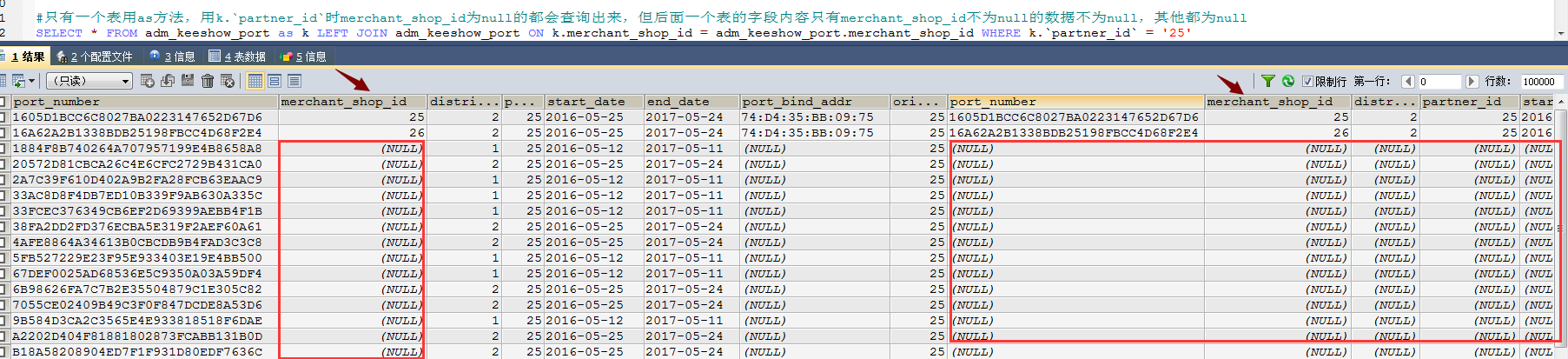
EXPLAIN命令
PG中EXPLAIN命令语法格式如下:
EXPLAIN [(option[,...])] statement
EXPLAIN [ANALYZE] [VERBOSE] statement
该命令的options如下:
- ANALYZE [boolean]
- VERBOSE [boolean]
- COSTS [boolean]
- BUFFERS [boolean]
- FORMAT {TEXT | XML | JSON | YAML}
-
ANALYZE 选项通过实际执行SQL来获得SQL命令的实际执行计划。ANALYZE选项查看到的执行计划因为真正被执行过,所以可以看到执行计划每一步耗费了多长时间,以及它实际返回的行数。
-
如果SQL语句是一个插入、删除、更新或者CREATE TABLE AS语句(这些语句会修改数据库),为了不影响实际数据,可以把EXPLAIN ANALYZE放到一个事务中,执行完后回滚事务:
BEGIN;
EXPLAIN ANALYZE…;
ROLLBACK;
-
-
VERBOSE选项显示计划的附加信息,如计划树中每个节点输出的各个列,如果触发器被触发,还会输出触发器的名称。该选项的默认值为FALSE。
-
COST选项显示每个计划节点的启动成本和总成本,以及估计行数和每行宽度。该选项的默认值为TRUE。
-
BUFFERS选项显示缓冲区使用的信息,只能与ANALYZE参数一起使用,默认值为FALSE。
-
FORMAT选项指定输出格式,可以是TEXT、XML、JSON或者YAML。默认值为TEXT。
EXPLAIN输出结果解释
如下是一个简单的EXPLAIN输出结果解释:

- Seq Scan on jxx_test 表示顺序扫描表jxx_test,顺序扫描也就是全表扫描
- cost=0.00…22.70 cost=后面有两个数字,中间由“…”分隔,第一个数字0.00表示启动的成本,也就是说返回第一行需要多少cost值;第二个数字表示返回所有数据的成本;
- rows=1270:表示会返回1270行,但是表中只有一条数据,真实执行计划需要analyze参数
- width=36:表示每行平均宽度为36字节
成本cost用于描述SQL命令的执行代价,默认情况下,不同操作的cost值如下:
- 顺序扫描一个数据块,cost值为1
- 随机扫描一个数据块,cost值为4
- 处理一个数据行的CPU代价,cost值为0.01
- 处理一个索引行的CPU代价,cost值为0.005
- 每个操作符的CPU代价为0.0025
根据上面的操作类型,PG可以智能计算出一个SQL命令的执行代价,虽然计算结果不是很精确,但大多数情况下够用了。
EXPLAIN 使用示例
默认情况下输出的执行计划是文本格式,也可以输出JSON格式,如下:
文本格式
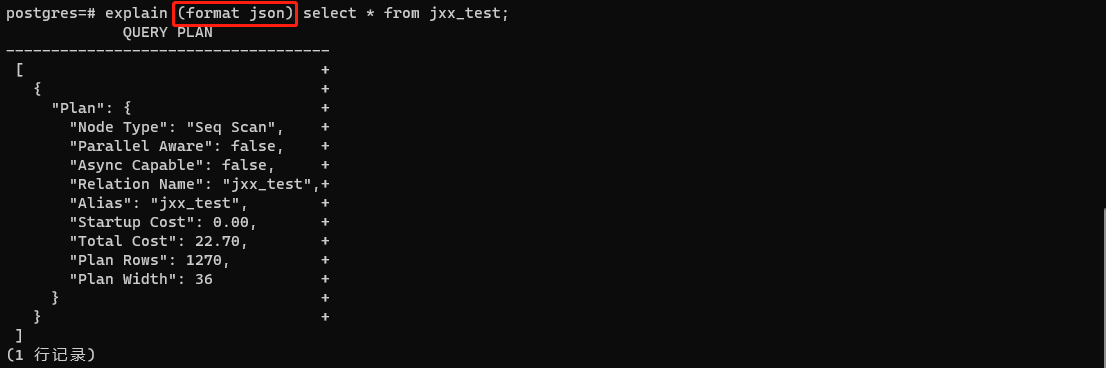
其他格式均支持,例如:XML、YAML等格式
精确执行analyze
添加analyze参数获得更精确的执行计划:

只查看执行路径
如果值查看执行的路径而不看cost值,可以添加costs false选项:

实际代价与缓冲区命中
联合使用analyze选项和buffers选项,通过实际执行来查看实际的代价和缓冲区命中的情况:

Buffers: shared hit=16257 read=918323
- shared hit=16257 表示在共享内存中直接读到16257个块
- read=918323 从磁盘中读到918323个块
- select语句有可能也会出现写,如written=? 因为共享内存中有脏块,从磁盘中读出的块必须把内存中的脏块挤出内存,所以会产生写
全表扫描
全表扫描在PG中也称为顺序扫描(Seq Scan),全表扫描就是把表中的所有数据块从头到尾读一遍,然后从中找到符合条件的数据块。

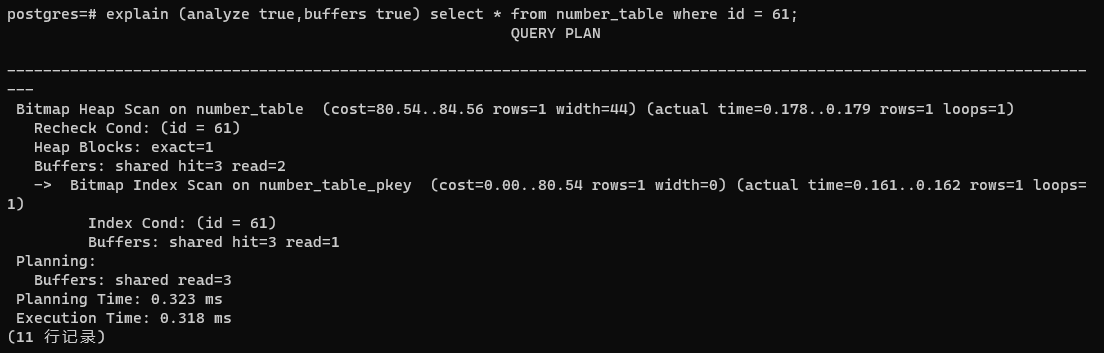
索引扫描
索引通常是为了加快查询数据的速度而增加的。索引扫描,就是在索引中找出需要的数据行的物理位置,然后再到表的数据块中把相应的数据读出来的过程。
索引扫描在explain命令的输出结果中用Index Scan表示:
位图扫描
位图扫描也是走索引的一种方式。方法是扫描索引,把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图到表的数据文件中把相应的数据读出来。如果走了两个索引,可以把两个索引形成的位图通过AND或OR计算合并成一个,再到表的数据文件中把数据读出来。
当执行计划的结果行数很多时会走这种扫描,如非等值查询、IN子句或有多个条件都可以走不同的索引时。
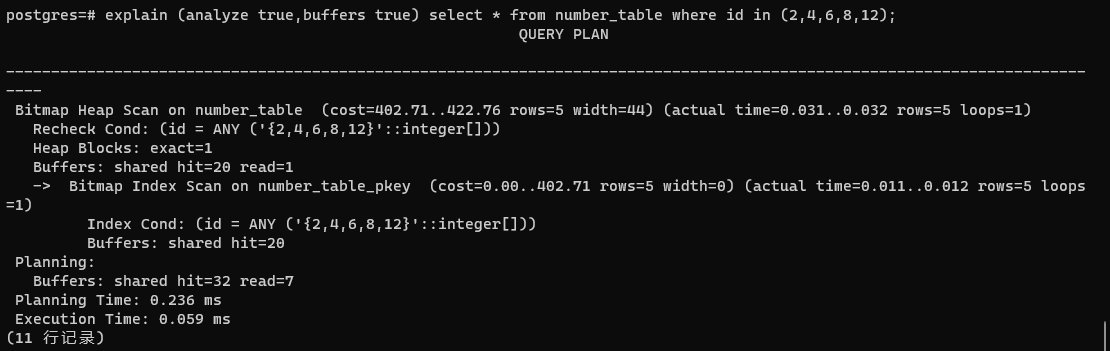
- Bitmap Index Scan先在索引中找到符合条件的行
- 创建位图
- 根据位图到表中扫描,也就是Bitmap Heap Scan
下面是走两个索引后将位图继续进行BitmapOr运算的示例:

从上图执行计划可以看到BitmapOr操作,即使用OR运算合并两个位图