
CREATE TABLE schema_name.table_name
访问表的时候也是一样。但是我们在前面创建示例表的时候,并没有加上模式名称的限定。
这里涉及到一个模式的搜索路径概念
-- 我们先看一下当前的搜索路径:
show search_path;
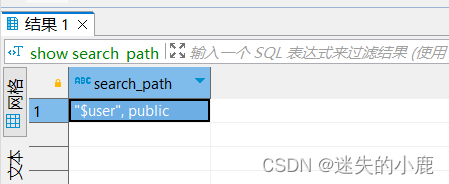
搜索路径是一个逗号分隔的模式名称。当我们使用表的时候,PostgreSQL 会依次在这些模
式中进行查找,返回第一个匹配的表名;当我们创建一个新表时,如果没有指定模式名称,
PostgreSQL 会在第一个模式中进行创建。
第一个模式默认为当前用户名,如果不存在该模式,使用后面的公共模式(public)。
select user;
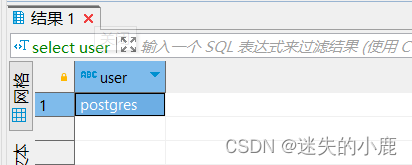
当前用户名为 postgres,但是不存在名为 postgres 的模式,因此我们创建的表会位 public 模式中。
--我们可以通过 set 命令修改默认的搜索路径:
set search_path to app,public;
此时,如果我们再创建新表而不指定模式名称时,默认会在模式 app 中创建
官网模式的介绍
修改表
--创建产品表products
create table products(
product_no integer primary key,
name text,
price numeric
);
添加字段
alter table 表名 add column 列名 数据类型 列约束;
-- 表products添加列description
-- 对于表中已有的数据,新增加的列将会使用默认值进行填充;如果没有指定 DEFAULT 值,
-- 使用空值填充
-- 添加字段时还可以定义约束。不过需要注意的是,如果表中已经存在数据,新增字段的默认
-- 值有可能会违反指定的约束
alter table products add column description text;
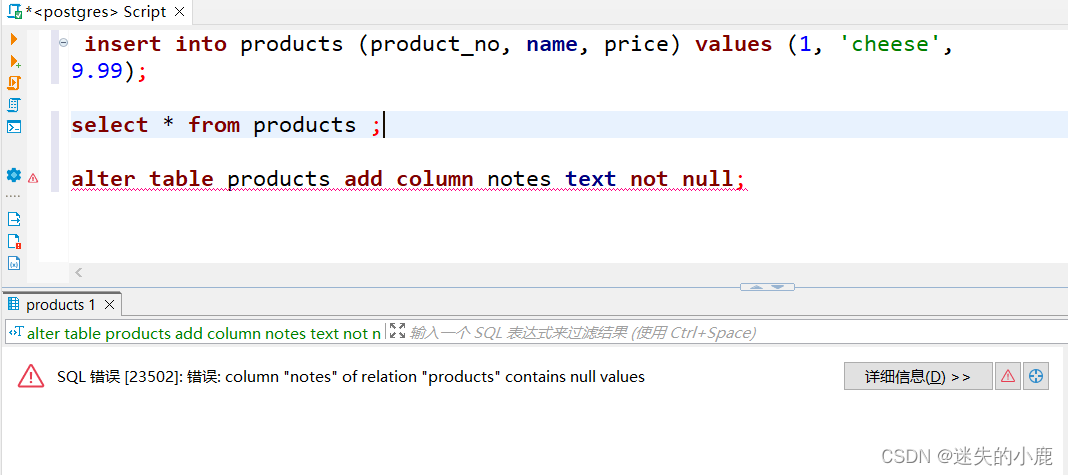
以上语句出错的原因在于新增的字段 notes 存在非空约束,但是对于已有的数据该字段的值
为空
解决方法如下:
- 添加约束的同时指定一个默认值
- 添加字段时不指定约束,将所有数据的字段值手动填充(UPDATE)之后,再添加约束
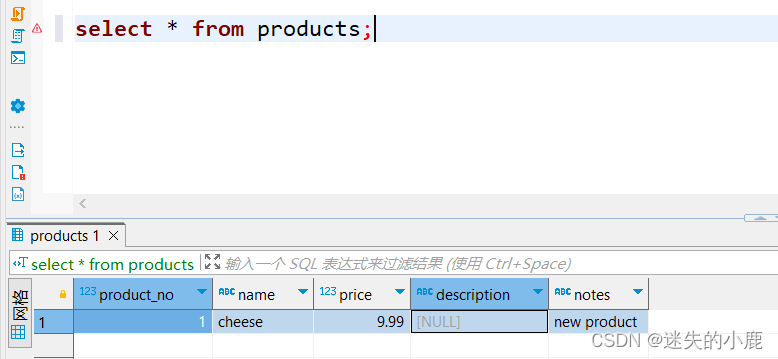
alter table products add column notes text default 'new product' not null;
select * from products;
删除字段
alter table 表名 drop column 列名;
--产品表中的 notes 字段删除:
alter table products drop column notes;
删 除 字 段 后 , 相 应 的 数 据 也 会 自 动 删 除 。 同 时 , 该 字 段 上 的 索 引 或 约 束
也会同时被删除。但是,如果该字段被其他对象(例如外键引用、视图、存储过程等)引用,无法直接删除
在 drop 的最后加上 cascade 选项即可级联删除依赖的对象
添加约束
alter table 表名 add 表级别约束;
alter table products add constraint products_price_min check(price > 0);
-- 非空约束语法
alter table 表名 alter column 列名 set not null;
--将产品表的 name 字段设置为非空
-- 添加约束时,系统会检验已有数据是否满足条件,如果不满足将会添加失败。
alter table products alter name set not null;
删除约束
alter table 表名 drop constraint 约束名称 [ restrict | cascade ];
restrict 是默认值,如果存在其他依赖于该约束的对象,需要使用 cascade 执行级联
删除。例如,外键约束依赖于被引用字段上的唯一约束或主键约束。
--删除非空约束也需要使用单独的语法:
alter table 表名 alter column 列名 drop not null;
--删除产品表 name 字段上的非空约束
alter table products alter name drop not null;
修改字段默认值
--如果想要为某个字段设置或者修改默认值,可以使用以下语句:
alter table 表名 alter column 列名 set default 默认值;
--为产品表的价格设置一个默认值
alter table products alter column price set default 7.77;
--删除已有的默认值
alter table 表名 alter column 列名 drop default;
--删除已有的默认值
-- 删除字段的默认值相当于将它设置为空值(NULL)。
alter table products alter column price drop default;
修改字段数据类型
-- 通常来说,可以将字段的数据类型修改为兼容的类型。
alter table 表名 alter column 列名 type 新的数据类型;
-- 修改表products的列price的类型为numeric
alter table products alter column price type numeric(10,2);
--已有的数据能够隐式转换为新的数据类型,如果无法执行隐式转换(例如将字符串‘1’转换为数字 1),
--可以使用 using 执行显式转换
alter table 表名 alter column 列名 type 新的数据类型 using
expression;
--我们先为产品表增加一个字符串类型的字段 level,然后将其修改为整数类型。
alter table products add column level varchar(10);
--修改字段level为整数类型
alter table products alter column level type integer using
level::integer;
重命名字段
alter table 表名 rename column 旧的列名 to 新的列名;
重命名表
alter table 旧的表名 rename to 新的表名;
删除表
drop tale官网介绍
DROP TABLE [ IF EXISTS ] name [ CASCADE | RESTRICT ];
name 表示要删除的表;如果使用了 IF EXISTS,删除一个不存在的表不会产生错误,
而是显示一个信息
如果被删除的表存在依赖于它的视图或外键约束,需要指定 CASCADE 选项执行级联删除。