目录
PostgreSQL实战之体系结构
前言
1 逻辑和物理存储结构
1.1 逻辑存储结构
1.2 物理存储结构
2 进程结构
2.1 守护进程与服务进程
2.2 辅助进程
3 内存结构
3.1 本地内存
3.2 共享内存
PostgreSQL实战之体系结构
前言
PostgreSQL数据库是由一系列位于文件系统上的物理文件组成,在数据库运行过程中,通过整套高效严谨的逻辑管理这些物理文件。通常将这些物理文件称为数据库,将这些物理文件、管理这些物理文件的进程、进程管理的内存称为这个数据库的实例。在PostgreSQL的内部功能实现上,可以分为系统控制器、查询分析器、事务系统、恢复系统、文件系统这几部分。其中系统控制器负责接收外部连接请求,查询分析器对连接请求查询进行分析并生成优化后的查询解析树,从文件系统获取结果集或通过事务系统对数据做处理,并由文件系统持久化数据。本章将简单介绍PostgreSQL的物理和逻辑结构,同时介绍PostgreSQL实例在运行周期的进程结构。
1 逻辑和物理存储结构
在PostgreSQL中有一个数据库集簇(Database Cluster)的概念,也有一些地方翻译为数据库集群,它是指由单个PostgreSQL服务器实例管理的数据库集合,组成数据库集簇的这些数据库使用相同的全局配置文件和监听端口、共用进程和内存结构,并不是指“一组数据库服务器构成的集群”,在PostgreSQL中说的某一个数据库实例通常是指某个数据库集簇,这一点和其他常见的关系型数据库有一定差异,请读者注意区分。
1.1 逻辑存储结构
数据库集簇是数据库对象的集合,在关系数据库理论中,数据库对象是用于存储或引用数据的数据结构,表就是一个典型的例子,还有索引、序列、视图、函数等这些对象。在PostgreSQL中,数据库本身也是数据库对象,并且在逻辑上彼此分离,除数据库之外的其他数据库对象(例如表、索引等)都属于它们各自的数据库,虽然它们隶属同一个数据库集簇,但无法直接从集簇中的一个数据库访问该集簇中的另一个数据库中的对象。
数据库本身也是数据库对象,一个数据库集簇可以包含多个Database、多个User,每个Database 以及 Database中的所有对象都有它们的所有者:User。

创建一个Database时会为这个Database创建一个名为public的默认Schema,每个Database可以有多个Schema,在这个数据库中创建其他数据库对象时如果没有指定Schema,都会在public这个Schema中。Schema可以理解为一个数据库中的命名空间,在数据库中创建的所有对象都在Schema中创建,一个用户可以从同一个客户端连接中访问不同的Schema。不同的Schema中可以有多个相同名称的Table、Index、View、Sequence,Function等数据库对象。
1.2 物理存储结构
数据库的文件默认保存在initdb时创建的数据目录中。在数据目录中有很多类型、功能不同的目录和文件,除了数据文件之外,还有参数文件、控制文件、数据库运行日志及预写日志等。
1.数据目录结构
数据目录用来存放PostgreSQL持久化的数据,通常可以将数据目录路径配置为PGDATA环境变量,查看数据目录有哪些子目录和文件的命令如下所示:
tree -L 1 -d /pgdata/10/data对数据目录中子目录和文件的用途进行了说明。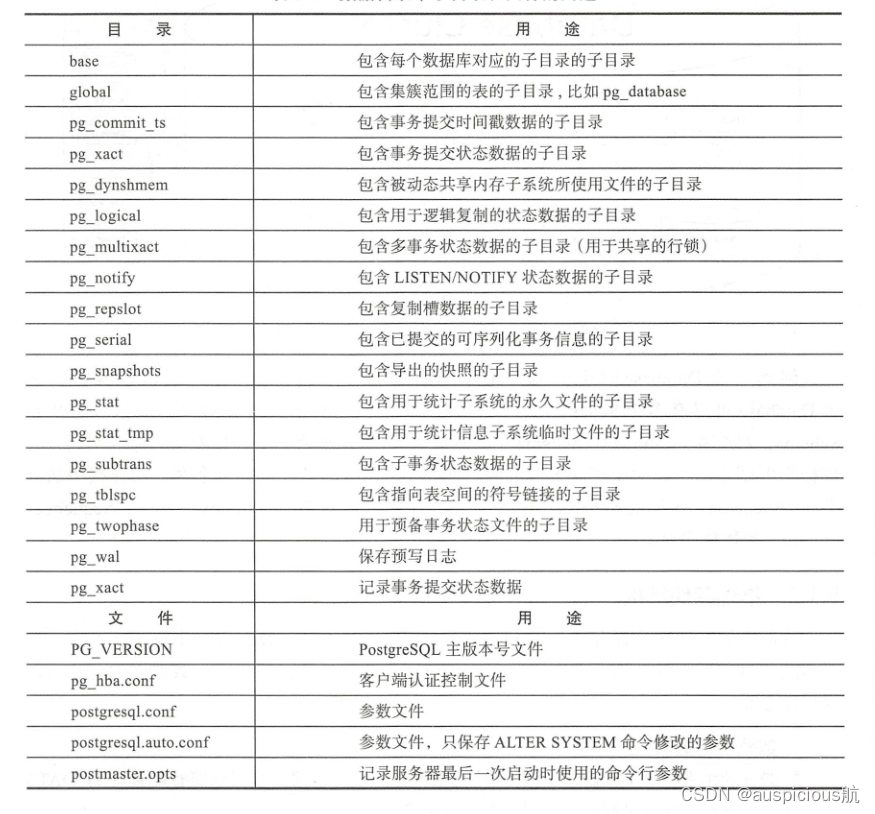
2.数据文件布局
数据目录中的base子目录是我们的数据文件默认保存的位置,是数据库初始化后的默认表空间。在讨论base目录之前,我们先了解两个基础的数据库对象:OID和表空间。
( 1 )OID
PostgreSQL中的所有数据库对象都由各自的对象标识符(OID)进行内部管理,它们是无符号的4字节整数。数据库对象和各个OID之间的关系存储在适当的系统目录中,具体取决于对象的类型。数据库的OID存储在pg_database系统表中,可以通过如下代码查询数据库的OID:

数据库中的表、索引、序列等对象的OID存储在pg_class系统表中,可以通过如下代码查询获得这些对象的OID:

(2)表空间
在PostgreSQL中最大的逻辑存储单位是表空间,数据库中创建的对象都保存在表空间中,例如表、索引和整个数据库都可以被分配到特定的表空间。在创建数据库对象时,可以指定数据库对象的表空间,如果不指定则使用默认表空间,也就是数据库对象的文件的位置。初始化数据库目录时会自动创建pg_default和 pg_global两个表空间。如下所示:
- pg_global表空间的物理文件位置在数据目录的global目录中,它用来保存系统表。
- pg_default表空间的物理文件位置在数据目录中的 base目录,是 template0和template1数据库的默认表空间,我们知道创建数据库时,默认从template1数据库进行克隆,因此除非特别指定了新建数据库的表空间,默认使用template1的表空间,也就是pg_default。
除了两个默认表空间,用户还可以创建自定义表空间。使用自定义表空间有两个典型的场景:
- 口通过创建表空间解决已有表空间磁盘不足并无法逻辑扩展的问题;
- 将索引、WAL、数据文件分配在性能不同的磁盘上,使硬件利用率和性能最大化。
由于现在固态存储已经很普遍,这种文件布局方式反倒会增加维护成本。
要创建一个表空间,先用操作系统的postgres用户创建一个目录,然后连接到数据库,使用CREATE TABLESPACE命令创建表空间,如下所示:
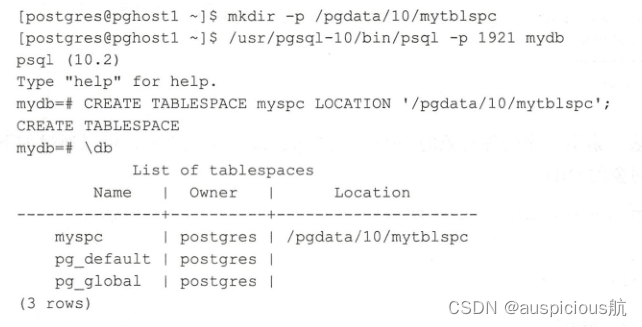
当创建新的数据库或表时,便可以指定刚才创建的表空间,如下所示:
mydb=# CREATETABLE t(id SERIAL PRIMARY KEY,ival int)TABLESPACE myspc;
CREATETABLE由于表空间定义了存储的位置,在创建数据库对象时,会在当前的表空间目录创建一个以数据库OID命名的目录,该数据库的所有对象将保存在这个目录中,除非单独指定表空间。例如我们一直使用的数据库mydb,从pg_database系统表查询它的OID,如下所示:
mydb=# SELECT oid,datname FROM pg_database WHERE datname = 'mydb ';
oid | datname
-----------|-------------
16384 | mydb
( 1 row )通过以上查询可知 mydb 的OID为16384,我们就可以知道mydb的表、索引都会保存在$SPGDATA/base/16384这个目录中,如下所示:
[postgres@pghost1 ~]$ ll /pgdata/10/data/base/16384/
-rw---------- 1 postgres postgres 16384 Nov 28 21:22 3712
...
...
...
-rw---------- 1 postgres postgres 8192 Nov 28 21:22 3764_vm
( 3)数据文件命名
在数据库中创建对象,例如表、索引时首先会为表和索引分配段。在PostgreSQL中,每个表和索引都用一个文件存储,新创建的表文件以表的oID命名,对于大小超出1GB的表数据文件,PostgreSQL会自动将其切分为多个文件来存储,切分出的文件用oID.<顺序号>来命名。但表文件并不是总是“OID.<顺序号>”命名,实际上真正管理表文件的是pg_class表中的relfilenode字段的值,在新创建对象时会在pg_class系统表中插人该表的记录,默认会以OID作为relfilenode的值,但经过几次VACUUM、TRUNCATE操作之后,relfilenode的值会发生变化。
mydb=# SELECT oid,relfilenode FROM pg_class WHERE relname = 'tbl ' ;
oid | relfilenode
----------+-------------
16387 | 16387
(1 row)
mydb=# \!ls -l /pgdata/10/data/base/16384/16387*
-rw------- 1 postgres postgres 8192 Mar 26 22:22 /pgdata/10/data/base/16384/16387
在默认情况下,tbl表的OID为16387,relfilenode也是16387,表的物理文件为“/pgdata/10/data/base/16384/16387”。依次TRUNCATE 清空tbl表的所有数据,如下所示:
mydb=# TRUNCATE tbl;
TRUNCATETABLE
mydb=# CHECKPOINT;CHECKPOINT
mydb=# \! ls -l /pgdata/10/data/base/16384/16387*
ls: cannot access /pgdata/10/data/base/16384/16387+: No such file or directory
通过上述操作之后,tbl表原先的物理文件“/pgdata/10/data/base/16384/16387”已经不存在了,那么tbl表的数据文件是哪一个?
postgres@160.40:1922/mydb=# select oid,relfilenode from pg_class where relname = 'tbl ';
oid | relfilenode
16387 | 24591
(1 row)
postgres@160.40:1922/mydb=# \ ! ls -l /pgdata/10/data/base/16384/24591*
-rw------- 1 postgres postgres 0 Apr 2 21:24 /pgdata/10/data/base/16384/24591
如上所示,再次查询pg_class表得知 tbl表的数据文件已经成为“/pgdata/10/datalbase/16384/24591”,它的命名规则为<relfilenode>.<顺序号>。
如前文所述,数据文件的命名规则为<relfilenode>.<顺序号>,tbl表的大小超过1GB,tbl表的relfilenode 为24591,超出1GB之外的数据会按每GB切割,在文件系统中查看时就是名称为24591.1的数据文件。在上述输出结果中,后缀为_fsm和_vm的这两个表文件的附属文件是空闲空间映射表文件和可见性映射表文件。空闲空间映射用来映射表文件中可用的空间,可见性映射表文件跟踪哪些页面只包含已知对所有活动事务可见的元组,它也跟踪哪些页面只包含未被冻结的元组。。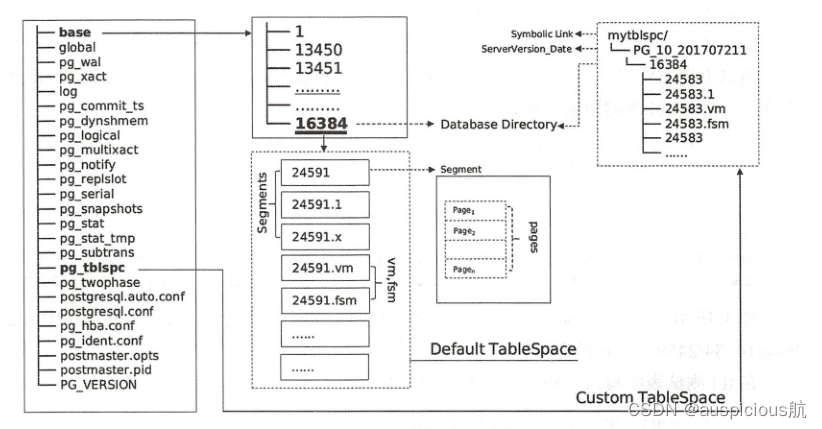
( 4))表文件内部结构
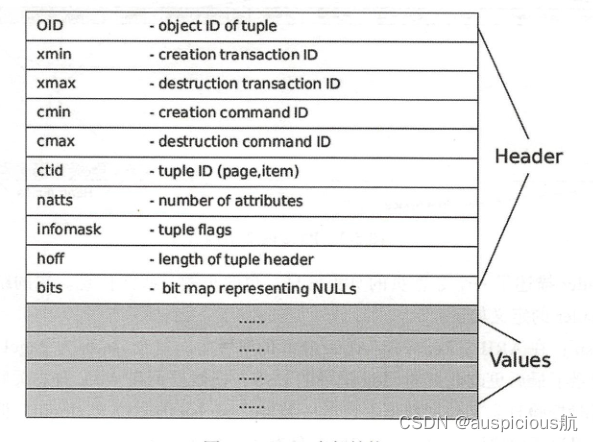
在PostgreSQL中,将保存在磁盘中的块称为Page,而将内存中的块称为Buffer,表和索引称为Relation,行称为Tuple,如图5-3所示。数据的读写是以Page为最小单位,每个Page默认大小为8kB,在编译PostgreSQL时指定的BLCKSZ大小决定Page的大小。每个表文件由多个BLCKSZ字节大小的Page组成,每个Page包含若干Tuple。对于IO性能较好的硬件,并且以分析为主的数据库,适当增加BLCKSZ大小可以小幅提升数据库性能。

PageHeader描述了一个数据页的页头信息,包含页的一些元信息。它的结构及其结构指针PageHeader的定义如下:
- pd_lsn:在 ARIES Recovery Algorithm 的解释中,这个lsn称为PageLSN,它确定和记录了最后更改此页的xlog记录的LSN,把数据页和WAL日志关联,用于恢复数据时校验日志文件和数据文件的一致性;pd_lsn的高位为xlogid,低位记录偏移量;因为历史原因,64位的LSN保存为两个32位的值。
- pg_flags:标识页面的数据存储情况。
- pd_special :指向索引相关数据的开始位置,该项在数据文件中为空,主要是针对不同索引。
- pd_lower:指向空闲空间的起始位置。
- pd_upper:指向空闲空间的结束位置。
- pd_pagesize_version:不同的 PostgreSQL版本的页的格式可能会不同。
- pd_linp[1]:行指针数组,即图5-3中的Item1,Item2,...,Item,这些地址指向Tuple的存储位置。
如果一个表由一个只包含一个堆元组的页面组成。该页面的pd_lower指向第一行指针,并且行指针和pd_upper都指向第一个堆元组。当第二个元组被插入时,它被放置在第一个元组之后。第二行指针被压入第一行,并指向第二个元组。pd_lower更改为指向第二行指针,pd_upper更改为第二个堆元组。此页面中的其他头数据(例如,pd_Isn、pg_checksum、pg_flag)也被重写为适当的值。
当从数据库中检索数据时有两种典型的访问方法,顺序扫描和B树索引扫描。顺序扫描通过扫描每个页面中的所有行指针顺序读取所有页面中的所有元组。B树索引扫描时,索引文件包含索引元组,每个元组由索引键和指向目标堆元组的TID组成。如果找到了正在查找的键的索引元组,PostgreSQL使用获取的TID值读取所需的堆元组。
每个Tuple包含两部分的内容,一部分为HeapTupleHeader,用来保存Tuple的元信息。
完整的文件布局

2 进程结构
PostgreSQL是一用户一进程的客户端/服务器的应用程序。数据库启动时会启动若干个进程,其中有postmaster(守护进程)、postgres(服务进程)、syslogger、checkpointer、bgwriter、walwriter等辅助进程。
2.1 守护进程与服务进程
首先从postmaster(守护进程)说起。postmaster进程的主要职责有:
当客户端调用接口库向数据库发起连接请求,守护进程postmaster 会 fork单独的服务进程postgres为客户端提供服务,此后将由 postgres进程为客户端执行各种命令,客户端也不再需要postmaster 中转,直接与服务进程postgres通信,直至客户端断开连接。
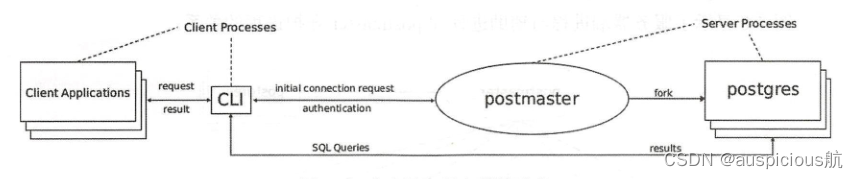
PostgreSQL使用基于消息的协议用于前端和后端(服务器和客户端)之间通信。通信都是通过一个消息流进行,消息的第一个字节标识消息类型,后面跟着的四个字节声明消息剩下部分的长度,该协议在TCP/IP和Unix域套接字上实现。服务器作业之间通过信号和共享内存通信,以保证并发访问时的数据完整性。
2.2 辅助进程
除了守护进程postmaster和服务进程postgres外,PostgreSQL在运行期间还需要一些辅助进程才能工作,这些进程包括:
- background writer :也可以称为bgwriter进程,bgwriter进程很多时候都是在休眠状态,每次唤醒后它会搜索共享缓冲池找到被修改的页,并将它们从共享缓冲池刷出。
- autovacuum launcher:自动清理回收垃圾进程。
- WAL writer:定期将WAL缓冲区上的 WAL数据写入磁盘。
- statistics collector:统计信息收集进程。
- logging collector:日志进程,将消息或错误信息写入日志。
- archiver :WAL归档进程。
- checkpointer:检查点进程。

3 内存结构
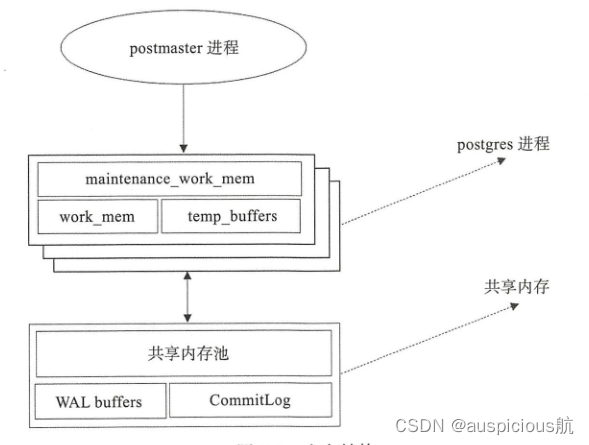
PostgreSQL的内存分为两大类:本地内存和共享内存,另外还有一些为辅助进程分配的内存等,下面简单介绍本地内存和共享内存的概貌。
3.1 本地内存
本地内存由每个后端服务进程分配以供自己使用,当后端服务进程被fork 时,每个后端进程为查询分配一个本地内存区域。本地内存由三部分组成: work_mem、maintenance_work_mem和 temp_buffers。
work _mem:当使用ORDER BY或DISTINCT操作对元组进行排序时会使用这部分内存。maintenance_work_mem:维护操作,例如VACUUM、REINDEX、CREATE INDEX
等操作使用这部分内存。
temp_buffers :临时表相关操作使用这部分内存。
3.2 共享内存
共享内存在PostgreSQL服务器启动时分配,由所有后端进程共同使用。共享内存主要由三部分组成:
- shared buffer pool :PostgreSQL将表和索引中的页面从持久存储装载到这里,并直
- 接操作它们。
- WAL buffer:WAL文件持久化之前的缓冲区。
- CommitLog buffer :PostgreSQL在 Commit Log 中保存事务的状态,并将这些状态保留在共享内存缓冲区中,在整个事务处理过程中使用。