使用 PostgreSQL 作为全文搜索引擎很诱人,因为它需要的基础设施较少。但它的搜索相关功能集是否足以与基于 Lucene 的替代方案竞争?
在第 1 部分中,我们深入研究了 PostgreSQL 全文搜索的功能,并探讨了如何实现相关性提升(relevancy boosters)、拼写错误容错(ypo-tolerance)和多面搜索(faceted search)等高级搜索功能。在这一部分,我们将它与 Elasticsearch 进行比较。
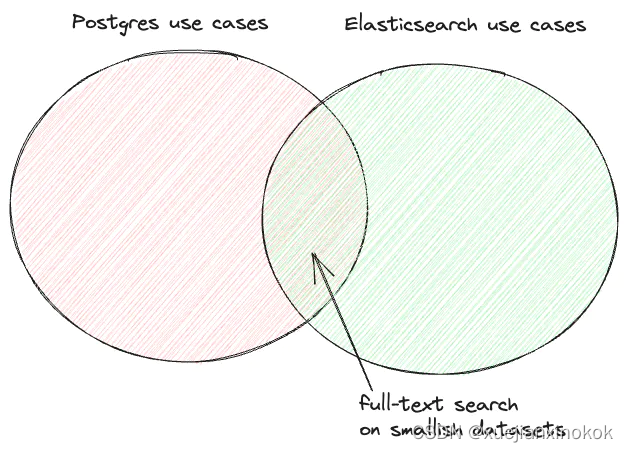
首先,我们要注意的是,Postgres 和 Elasticsearch 通常不会相互竞争。事实上,在架构图中看到它们在一起是很常见的,通常是这样的配置:

在此架构中,数据的真实来源位于 Postgres 中,后者为事务性 CRUD 操作提供服务。数据通过 Postgres 逻辑复制事件(change-data-capture 更改数据捕获)或应用程序本身通过自定义代码持续同步到 Elasticsearch。在此数据复制期间,可能需要非规范化。搜索功能(包括分面和聚合)由 Elasticsearch 提供。
虽然这种架构很常见,但它确实面临一些挑战:
- 处理两种类型的存储意味着更多的运营负担和更高的基础设施成本。
- 保持数据同步比您想象的更具挑战性。我正在计划为这个问题创建一个专门的博客,因为它非常有趣。这么说吧,要完全正确是相当困难的。
- 数据复制充其量是接近实时的,这意味着搜索服务中可能存在一致性问题。
第 2 点通常可以通过工程工作和仔细的专用代码来解决。从现有的工具来看,PGSync是一个开源项目,旨在专门解决这个问题。 ZomboDB 是一个有趣的 Postgres 扩展,它通过 Postgres 控制和查询 Elasticsearch 来解决第 2 点(我认为部分是第 3 点)。我还没有尝试过这两个项目,所以我无法评论它们的权衡,但我想提一下它们。
是的,像 Xata 这样的数据平台通过解决复杂性并将其作为服务以及其他好处提供来解决了大部分第 1 点和第 2 点。
也就是说,如果 Postgres 全文搜索功能足以满足您的用例,那么使用它有望显着简化您的架构和应用程序。在此版本中,Postgres 满足 CRUD 应用程序需求和全文搜索需求:

这意味着您不需要操作两种类型的存储,不再需要数据复制,不再需要非规范化,不再需要最终一致性。 Postgres 内置的搜索引擎恰好支持 ACID 事务、表之间的联接、约束(例如非空或唯一)、引用完整性(外键)以及所有其他使应用程序开发更简单的 Postgres 功能。
因此,难怪我们第 1 部分博客文章的黑客新闻主题对这种方法的优缺点进行了热烈的讨论。我们可以选择仅使用 Postgres 的解决方案,还是“适合工作的最佳工具”这一论点胜出?
我们将比较这两个选项的便利性、搜索相关性、性能和可扩展性。
1. DIY versus built-in
正如我们在第 1 部分中所示,您可以在 Postgres 中复制许多 Elasticsearch 功能,甚至更高级的功能,例如相关性提升、拼写错误、建议/自动完成或语义/矢量搜索(relevancy boosters, typo-tolerance, suggesters/autocomplete, or semantic/vector search)。然而,事情并不总是那么简单。
一个不太简单的例子是拼写错误(在 Elasticsearch 中称为模糊性)。它在 Postgres 中不是开箱即用的,但您可以通过以下步骤实现它:
- 在单独的表中索引所有文档中的所有词素(单词)
- 对于查询中的每个单词,使用相似度或编辑距离在此表中进行搜索
- 修改搜索查询以包含找到的任何单词
虽然上面的方法是完全可行的,但在 Elasticsearch 等专用搜索引擎中,您可以使用一个简单的标志来启用拼写错误:
// POST /recipes/_search
{
"query": {
"multi_match": {
"query": "biscaits",
"fuzziness": 1
}
}
}
2. Search relevancy: BM25 and TF-IDF
Elasticsearch 中关键字搜索的默认排名算法是 BM25。随着 2016 年 Elasticsearch 5.0 的发布,它取代了 TF-IDF 作为默认排名算法。 Postgres 不支持其中任何一个,主要是因为它的排名函数(在此处解释)无法访问这些算法所需的全局词频数据。为了了解相关性(双关语)或不那么相关,让我们从简单到复杂地看看排名函数和算法:
ts_rank(Postgres 函数)- 根据术语频率进行排名。换句话说,它执行 TF-IDF 的“TF”(术语频率)部分。原则是,如果您正在搜索某个单词,则该单词在匹配文档中出现的频率越高,得分就越高。除了使用简单的 TF 之外,Postgres 还提供了将术语频率标准化为分数的方法。例如,一种方法是将其除以文档长度。ts_rank_cd(Postgres 函数)- 排名 + 覆盖密度( cover density)。除了术语频率之外,该函数还考虑“覆盖密度”,即文档中术语的接近(proximity )程度。- TF-IDF - 词频+逆文档频率。除了术语频率之外,该算法还“惩罚”整个数据集中非常常见的单词。因此,如果单词“egg”匹配,但该单词非常常见,因为我们有一个食谱数据集,那么与查询中的其他单词相比,它的价值较低。
- BM25 - 该算法基于相关性概率模型。虽然 TF-IDF 公式主要基于直觉和实际实验,但 BM25 是更正式的数学研究的结果。如果你对上述数学研究感到好奇,我推荐这个演讲,让它变得容易理解。有趣的是,生成的 BM25 公式与 TF-IDF 并没有太大不同,但它包含了更多概念:频率饱和度和文档长度。最终,这可以在更广泛的文档类型上提供更好的结果。
毫无疑问,BM25 是比 ts_rank 或 ts_rank_cd 使用的更先进的相关性算法。 BM25 使用更多的输入信号,它基于更好的启发式算法,并且通常不需要调整。
BM25 的一个实际效果是它会自动惩罚非常常见的单词(“the”、“in”、“or”等),也称为“停用词”,这意味着它们不需要被排除在索引外。这就是为什么 to_tsvector 的 Postgres english 配置删除了停用词(第 1 部分中有详细信息),但 Elasticsearch 标准分析器却没有。不需要。
虽然 BM25 更优越,但有一些支持 Postgres 的论点需要考虑:
- 如果你积极排除停用词,就像 Postgres 中的
english配置所做的那样,这可以弥补某些情况下 IDF 的缺失。 - 实际上,数据本身可能存在更强的相关性信号(点赞、评论等)。请参阅第 1 部分中关于提升相关性的部分,了解如何在 Postgres 中使用它们。
BM25 或 TF-IDF 能否在现有 Postgres 功能之上实现?其实,是的。请参阅这篇使用 ts_stats 和 ts_debug 计算 TF-IDF 的博客文章 。这不是很简单,但是是可能的(与 Postgres 一样)。
3. 性能和可扩展性注意事项(Performance and scalability considerations)
首先让我们注意到这两个系统截然不同:
- PostgreSQL 有一个主节点和多个只读副本,Elasticsearch 通过分片具有水平可扩展性。
- Postgres 是关系型的,支持表连接,具有 ACID 事务,并提供约束,而 Elasticsearch 是面向文档的,仅为每个文档提供一致性保证。
- Postgres 是面向行的,而 Elasticsearch 有一个文档值形式的内部列存储。
- Postgres 是本机 C 代码,而 Elasticsearch 则在 JVM 上运行。
- Postgres 有一个面向连接的有线协议; Elasticsearch 有一个类似于 REST 的基于 HTTP 的 DSL。
所有这些都会影响性能和可扩展性,因此两者往往在不同领域表现出色也就不足为奇了:PostgreSQL 通常用作主数据存储,而 Elasticsearch 通常用作辅助存储,特别是用于按时搜索和分析-系列数据,例如日志。然而,它们确实与全文搜索的用例重叠,这也是这篇博文的重点。
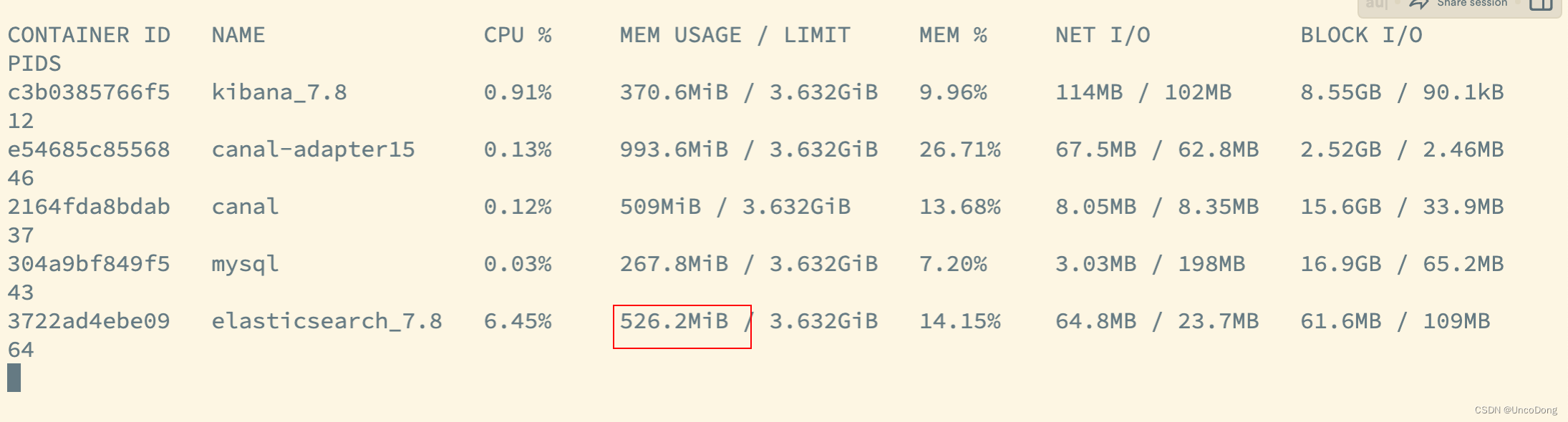
我很想知道与 Elasticsearch 相比,Postgres 大约会减慢多少数据量。在我们在第 1 部分中使用的电影数据集(34K 行)上,所有查询都相当快(<300 毫秒)。因此,为了在这里进行测试,我选择了一个更大的数据集:来自 Kaggle 的菜谱数据集,包含 230 万个菜谱。在 PostgreSQL 中加载 CSV 文件的命令可以在这个要点中找到。对于 Elasticsearch,我使用此工具加载了相同的 CSV 文件。
加载数据后,我开始运行与第 1 部分中使用的搜索类似的搜索:
SELECT title, ts_rank(search, websearch_to_tsquery('english', 'darth vader')) rank
FROM recipes WHERE search @@ websearch_to_tsquery('english','darth vader')
ORDER BY rank DESC limit 10;
title | rank
----------------------+------------
Darth Vader Biscuits | 0.09910322
Cloud 9 Pancakes | 0.09910322
(2 rows)
Time: 100.468 ms
对于 Elasticsearch,我使用以下命令来运行搜索:
// POST /recipes/_search
{
"query": {
"query_string": {
"query": "darth AND vader"
}
}
}
我将每个查询运行五次并记录最好和最差的时间。通常,第一个查询是最慢的,因为后续查询受益于内存中已有的相关页面。虽然这种方法相当不科学,并且您应该在得出明确的结论之前对数据进行自己的基准测试,但它应该足以得出一些初步结论。
以下是一些查询的结果:
| query | Elasticsearch worst time (ms) | Elasticsearch best time (ms) | Postgres worst time (ms) | Postgres best time (ms) |
|---|---|---|---|---|
| darth vader | 52 | 4 | 100 | 3 |
| chicken nuggets | 85 | 10 | 313 | 13 |
| pancake | 60 | 4 | 618 | 157 |
| curacao | 286 | 7 | 230 | 10 |
| mix | 67 | 5 | 25182 | 8267 |
正如您所看到的,Postgres 在某些查询(例如“darth vader”或“curacao”)上表现良好,可在几毫秒内做出响应。然而,对于“pancake”或“mix”等其他查询,它的性能明显比 Elasticsearch 差,响应时间以秒为单位。延迟甚至高达 25 秒!这里发生了什么?
区别在于有多少行与查询条件匹配。在食谱数据集中搜索“darth vader”会匹配 2 行。但在食谱数据集中搜索“mix”会匹配一百万行(准确地说,是 1,038,914 行)。由于我们按排名排序,Postgres 需要为百万行中的每一行调用 ts_rank 函数。 Postgres 文档甚至对此发出警告:
Ranking can be expensive since it requires consulting the
tsvectorof each matching document, which can be I/O bound and therefore slow. Unfortunately, it is almost impossible to avoid since practical queries often result in large numbers of matches.
排名的成本可能很高,因为它需要查阅每个匹配文档的tsvector,这可能受 I/O 限制,因此速度很慢。不幸的是,这几乎是不可能避免的,因为实际查询通常会导致大量匹配。
确实,问题出在排名上。如果我们只对匹配感兴趣并且按(索引)列排序,那么速度很快:
SELECT title FROM recipes
WHERE search @@ websearch_to_tsquery('english','mix')
ORDER BY title ASC LIMIT 10;
Time: 24.681 ms
但我们正在假设排名对于良好的搜索体验是必要的。一种想法是使用我所说的“采样”:在计算排名之前,抽取 10K 匹配行的样本。假设是,如果您的查询匹配如此多的文档,无论如何排名都可能无效,因此最好优先考虑响应时间。
执行此操作的 SQL 如下所示:
WITH search_sample AS (
SELECT title, search FROM recipes
WHERE search @@ websearch_to_tsquery('english','mix')
LIMIT 10000)
SELECT title, ts_rank(search, websearch_to_tsquery('english', 'mix')) rank
FROM search_sample
ORDER BY rank DESC limit 10;
使用此示例方法重新运行测试可以给我们带来更接近的结果:
| query | Elasticsearch worst time (ms) | Elasticsearch best time (ms) | Postgres worst time (ms) | Postgres best time (ms) |
|---|---|---|---|---|
| darth vader | 52 | 4 | 100 | 3 |
| chicken nuggets | 85 | 10 | 195 | 14 |
| pancake | 60 | 4 | 145 | 13 |
| curacao | 286 | 7 | 225 | 11 |
| mix | 67 | 5 | 400 | 144 |
好多了!当然,我们确实牺牲了相关性,这对于您的情况可能会也可能不会。
以下是关于性能和可扩展性主题的一些结论和更多考虑因素:
- 在较小数据集(<100K 行)上的搜索用例中,两个系统都将表现良好,但仅使用 Postgres 的解决方案将需要更少的资源。
- 在中等数据集(几百万行)上,Elasticsearch 已经更快,但是,如果您使用上面解释的采样技巧,Postgres 可以在 200 毫秒的延迟内执行。
- 当文档数量非常大(例如日志或其他时间序列)时,Elasticsearch 具有水平可扩展性的额外优势。
- 如果您需要大量聚合或分析(例如显示充满图表的仪表板)并且数据集足够大,Elasticsearch 的列式存储将给它带来优势。
- 给 Postgres 额外的工作负载可能会影响主实例的性能。解决方案是将搜索转移到副本,但这样您就会失去一些一致性保证。
4. 语义和混合搜索(Semantic and hybrid search)
第 1 部分和这篇博文都重点介绍了关键字搜索技术。然而,在过去的几年里,语义/向量搜索已经席卷了搜索世界,所以我觉得在比较两者时我也需要触及这个方面。
语义搜索利用语言模型为每个文档生成词嵌入。嵌入是在多个维度上表示文本的数字数组。具有相似嵌入的文本片段具有相似的含义。换句话说,语义搜索可以“按含义搜索”,而不是“按关键字”。现在这非常令人兴奋,因为大型语言模型(LLM)让我们能够非常准确地理解含义。这意味着您不必维护同义词列表或向文档添加不同的关键字来匹配用户的搜索方式。
Postgres 通过 pgvector 扩展支持矢量搜索,而 Elasticsearch 通过 KNN 搜索内置它。您可以在 ann-benchmarks 上找到基准(查找 pgvector 和 luceneknn ),但请记住,这两种实现都正在积极开发中,并且它们的性能正在得到改进。
虽然令人兴奋,但事实证明,仅靠语义搜索在我们今天拥有的典型搜索体验上并不能发挥很好的作用——至少在大多数数据集上是这样。如果您好奇,我最近针对为 ChatGPT 选择上下文的特定用例编写了关键字搜索和语义搜索之间的比较。
对于像本博文中的菜谱这样的搜索用例,混合搜索可能会提供更好的结果:使用关键字和语义搜索的组合来提高排名。
Elastic 最近宣布了他们的“Elasticsearch 相关性引擎”,其中包括混合搜索。在 Postgres 中,考虑到它都是构建块,您可以将全文搜索功能和 pgvector 结合起来。我也期待着更深入地探讨这个主题,但我会将其留到后续博客文章中。
5. 结论
在纯 Postgres 架构和 Postgres + Elasticsearch 架构之间进行选择将取决于您的用例和规模。
例如,如果您的应用程序中有一个支持 CRUD 操作的表或列表,并且您想向其中添加全文搜索功能,那么 Postgres 可能会在相当长的一段时间内为您提供良好的服务。
另一方面,如果您有一个大型数据集搜索,并且搜索相关性对您的应用程序至关重要(例如,在电子商务中),那么使用 Elasticsearch 这样的专用搜索引擎将在延迟和相关性方面表现更好。
在许多情况下,从更简单的纯 Postgres 方法开始可能是有意义的,但要准备好在需要时转向 Postgres + Elasticsearch 架构。
如果您读到这里,您可能想尝试一下 Xata。它在同一个数据平台中提供 Postgres 和 Elasticsearch,并且还可以轻松处理它们之间的同步。如果您对此博文有任何反馈,或者对后续博文感兴趣,您可以在 Twitter 上关注我们或在 Discord 中加入我们。
Written by Tudor Golubenco
Published on July 19, 2023
原文地址