最近的一套PostgreSQL(12.6)数据库在进行UAT测试的时候,发现服务器空间爆满,导致了PostgreSQL异常关闭。问题发生后,现场的DBA让我配合做了如下的一些分析,这里去除敏感信息,分享给大家。
一、问题分析
问题发生的时候,现场的DBA其实经过检查发现了暴涨的源头是这个pgsql_tmp目录,
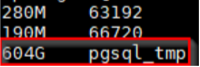
而且现场的DBA在PostgreSQL异常关闭前,用strings去看pgsql_temp里面的文件,确认是对应的数据,而且根据文件的命名方式,通过pid查询到了产生临时文件的SQL,SQL是一个select语句,并且涉及到fdw远程表,这方便了我们后续对问题的分析。

select * from pg_stat_activity where pid='24518';
通过查看这个SQL的执行计划,我们可以看到有两个sort环节,而且都是在PostgreSQL端执行的。
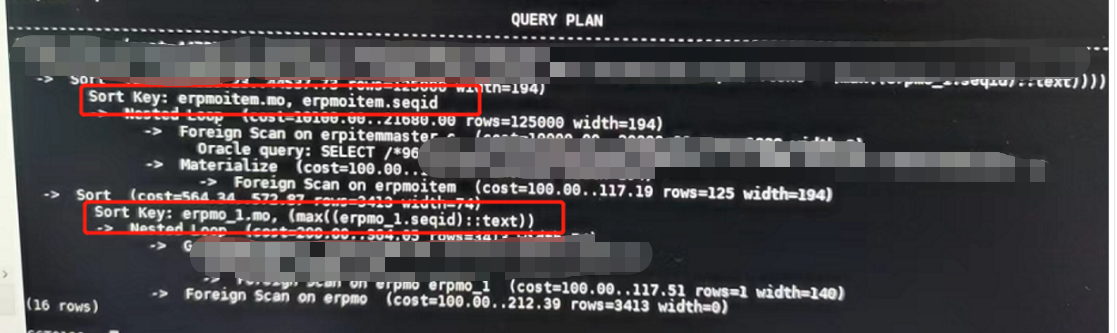
然后看一下涉及的sort列的表的情况,发现这几列都是字符类型的。要知道oracle_fdw的排序字段是字符类型的时候是不会不下推到oracle端的,但是数字和时间类型都是可以的,因此这个SQL的排序他会先把数据拿到PostgreSQL的内存里,即work_mem里去做这个sort操作。
下推:FDW采用一种称为 pushdown 的机制,它允许远程端执行 WHERE、ORDER BY 和 JOIN 子句。下推 WHERE 和 JOIN 减少了本地和远程服务器之间传输的数据量,避免了网络通信瓶颈。
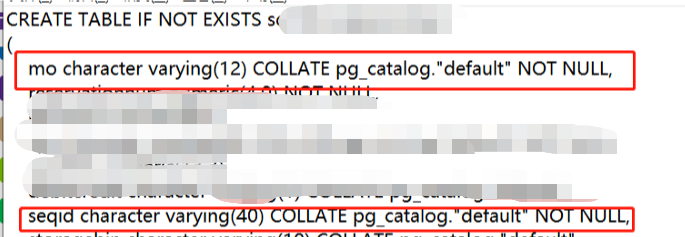
到这里,我和现场DBA确认了下他们work_mem的大小,经过确认,他们work_mem的值为4MB,也就是默认值,对于这个SQL来说,work_mem明显太小了,这个参数是写入临时文件之前内部排序操作和散列表使用的内存量,超出后,就会溢出到磁盘写到pgsql_tmp下的临时文件里,当开始将临时文件写入磁盘时,显然会比内存慢得多,而且临时文件的太大也可能把空间填满。
其实可以在启用log_temp_files后,在PostgreSQL日志中搜索temporary file来查看是否溢出到了磁盘。如果看到了temporary file,就意味着可能需要增加work_mem了。
而且不容忽视的一点是:work_mem这个参数和max_connection是有联系的,假设你设置为10MB,则500个用户同时执行查询排序,很快就会使用5GB的实际内存。或者涉及复杂计算,涉及几张表的合并,就要用到几倍的work_mem。因此work_mem是不适宜设置的很大的,如果设置超出256MB,其实很容易因为瞬间的大并发操作导致OOM问题
此外,其实可以通过使用explain analyze 这个SQL去查看这个它执行所需要的内存大小,但生产的环境基本不允许我们随意explain analyze,因为它会实际执行SQL,如果是问题SQL,不仅可能影响数据库性能、严重甚至造成宕机。而且explain analyze命令跟insert、update、delete的操作更是会修改数据,这是我们绝对不能做的。
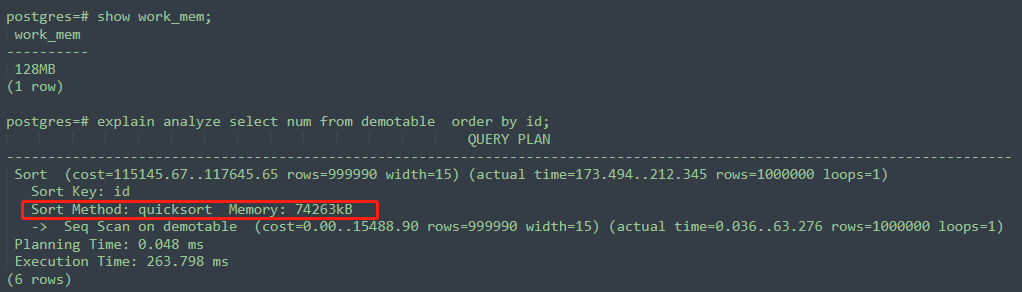
下边我在自己的测试环境给大家演示一下,work_mem对于执行计划的影响,我原本的work_mem值也是4MB没有修改:
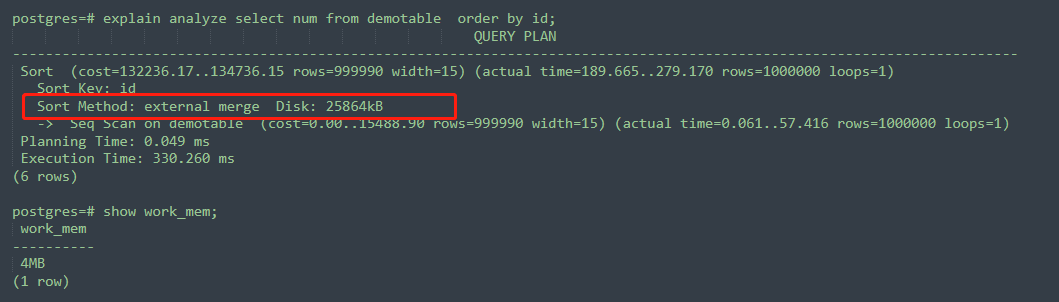
可以看到,这个SQL的执行计划里,Sort Method部分是external merge Disk,代表了外部合并磁盘,也就是溢出到了磁盘,生成了临时文件。可以看到这个SQL的执行计划里Disk:25864KB,大概有25MB,那我work_mem的值改成128MB,会怎样呢 ,如下所示,相同的SQL,Sort Method部分变成了quicksort Memory ,此时sort的数据都是放在内存里的,而没有溢出磁盘。
二、结论
通过上面的分析,我们知道这次的问题,主要是出在了oracle_fdw处理SQL的sort操作的的时候字符类型不能下推,而且在PostgreSQL本地进行sort的时候,超出了work_mem的设置,导致溢出到磁盘,我们可以把work_mem的值稍微提升一点,但一定不要过大,否则业务的瞬间高并发很可能导致OOM。而且对于work_mem的大小我们肯定是要根据平时的业务以及并发量来综合评估的,基本确定了一个值不会去轻易改动,不能对于个别SQL进行调整,这样也不利于数据库的稳定性。因此,最好的方式还是结合业务看是否这条SQL能进行调整,修改sort的列的类型,或者调整写法让其能下推到oracle端执行,减少传输到PostgreSQL本地的数据量。除此之外我们也可以使用temp_file_limit这个参数对此类临时文件的大小做一个限制,避免数据目录的爆满。



![[做初中数学题做到打起来了]跟同事为了他小孩的数学题杠上了](https://img-blog.csdnimg.cn/4bc0ef536e194313977918186d219226.png)