clog 介绍
专栏内容:
开源贡献:
- toadb开源库
个人主页:我的主页
管理社区:开源数据库
座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物.
文章目录
- clog 介绍
- 前言
- 概述
- 文件格式
- 事务状态
- 文件内部格式
- 文件命名
- clog缓存
- 事务状态记录
- 缓存刷到磁盘
- 缓冲区置换
- checkpoint时
- 服务启动、停止时
- 回收clog段文件
- truncate段文件
- 删除段文件
- 并发控制
- LRU共享内存锁
- 写操作
- 读操作
- 结尾
前言
PostgreSQL是一种开源的关系型数据库管理系统,其内核源码的分析对于深入理解其工作原理、性能优化以及定制开发等方面都具有重要意义。
PostgreSQL的历史可以追溯到1986年,当时Michael Stonebraker和Eugene Wu在加州大学伯克利分校开始了POSTGRES项目的开发。该项目旨在开发一种具有可扩展性和可靠性的关系型数据库管理系统,以满足日益增长的数据库应用需求。在1994年,POSTGRES被发布为开源软件,并更名为PostgreSQL。
PostgreSQL的特点包括支持ACID事务、支持全文搜索、支持存储过程、支持触发器、支持多版本并发控制(MVCC)等。此外,PostgreSQL还支持多种数据类型、支持多种平台、支持多种编程语言接口等。
对于PostgreSQL内核源码的分析,其目的和意义主要体现在以下几个方面:
- 理解工作原理:通过分析内核源码,可以深入理解PostgreSQL的工作原理,包括查询优化、事务管理、并发控制、存储管理等方面的实现细节。
- 性能优化:通过分析内核源码,可以找出性能瓶颈,进行针对性的优化,提高数据库的性能和响应速度。
- 定制开发:通过分析内核源码,可以根据特定需求进行定制开发,例如实现新的数据类型、实现新的查询优化策略等。
- 安全性:通过分析内核源码,可以找出潜在的安全漏洞,进行修复和加固,提高数据库的安全性。
- 可靠性:通过分析内核源码,可以深入理解PostgreSQL的可靠性机制,例如备份与恢复、容错处理等方面的实现细节。
PostgreSQL内核源码的分析是一项重要的任务,对于提高数据库的性能、可靠性、安全性和定制开发能力都具有重要意义。
概述
sql>postgresql数据库中,将事务的状态单独存储在文件中,也就是被称为commit log的文件;文件位置clog目录中,通常是在PostgreSQL数据库安装时创建的,其路径可以在sql>postgresql.conf配置文件中找到。默认情况下,clog目录通常位于PostgreSQL数据库安装目录的“data_directory”参数所指定的目录下,其命名可能因版本而异(例如,在PostgreSQL 16版本中,它被命名为“pg_xact”)。
事务状态在数据库运行过程中,会被用来作为MVCC机制的一部分,判断数据的可见性,所以是非常频繁被读取,同时在大量事务运行时,会有大量事务状态的更新;为了高效的存储和查询,将事务状态采用一种简洁的方式存储,可以很快加载到内存,同时又能快速查找到对应事务的状态,这种方式就非常关键。
本文将从以下几方面进行分享:
- clog文件格式
- clog缓存
- 事务状态记录
- clog的刷盘
- clog文件回收
- 并发控制
文件格式
用什么样的文件格式来记录事务状态呢?
首先来看一下事务有那些状态,再分析文件格式如何组织。
事务状态
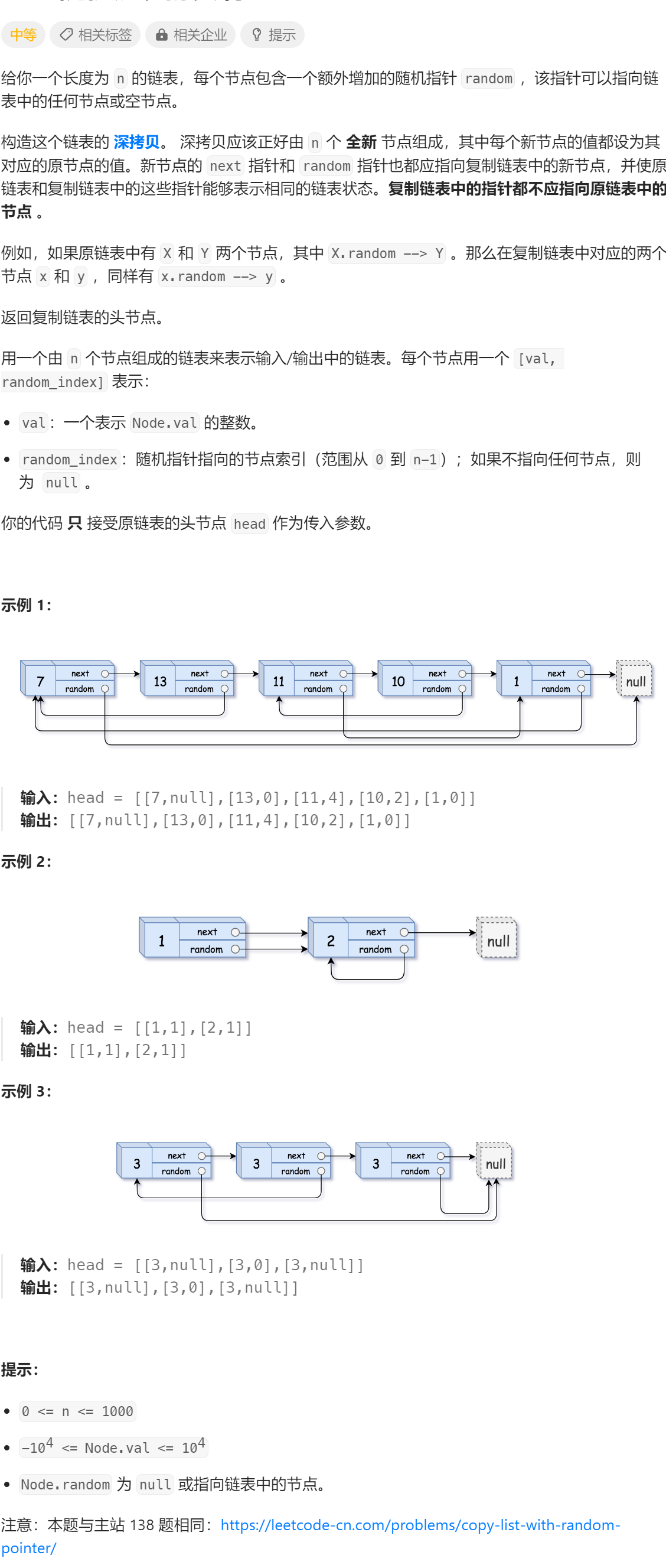
对于每个xid对应的状态,一般有运行中running,提交commit,中止abort三种;而对于事务而言,还有子事务的存在,也就是嵌套事务,子事务也同样存在这三种状态;
这组合起来就多了,在sql>postgresql中是这样组织的,父子事务的关系,由另一个文件进行记录,而对于clog文件来讲,只是记录事务号与状态信息;那这样就简单了。
事务状态分为四种:
- 运行状态
- 已经提交
- 中止状态
- 子事务已提交
这里是不是又有点晕呢? 子事务只记录提交状态,而没有abort状态;
其实子事务的abort状态,并没有区分子事务和父事务,都共用abort状态;这里其实是sql>postgresql做了一点优化,因为只有子事务的提交状态时,还需要再进一步确认父事务状态;而子事务的abort状态,直接就可以确定不可见;所以这里只对子事务的提交单独加了状态,其它同普通事务一样记录状态即可;
文件内部格式
clog的文件结构非常简单,每个文件以8KB为单位组成page;每个page中,以2个bit位为单位表示一个事务的状态;这样一个字节可以表示4个事务,按事务号0,1,… 顺序存储每个事务号的状态;
这样的结构对于修改和查找事务状态,就非常高效,只需要找到事务号对应的偏移就可以了。
#define TransactionIdToPage(xid) ((xid) / (TransactionId) CLOG_XACTS_PER_PAGE)
#define TransactionIdToPgIndex(xid) ((xid) % (TransactionId) CLOG_XACTS_PER_PAGE)
#define TransactionIdToByte(xid) (TransactionIdToPgIndex(xid) / CLOG_XACTS_PER_BYTE)
#define TransactionIdToBIndex(xid) ((xid) % (TransactionId) CLOG_XACTS_PER_BYTE)
可以看到page就是 xid 除以 每个page有多少个事务号;而对应的状态就是取余操作;
文件命名
在sql>postgresql中事务号xid是32位的正整数,不断再循环使用,说明事务号是有限的;
clog文件为了与缓存有映射关系,按缓存大小将事务号划分到不同的文件段中,那么文件命名就按划分后的顺序来命名,0001,0002依次;
取值算法如下:
0xFFFFFFFF/CLOG_XACTS_PER_PAGE/SLRU_PAGES_PER_SEGMENT
#define SlruFileName(ctl, path, seg) \
snprintf(path, MAXPGPATH, "%s/%04X", (ctl)->Dir, seg)
可以看到clog文件也是循环使用,根据事务号的回收,截断不再使用的事务号状态;
clog缓存
事务状态需要在数据库服务重启后还能使用,所以必须记录在磁盘文件中,这就带来一个问题,读写磁盘效率非常低,常规办法就是增加缓冲区;
clog文件并不大,所以采用了SLRU(simple LRU)算法的缓冲区,大小定义如下,单位为block,也就是page大小;
#define SLRU_PAGES_PER_SEGMENT 32
事务状态记录
事务号状态写入,先是计算对应的page,然后看是否已经加载到缓冲区中,如果没有,则先加载到缓冲区中;
/* 获取缓存区的序号,如果不在缓存区中,这里会进行加载 */
slotno = SimpleLruReadPage(XactCtl, pageno, XLogRecPtrIsInvalid(lsn), xid);
在缓冲区中找到对应事务号的偏移,进行位操作即可;
static void
TransactionIdSetStatusBit(TransactionId xid, XidStatus status, XLogRecPtr lsn, int slotno)
{
int byteno = TransactionIdToByte(xid);
int bshift = TransactionIdToBIndex(xid) * CLOG_BITS_PER_XACT;
char *byteptr;
char byteval;
char curval;
byteptr = XactCtl->shared->page_buffer[slotno] + byteno;
curval = (*byteptr >> bshift) & CLOG_XACT_BITMASK;
if (InRecovery && status == TRANSACTION_STATUS_SUB_COMMITTED &&
curval == TRANSACTION_STATUS_COMMITTED)
return;
byteval = *byteptr;
byteval &= ~(((1 << CLOG_BITS_PER_XACT) - 1) << bshift);
byteval |= (status << bshift);
*byteptr = byteval;
if (!XLogRecPtrIsInvalid(lsn))
{
int lsnindex = GetLSNIndex(slotno, xid);
if (XactCtl->shared->group_lsn[lsnindex] < lsn)
XactCtl->shared->group_lsn[lsnindex] = lsn;
}
}
缓存刷到磁盘
事务号的更新都是在缓冲区中进行的,什么时候刷到磁盘呢?数据会丢失吗?
对于有缓冲区设计的程序,我们总会提出这两个问题,下面我们来看sql>postgresql中如何处理clog缓冲区;
主要有以下几个时机,会进行刷盘操作;
缓冲区置换
当缓冲区都满时,又需要加载一个page时,就需要置换一个缓冲区出去,此时如果为脏时,就需要刷盘;
刷盘时调用如下接口进行;
static void SlruInternalWritePage(SlruCtl ctl, int slotno, SlruWriteAll fdata);
checkpoint时
在checkpoint时,会将所有缓存区刷到磁盘上,调用以下接口,内部也是按page进行刷盘;
void
SimpleLruWriteAll(SlruCtl ctl, bool allow_redirtied);
服务启动、停止时
同checkpoint一样,将所有缓存区刷盘;
事务状态数据,并没有随着事务提交一起刷盘,可能会有丢失的情况,如果这种情况发生,也会存在redo,此时可以从WAL恢复事务状态,所以数据完整性和一致性是得到保障的;
回收clog段文件
随着事务号的增加和回卷,有些clog段文件就不再需要,需要进行删除回收;
clog模块通过删除和truncate操作来进行回收段文件;
truncate段文件
在进行checkpoint时,会根据事务号进行判断段文件是否有效,在目录下查找无效的段文件进行truncate;
另外在vacuum时,会更新frozenxid,那么更新后,就会有一些事务号不再使用,也会对整个目录中的段文件进行truncate;
void
SimpleLruTruncate(SlruCtl ctl, int cutoffPage);
当然这里的truncate,不是对文件的truncate,而是对目录中段文件,基实是对无效段文件的删除;
truncate时也会记录一条WAL日志,调用以下接口;
static void
WriteTruncateXlogRec(int pageno, TransactionId oldestXact, Oid oldestXactDb);
删除段文件
当清理multiXact时,如果存在较早的clog,就会将它们删除;或者上面进行trancate时,会批量将旧的clog进行删除;
void
SlruDeleteSegment(SlruCtl ctl, int segno);
并发控制
无论是对于共享缓存区,还是对于clog文件的操作,都会存在多任务同时访问,所以需要一定的并发控制;
对于缓冲区SLRU,会有一个总的controllock,每次需要修改共享缓冲区时,都需要先加此锁;
而对于缓冲区块的操作,每一个缓冲区块会有一个独立的锁,读写缓冲区块时获得此锁即可;
LRU共享内存锁
对于SLRU结构的内容的修改,或者缓冲区替换,段文件操作等,都必须先获取此锁,它在SlruSharedData中定义;
```c
typedef struct SlruSharedData
{
LWLock *ControlLock;
bool *page_dirty;
int *page_number;
int *page_lru_count;
LWLockPadded *buffer_locks;
} SlruSharedData;
LWLockAcquire(shared->ControlLock, LW_EXCLUSIVE);
## 缓冲区块锁
对于每个缓冲区块buffer的操作,每个buffer都定义了一把锁 buffer_locks;
```c
/* Initialize LWLocks */
shared->buffer_locks = (LWLockPadded *) (ptr + offset);
offset += MAXALIGN(nslots * sizeof(LWLockPadded));
为了避免死锁,它的获取前,必须先要加上LRU共享控制锁,然后再获取,获取到时,就可以释放LRU控制锁;
如下所示:
LWLockRelease(shared->ControlLock);
LWLockAcquire(&shared->buffer_locks[slotno].lock, LW_SHARED);
LWLockAcquire(shared->ControlLock, LW_EXCLUSIVE);
LWLockRelease(&shared->buffer_locks[slotno].lock);
写操作
而对于只读操作时,只需要加ControlLock的share锁即可;
int
SimpleLruReadPage_ReadOnly(SlruCtl ctl, int pageno, TransactionId xid)
{
SlruShared shared = ctl->shared;
int slotno;
/* Try to find the page while holding only shared lock */
LWLockAcquire(shared->ControlLock, LW_SHARED);
/* See if page is already in a buffer */
for (slotno = 0; slotno < shared->num_slots; slotno++)
{
if (shared->page_number[slotno] == pageno &&
shared->page_status[slotno] != SLRU_PAGE_EMPTY &&
shared->page_status[slotno] != SLRU_PAGE_READ_IN_PROGRESS)
{
/* See comments for SlruRecentlyUsed macro */
SlruRecentlyUsed(shared, slotno);
/* update the stats counter of pages found in the SLRU */
pgstat_count_slru_page_hit(shared->slru_stats_idx);
return slotno;
}
}
/* No luck, so switch to normal exclusive lock and do regular read */
LWLockRelease(shared->ControlLock);
LWLockAcquire(shared->ControlLock, LW_EXCLUSIVE);
return SimpleLruReadPage(ctl, pageno, true, xid);
}
XidStatus
TransactionIdGetStatus(TransactionId xid, XLogRecPtr *lsn)
{
int pageno = TransactionIdToPage(xid);
int byteno = TransactionIdToByte(xid);
int bshift = TransactionIdToBIndex(xid) * CLOG_BITS_PER_XACT;
int slotno;
int lsnindex;
char *byteptr;
XidStatus status;
/* lock is acquired by SimpleLruReadPage_ReadOnly */
slotno = SimpleLruReadPage_ReadOnly(XactCtl, pageno, xid);
byteptr = XactCtl->shared->page_buffer[slotno] + byteno;
status = (*byteptr >> bshift) & CLOG_XACT_BITMASK;
lsnindex = GetLSNIndex(slotno, xid);
*lsn = XactCtl->shared->group_lsn[lsnindex];
LWLockRelease(XactSLRULock);
return status;
}
对于大并发下的事务状态更新,sql>postgresql 还进行了精细的优化,避免controlLock竞争,增加group的优化,对于在同一个clog page中的事务号更新,只由第一个backend写入clog,其它只是加到grouplist中,利用proc记录进行优化;
读操作
此处获取事务状态,只读操作,如果缓冲区中已经加载了事务号所在的page,此时只加controllock的共享模式;
结尾
非常感谢大家的支持,在浏览的同时别忘了留下您宝贵的评论,如果觉得值得鼓励,请点赞,收藏,我会更加努力!
作者邮箱:study@senllang.onaliyun.com
如有错误或者疏漏欢迎指出,互相学习。
注:未经同意,不得转载!